View file encoding
to view files in Linux can be encoded by the following ways:
1. Vim can directly view the file encoding
: set fileencoding
to display the file encoding format.
If you just want to view files in other formats or want to solve coding see garbled file with Vim problem, then you can
add the following to ~ / .vimrc file:
set encoding=utf-8 fileencodings=ucs-bom,utf-8,cp936
In this way, you can make vim automatically recognize the file encoding (automatically recognizes UTF-8 or GBK encoded files), in fact, in accordance with the coding list attempts fileencodings provided, if no suitable coding found, with (ASCII) coding latin-1 turn on.
2. enca (If this command is not installed on your system, you can use sudo yum install -y enca installation) to view the file encoding
$ filename ENCA
filename: Universal Transformation format 8 bits; UTF-8
CRLF Line terminators
should be noted that it is important, enca file identified some GBK encoding is not very good, when there will be recognition:
Unrecognized encoding
Transcoding file
1. In Vim file encoding direct conversion, such as converting a file into a utf-8 format
: set fileencoding = utf-8
2. enconv conversion file encoding, such as a To GBK encoded files into UTF-8 encoding, as follows
enconv -L zh_CN -x UTF-8 filename
3. iconv conversion, iconv command format is as follows:
iconv -f encoding -t encoding inputfile
such as for converting a UTF-8 encoded file into GBK encoding
iconv -f GBK -t UTF-8 file1 -o file2
This article addresses: http://www.yaronspace.cn/blog/index.php/archives/523
Garbled reasons:
because your file is declared as utf-8, and it should be saved with the utf-8 encoding of the source file. But local windows default encoding is cp936, that is gbk coding, so the console
Direct Print utf-8 string is of course the distortion.
Solution:
In the console where printed using a transcoding ok, so when printing write:
. Print myname.decode ( 'UTF-8') encode ( 'GBK')
the more common approach would be:
Import SYS
= sys.getfilesystemencoding type ()
Print myname.decode ( 'UTF-. 8'). encode (type)
Recent use python grab some online data, we encountered problems coding. Headache, summarize the solution used.
- View file encoding in vim under linux command set fileencoding
- python code detection in a strong package chardet, very simple to use. Simple installation using the linux pip install chardet
|
1
2
3
4
|
import
chardet
f
=
open
(
'file'
,
'r'
)
fencoding
=
chardet.detect(f.read())
print
fencoding
|
fencoding output format { 'confidence': 0.96630842899499614, 'encoding': 'GB2312'}, the probability is determined only whether a certain code. More accurate result. Str type input parameters.
- After encoding can learn the python str achieved using encoding conversion decode and encode.
It is a general flow str str coding method using the decode decodes it into unicode string type, then the use of specific encoding according to encode the particular coding unicode string type to convert. str unicode in python and belonging to two different types, as follows.
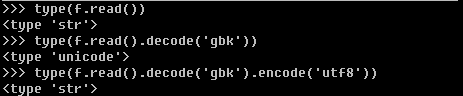
- window default encoding gbk Generally, linux default encoding utf8
- python programming coding system, the concept of python code, file encoding.
System Code: the default encoding editor to write source code. It represents all of the content within the source files are encoded into binary code stream according to the word way. Stored to disk. View by locale command under linux.
python coding: decoding means provided in the python. If not set, then, python default is ascii decoding mode. If the Chinese do not appear python source code file, then this place is how the set should not be a problem.
Setting method: at the beginning of the source file (it must be the first line): # - * - coding: UTF-8 - * -, provided the source file decoding scheme is UTF-8, or
|
1
2
3
|
import
sys
reload
(sys)
sys.setdefaultencoding(
'UTF-8'
)
|
File encoding: the encoding of the text, under linux vim use set fileencoding view.
- The reason the output distortion is not generally encoded to the system decoder manner.
For example print s, s type str, linux system is the system default encoding utf8 encoding, s before the output should be encoded as utf8. If s is gbk coding should thus output. print s.decode ( 'gbk'). encode ( 'utf8') to output Chinese.
Following the same window case, window default encoding is gbk encoding, it must be encoded before gbk s output.
- python unicode general processing process type. Thus before encoding can be directly output.
Turn 1. http://blog.sina.com.cn/s/blog_40e1ba640102wm26.html
2.http: //www.cnblogs.com/joeyupdo/archive/2013/03/03/2941737.html
The following is a copy of the link 2 described in
(1) encoding: the character encoding used inside Vim, including the Buffer Vim (buffer), menu text, text messages and the like. Recommended that the user manual is only to change its value in .vimrc, in fact, it seems to have changed its value only makes sense in your .vimrc
(2) fileencoding: Vim editor in the current character encoding of the file, when Vim save files will also save the file as this character encoding (whether new documents are true), the Internet is introduced, but I do it defined as .vimrc in utf-8 seems to have no effect, can only be set manually will take effect when you open the file vim, I do not know why.
(3) fileencodings: it will follow the character encoding listed one by one to detect the character encoding of the file will open Vim starts, and fileencoding set as the final detected character encoding. So it is best to Unicode encoding into the top of the list, the Latin latin1 encoding into the final surface.
(4) termencoding: Vim end of the work (or the Console window Windows) character encoding. This option gVim our common GUI mode is not available under Windows, but in terms of Vim Console mode Console is a Windows code page, and usually we do not need to change it.
The system locale is utf-8 (a lot of linux system default locale form), edited document is in the form of GB2312 or GBK (Windows Notepad
default storage format, most editors is also saved as the default form, so the most common), terminal type utf-8 (i.e. assume that the client software is a putty like unicode)
the document open vim, encoding = utf-8 (locale determined), fileencoding = latin1 (autoencoder caused by inaccurate determination mechanism), termencoding = empty (without conversion term default encoding), the file is displayed as garbled.
Solution 1: First, to amend fileencoding is cp936 or euc-cn (like both, but different names), note that the method is not corrected: the SET
fileencoding = cp936, it's just save the file as cp936, the correct way is reload to cp936 encoding file as: Edit
++ = ENC cp936, can be abbreviated as: e ++ enc = cp936.
But to do so, re-open, again, set it again after the file is closed. The reason is garbled in the final analysis vim does not recognize the file encoding, resulting in not properly decode (decoding do not know whether to call, I understand). So, I set in .vimrc in the fileencodings, the equivalent of telling vim when unsuccessful so in several ways to try to decode the file utf-8, set fileencoding = utf-8 set fileencodings = ucs-bom, utf-8, cp936 , latin1. this opens normal
Garbled reasons:
because your file is declared as utf-8, and it should be saved with the utf-8 encoding of the source file. But local windows default encoding is cp936, that is gbk coding, so the console
Direct Print utf-8 string is of course the distortion.
Solution:
In the console where printed using a transcoding ok, so when printing write:
. Print myname.decode ( 'UTF-8') encode ( 'GBK')
the more common approach would be:
Import SYS
= sys.getfilesystemencoding type ()
Print myname.decode ( 'UTF-. 8'). encode (type)
Recent use python grab some online data, we encountered problems coding. Headache, summarize the solution used.
- View file encoding in vim under linux command set fileencoding
- python code detection in a strong package chardet, very simple to use. Simple installation using the linux pip install chardet
|
1
2
3
4
|
import
chardet
f
=
open
(
'file'
,
'r'
)
fencoding
=
chardet.detect(f.read())
print
fencoding
|
fencoding output format { 'confidence': 0.96630842899499614, 'encoding': 'GB2312'}, the probability is determined only whether a certain code. More accurate result. Str type input parameters.
- After encoding can learn the python str achieved using encoding conversion decode and encode.
It is a general flow str str coding method using the decode decodes it into unicode string type, then the use of specific encoding according to encode the particular coding unicode string type to convert. str unicode in python and belonging to two different types, as follows.
- window default encoding gbk Generally, linux default encoding utf8
- python programming coding system, the concept of python code, file encoding.
System Code: the default encoding editor to write source code. It represents all of the content within the source files are encoded into binary code stream according to the word way. Stored to disk. View by locale command under linux.
python coding: decoding means provided in the python. If not set, then, python default is ascii decoding mode. If the Chinese do not appear python source code file, then this place is how the set should not be a problem.
Setting method: at the beginning of the source file (it must be the first line): # - * - coding: UTF-8 - * -, provided the source file decoding scheme is UTF-8, or
|
1
2
3
|
import
sys
reload
(sys)
sys.setdefaultencoding(
'UTF-8'
)
|
File encoding: the encoding of the text, under linux vim use set fileencoding view.
- The reason the output distortion is not generally encoded to the system decoder manner.
For example print s, s type str, linux system is the system default encoding utf8 encoding, s before the output should be encoded as utf8. If s is gbk coding should thus output. print s.decode ( 'gbk'). encode ( 'utf8') to output Chinese.
Following the same window case, window default encoding is gbk encoding, it must be encoded before gbk s output.
- python unicode general processing process type. Thus before encoding can be directly output.