The first 2 chapters RDD program
2 .1 programming model
In Spark In, RDD is represented as an object, the method calls for an object by RDD conversion. After a series of transformations defined RDD After that, you can invoke actions triggered RDD calculations, Action can return results to the application (count, collect , etc. ) , or save the data to the storage system (saveAsTextFile , etc. ) . In Spark , only encountered Action , performed only RDD calculations ( i.e., delay calculation ) , this conversion may be transmitted by way of a plurality of pipe at runtime.
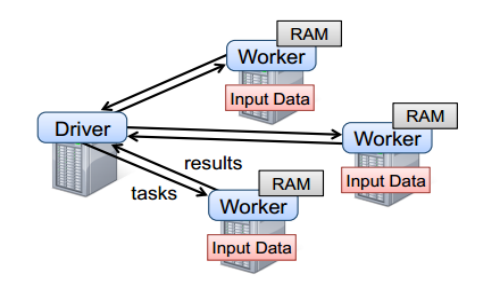
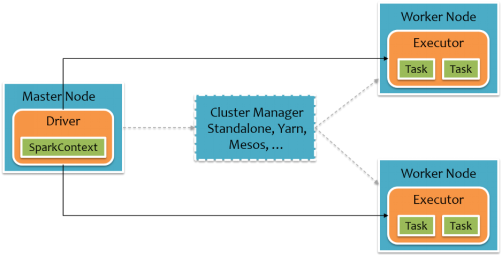
To use the Spark , developers need to write a Driver program, which is submitted to the operation of the cluster to schedule the Worker , as shown in FIG. Driver defines one or more RDD , and calls RDD on Action , Worker perform the RDD partitioned computing tasks.
2 .2 RDD create
In Spark creation RDD to create them can be divided into three types: creation from the collection RDD ; created from external storage RDD ; from other RDD created.
Of an existing Scala set creation, collection parallelization.
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
Created from the collection RDD , the Spark mainly provides two functions: Parallelize and makeRDD . We can look at the statements of these two functions:
def parallelize[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] def makeRDD[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T]
We can see from the above makeRDD implemented in two, and the first makeRDD function of the received parameters and parallelize identical. In fact, the first makeRDD function implementation is dependent on the parallelize function of the realization, take a look at Spark is how to achieve this makeRDD function:
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
We can see that this makeRDD function fully and parallelize function the same. But we have to look at the second makeRDD function function implementation, and it receives the parameter type is Seq [(T, Seq [String])] , the Spark documentation are:
Distribute a local Scala collection to form an RDD, with one or more location preferences (hostnames of Spark nodes) for each object. Create a new partition for each collection item.
Originally, this function also provides data location information, take a look at how we use:
scala> val guigu1= sc.parallelize(List(1,2,3))
guigu1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at <console>:21
scala> val guigu2 = sc.makeRDD(List(1,2,3))
guigu2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at makeRDD at <console>:21
scala> val seq = List((1, List("slave01")),| (2, List("slave02")))
seq: List[(Int, List[String])] = List((1,List(slave01)),
(2,List(slave02)))
scala> val guigu3 = sc.makeRDD(seq)
guigu3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at makeRDD at <console>:23
scala> guigu3.preferredLocations(guigu3.partitions(1))
res26: Seq[String] = List(slave02)
scala> guigu3.preferredLocations(guigu3.partitions(0))
res27: Seq[String] = List(slave01)
scala> guigu1.preferredLocations(guigu1.partitions(0))
res28: Seq[String] = List()
We can see, makeRDD function implemented in two, in fact, the first implementation and parallelize the same; and second implementation can provide location information for the data, and in addition to the implementation and parallelize function is the same, as follows:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {
assertNotStopped()
val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap
new ParallelCollectionRDD[T](this, seq.map(_._1), seq.size, indexToPrefs)
}
They are returned ParallelCollectionRDD , and this makeRDD realization of their own can not specify the number of partitions, but fixed seq parameter of size size.
Created by an external set of data storage systems, including the local file system, as well as all Hadoop supported data sets, such as HDFS , Cassandra , HBase , etc.
scala> val atguigu = sc.textFile("hdfs://hadoop102:9000/RELEASE")
atguigu: org.apache.spark.rdd.RDD[String] = hdfs:// hadoop102:9000/RELEASE MapPartitionsRDD[4] at textFile at <console>:24