In this article we talk about MySQL optimization methods commonly used in the project, a total of 19, as follows:
1, EXPLAIN command to do MySQL optimization, we want to make good use of EXPLAIN view SQL execution plan. Let's a simple example, labeling (1,2,3,4,5) data we need to focus on:

- type column, the type of connection. A good SQL statement to reach at least the level range. Prevent the emergence of all levels.
- The key column, use the name of the index. If you do not select an index, the value is NULL. It may take enforcement indexing.
- key_len column index length.
- rows columns, the number of scanning lines. This value is an estimate.
- extra columns detail. Note that common values are less friendly, as follows: Using filesort, Using temporary.
2, the value of the IN SQL statement should not contain too many MySQL for IN made the corresponding optimized, coming IN the constants are all stored in an array inside, and the array is sorted. However, if the value is more, consume generated is relatively large. Another example: select id from t where num in (1,2,3) for successive values, can not use in the between; used to replace or re-connected.
3, SELECT statement is sure to specify the name of the field SELECT * add a lot of unnecessary consumption (CPU, IO, memory, network bandwidth); increases the likelihood of the use of covering indexes; when the table structure changes, also need to be updated before the break. So I requested directly connected to the back of the field names in the select.
4, when only a required data using limit 1 This is to achieve the type column EXPLAIN const type
5, if the sort field is not used in the index, as little as possible to sort
6, if restrictions in other fields are not indexed, minimize the use of or or both sides of the field, if there is not a field index, while other conditions are not indexed field, the situation will cause the query does not go indexes. Many times using union all or union (when necessary) way to replace "or" will get better results.
7, try to use union all in place of Union of Union and union all major difference is that the former requires the collection of the results and then uniqueness of the filtering operation, which will involve sorting, increase the number of CPU operations, increase resource consumption and latency. Of course, with the proviso that two union all the result data set is not repeated.
8, without using ORDER BY RAND ()
select id from `dynamic` order by rand() limit 1000;SQL statement above, can be optimized for:
select id from `dynamic` t1 join (select rand() * (select max(id) from `dynamic`) as nid) t2 on t1.id > t2.nidlimit 1000;9, the distinction between in and exists, not in and not exists
select * from 表A where id in (select id from 表B)SQL statement is equivalent to the above
select * from 表A where exists(select * from 表B where 表B.id=表A.id)Distinction exists mainly in and caused the driver to change the order (which is the key performance variations), if it exists, then the outside layer of table-driven table is accessed first, if it is IN, it runs the subquery. IN adapted so large and small outer inner case; EXISTS adapted to the outer case of the small and large table. About not in and not exists, we recommended not exists, not only efficiency, not in logic there may be a problem. How efficient alternative not exists write a SQL statement? Original SQL statement:
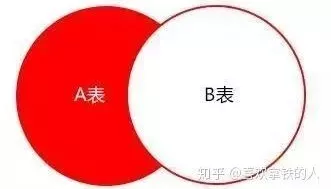
select colname … from A表 where a.id not in (select b.id from B表)Efficient SQL statement:
select colname … from A表 Left join B表 on where a.id = b.id where b.id is nullRemove the result set as shown below indicates, A table is not the data in Table B:
10, the use of reasonable methods to increase the efficiency of pagination pagination
select id,name from product limit 866613, 20When using the SQL statement to do paging, some people may find that, with the increasing amount of table data, use direct query page limit will become slower. Optimization method is as follows: id may be taken before a maximum number of rows, and the next start point is limited based on this maximum id. So the column than the largest previous id is 866612. SQL can be written as follows:
select id,name from product where id> 866612 limit 2011、分段查询在一些用户选择页面中,可能一些用户选择的时间范围过大,造成查询缓慢。主要的原因是扫描行数过多。这个时候可以通过程序,分段进行查询,循环遍历,将结果合并处理进行展示。如下图这个SQL语句,扫描的行数成百万级以上的时候就可以使用分段查询:

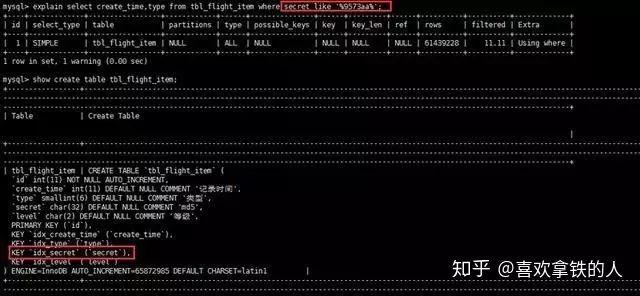
12、避免在where子句中对字段进行null值判断对于null的判断会导致引擎放弃使用索引而进行全表扫描。13、不建议使用%前缀模糊查询例如LIKE“%name”或者LIKE“%name%”,这种查询会导致索引失效而进行全表扫描。但是可以使用LIKE “name%”。那如何查询%name%?如下图所示,虽然给secret字段添加了索引,但在explain结果并没有使用:
那么如何解决这个问题呢,答案:使用全文索引。在我们查询中经常会用到select id,fnum,fdst from dynamic_201606 where user_name like '%zhangsan%'; 。这样的语句,普通索引是无法满足查询需求的。庆幸的是在MySQL中,有全文索引来帮助我们。创建全文索引的SQL语法是:
ALTER TABLE `dynamic_201606` ADD FULLTEXT INDEX `idx_user_name` (`user_name`);使用全文索引的SQL语句是:
select id,fnum,fdst from dynamic_201606 where match(user_name) against('zhangsan' in boolean mode);注意:在需要创建全文索引之前,请联系DBA确定能否创建。同时需要注意的是查询语句的写法与普通索引的区别。
14、避免在where子句中对字段进行表达式操作比如:
select user_id,user_project from user_base where age*2=36;中对字段就行了算术运算,这会造成引擎放弃使用索引,建议改成:
select user_id,user_project from user_base where age=36/2;15、避免隐式类型转换where子句中出现column字段的类型和传入的参数类型不一致的时候发生的类型转换,建议先确定where中的参数类型。
16、对于联合索引来说,要遵守最左前缀法则举列来说索引含有字段id、name、school,可以直接用id字段,也可以id、name这样的顺序,但是name;school都无法使用这个索引。所以在创建联合索引的时候一定要注意索引字段顺序,常用的查询字段放在最前面。
17、必要时可以使用force index来强制查询走某个索引有的时候MySQL优化器采取它认为合适的索引来检索SQL语句,但是可能它所采用的索引并不是我们想要的。这时就可以采用forceindex来强制优化器使用我们制定的索引。
18、注意范围查询语句对于联合索引来说,如果存在范围查询,比如between、>、<等条件时,会造成后面的索引字段失效。
19、关于JOIN优化:
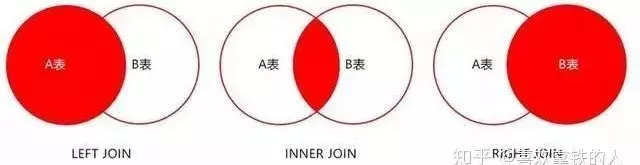
LEFT JOIN A表为驱动表,INNER JOIN MySQL会自动找出那个数据少的表作用驱动表,RIGHT JOIN B表为驱动表。
注意:
1)MySQL中没有full join,可以用以下方式来解决:
select * from A left join B on B.name = A.namewhere B.name is nullunion allselect * from B;2)尽量使用inner join,避免left join:参与联合查询的表至少为2张表,一般都存在大小之分。如果连接方式是inner join,在没有其他过滤条件的情况下MySQL会自动选择小表作为驱动表,但是left join在驱动表的选择上遵循的是左边驱动右边的原则,即left join左边的表名为驱动表。
3)合理利用索引:被驱动表的索引字段作为on的限制字段。
4)利用小表去驱动大表:
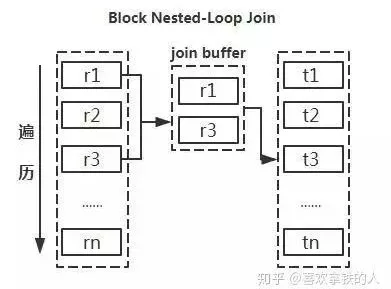
从原理图能够直观的看出如果能够减少驱动表的话,减少嵌套循环中的循环次数,以减少 IO总量及CPU运算的次数。
5)巧用STRAIGHT_JOIN:inner join是由MySQL选择驱动表,但是有些特殊情况需要选择另个表作为驱动表,比如有group by、order by等「Using filesort」、「Using temporary」时。STRAIGHT_JOIN来强制连接顺序,在STRAIGHT_JOIN左边的表名就是驱动表,右边则是被驱动表。在使用STRAIGHT_JOIN有个前提条件是该查询是内连接,也就是inner join。其他链接不推荐使用STRAIGHT_JOIN,否则可能造成查询结果不准确。
