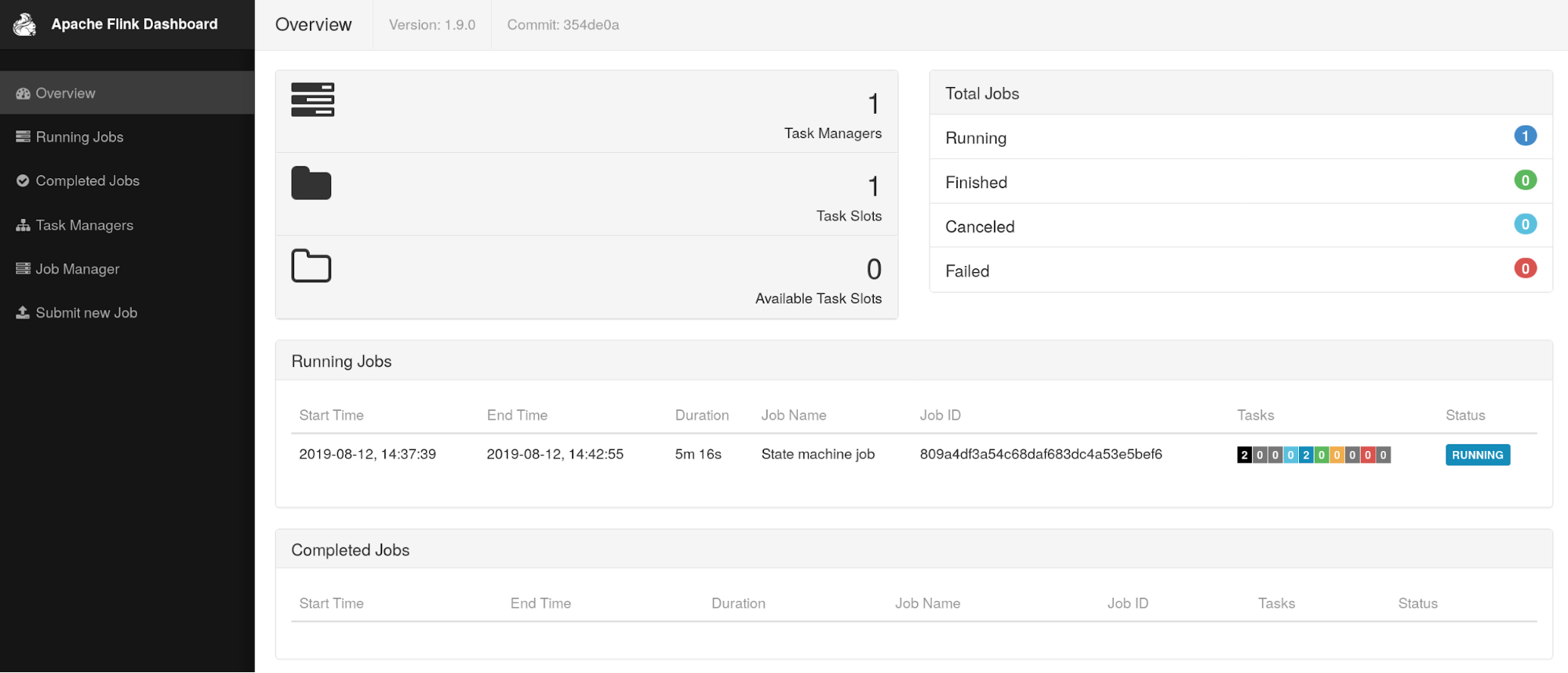
Apache Flink 1.9.0 has been released, Apache Flink goal of the project is to develop a stream processing system to unify and support various forms of real-time and off-line data processing applications, and event-driven applications.
This release includes batch job batch type recovery, and the new table based on the preview flashing API and SQL query engine, as well as the availability of state of the processor API, which is one of the most commonly requested feature that allows users to use Flink DataSet read and write operations to save points. Finally, including the WebUI and the new Python Table API preview Flink a redesigned and its integration with Apache Hive ecosystems.
TableAPI & SQL
The split module Table (FLIP-32, FLIP i.e. Flink Improvement Proposals, which tracks the number of proposals to modify the Flink made larger), and to the Java API to Scala dependent carded, and proposes to support a plurality of different interfaces Planner the Planner implementation. Planner will be responsible for specific optimization and will translate into job Table executes the work, we can achieve all of the original move to Flink Planner, and then the docking of the new architecture code on Blink Planner years.
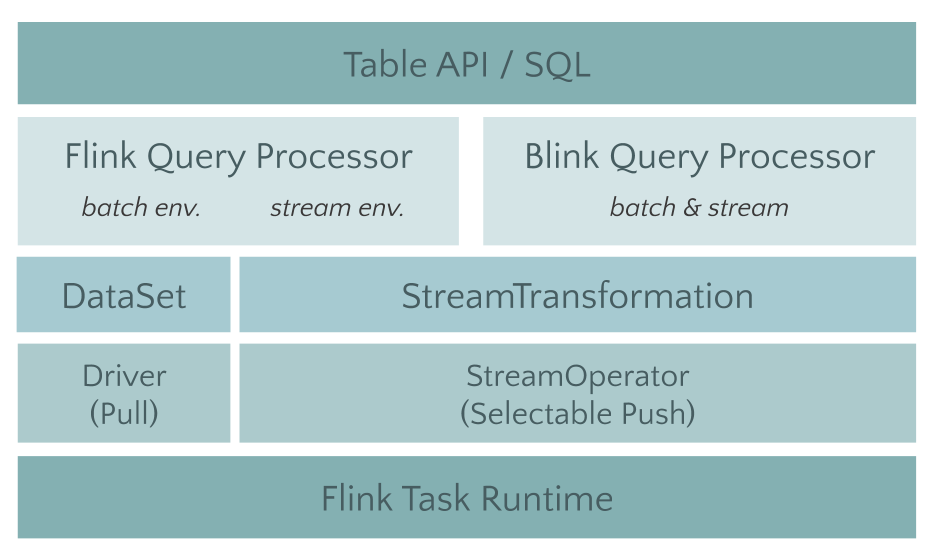
Table module not only make more clear after the split, more importantly, does not affect older versions of the user's experience. In the 1.9 version, has most of the original open-source merge out of the Blink SQL function.
In addition to infrastructure upgrades, Table module in version 1.9 also made a few relatively large remodeling and new features, including:
-
FLIP-37: Table API type system Reconstruction
-
FLIP-29: Table rows and columns for increased operation API
-
FLINK-10232: Preliminary SQL DDL support
-
FLIP-30: The new Unified Catalog API
-
FLIP-38: Table API Python version increase
Improved batch processing
Flink的批处理功能在 1.9 版本有了重大进步,首当其冲的是优化批处理的错误恢复代价:FLIP-1(Fine Grained Recovery from Task Failures),从这个 FLIP 的编号就可以看出,该优化其实很早就已经提出,1.9 版本终于有机会将 FLIP-1 中未完成的功能进行了收尾。
在新版本中,如果批处理作业有错误发生,那么 Flink 首先会去计算这个错误的影响范围,即 Failover Region。因为在批处理作业中,有些节点之间可以通过网络进行Pipeline 的数据传输,但其他一些节点可以通过 Blocking 的方式先把输出数据存下来,然后下游再去读取存储的数据的方式进行数据传输。
如果算子输出的数据已经完整的进行了保存,那么就没有必要把这个算子拉起重跑,这样一来就可以把错误恢复控制在一个相对较小的范围里。
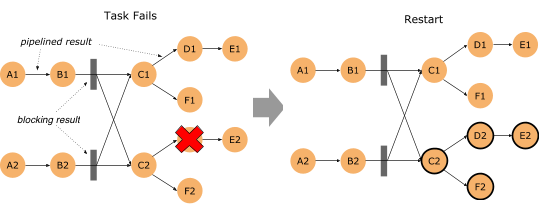
如果作业极端一点,在每一个需要Shuffle 的地方都进行数据落盘,那么就和 MapReduce 以及 Spark 的行为类似了。只是 Flink 支持更高级的用法,你可以自行控制每种 Shuffle 是使用网络来直连,还是通过文件落盘来进行。
流处理改进
这个版本增加了一个非常实用的功能,即 FLIP-43(State Processor API)。Flink 的 State 数据的访问,以及由 State 数据组成的 Savepoint 的访问一直是社区用户呼声比较高的一个功能。
这次的 State Processor API 则提供了更加灵活的访问手段,也能够让用户完成一些比较黑科技的功能:
-
用户可以使用这个 API 事先从其他外部系统读取数据,把它们转存为 Flink Savepoint 的格式,然后让 Flink 作业从这个 Savepoint 启动。这样一来,就能避免很多冷启动的问题。
-
使用 Flink 的批处理 API 直接分析State 的数据。State 数据一直以来对用户是个黑盒,这里面存储的数据是对是错,是否有异常,用户都无从而知。有了这个 API 之后,用户就可以像分析其他数据一样,来对 State 数据进行分析。
-
脏数据订正。假如有一条脏数据污染了你的 State,用户还可以使用这个 API 对这样的问题进行修复和订正。
-
状态迁移。当用户修改了作业逻辑,想复用大部分原来作业的 State,但又希望做一些微调。那么就可以使用这个 API 来完成相应的工作。
Hive 集成
在 1.9 版本中,通过 FLIP-30 提出的统一的 Catalog API 的帮助,目前 Flink 已经完整打通了对 Hive Meta Store 的访问。同时,也增加了 Hive 的 Connector,目前已支持 CSV, Sequence File, Orc, Parquet 等格式。用户只需要配置 HMS 的访问方式,就可以使用 Flink 直接读取 Hive 的表进行操作。在此基础之上,Flink 还增加了对 Hive 自定义函数的兼容,像 UDF, UDTF和 UDAF,都可以直接运行在Flink SQL里。
Flink WebUI 修改
组件使用了最新的稳定版本的 Angular。