Welcome to follow the blogger python old bird or go to " Python Self-study Network ", starting from the basic introductory free course, and gradually learning the python full-stack system course, suitable for beginners to master full-stack development.
Free Column Portal: " Python Basic Tutorial "
The content stored in the text file is a file based on character encoding. Common encodings include ASCII, UNICODE, etc.
- Python2.x uses ASCII encoding by default
- Python3.x uses UTF-8 encoding by default
1. ASCII encoding and UNICODE encoding
1.1 "ASCII code
ASCII encoding can be said to be the oldest encoding, because the computer was first invented by Americans, and Americans formulated ASCII encoding in order to use their own English in computers.
- There are only 256 ASCII characters in a computer
- An ASCII takes up one byte of space in memory
- There are a total of 256 combinations of 8 0/1, that is, 2**8
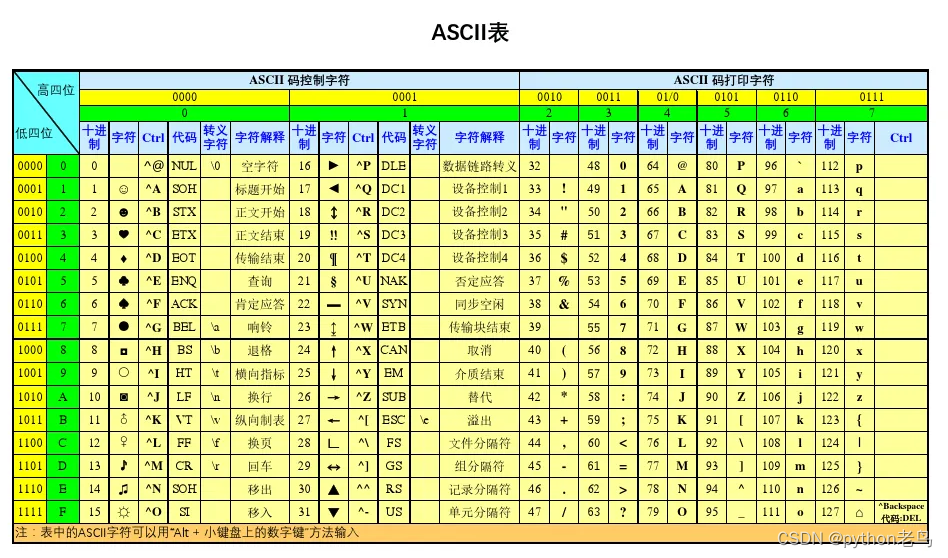
The ASCCI code has only 256 characters. Although it can cover 26 English characters, there are tens of thousands of characters in Chinese. The ASCII code cannot satisfy us, so the UNICODE code was born.
1.2 "UNICODE encoding
UTF-8 encoding format:
- UTF-8 is an encoding format of UNICODE encoding
- Computers use 1~6 bytes to represent a UTF-8 character, covering almost all texts in the world
- Most Hanzi will use 3 bytes to represent
2. How to use Chinese in Python2.x
1. Add the following code to the first line of the python2.x file, and the interpreter will process the Python file in UTF-8 encoding
# *-* coding:utf8 *-*Tip: This method is officially recommended.
2. It can also be like this, there should be no spaces on both sides of the = sign
# coding=utf8question:
In python2.x, even if the file is specified to use the UTF-8 encoding format, when traversing the string, the string will still be traversed in bytes
answer:
To be able to traverse the string correctly, when defining the string, you need to add a lowercase letter u before the leading of the string to tell the interpreter that this is a unicode string (it is a string that uses UTF-8 encoding)
Code: This code will have many symbols in python2.x
str = u"Python自学网"
for a in str:
print(a)Code optimization: add u
# 引号前面的u告诉解释器这事一个utf-8编码格式的字符串
str = u"Python自学网"
for a in str:
print(a)3. What if the Chinese in the file cannot be read in Python3.x?
Python3.X source files use utf-8 encoding by default, so Chinese can be parsed normally without specifying UTF-8 encoding.
python3 to view the default encoding:
Module: python3 sys.getdefaultencoding().py
Function: Get the system default encoding method
code:
import sys
print(sys.getdefaultencoding())Result: utf-8
What if the Chinese in the file cannot be read in Python3.x?
Solution: Write encoding= ” UTF-8 ”
For example:
file = open("HELLO", encoding="UTF-8")