Andrew Ng machine learning notes --- By Orangestar
Week_7
This week, you will be learning about the support vector machine (SVM) algorithm. SVMs are considered by many to be the most powerful 'black box' learning algorithm, and by posing a cleverly-chosen optimization objective, one of the most widely used learning algorithms today.
1. Optimization Objective
More powerful methods: SVM SVM (support vectors machine)
First, we need to start from the optimization.
SVM (Support vector machine) is commonly used in machine learning (Machine learning). Method is a supervised learning (Supervised Learning), mainly used in the statistical classification (Classification) issues and regression analysis (Regression) problem. SVM wherein the cost function is as follows:
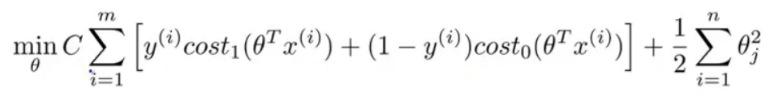
The cost function is varied over a logistic regression, simply multiply the FIG Meanwhile m, λ can be obtained by dividing the SVM cost function. That function is lost in the form of SVM CA + B, Logic regression and loss function is + A \ (\ the lambda \) B
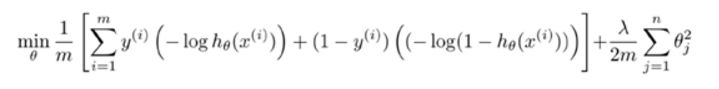
Which are summarized as follows:

Another problem is to give greater weight first or second term weight can be selected regular item in different ways
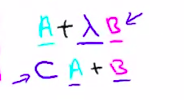
2. Large Margin Intuition
Now our cost function changes, so we want to also change slightly:

Of course, for regularization term:

In this way we will get a very interesting decision limit
注意观察图像,黑色是最好的一条决策界限
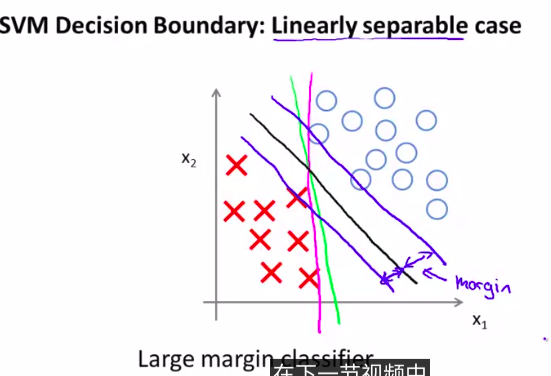
所以,支持向量机也可以叫做大间距分类器
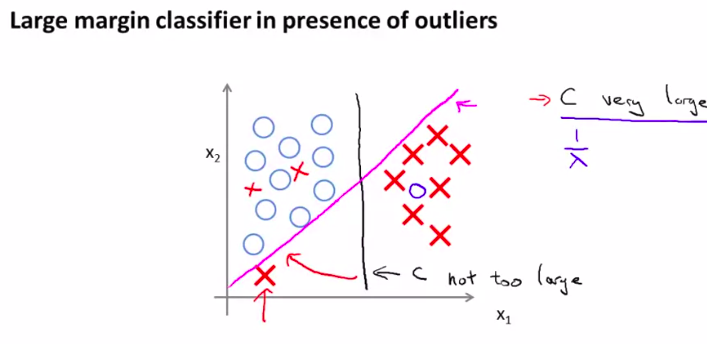
所以。正则化参数C的设置是非常关键的。如何处理这种参数的平衡?且听下回分解。
× 3. Mathematics Behind Large Margin Classification(optional)
为什么这样的代价函数就可以得到这样的大间距分类器,即支持向量机?
首先,我们先回顾一下向量内积的知识
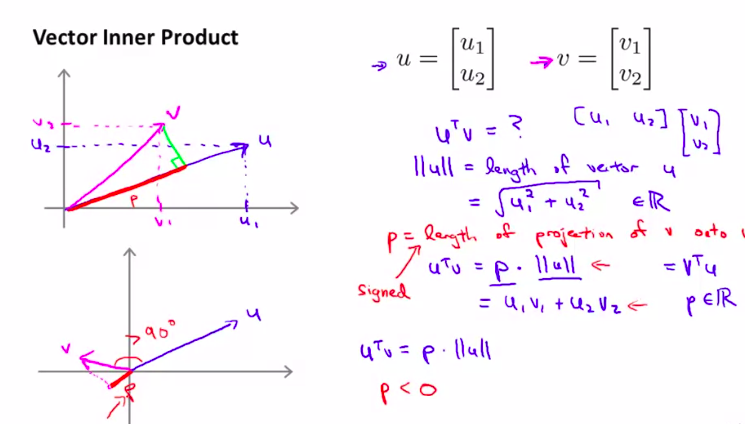
超级简单的回顾一哈。

然后,可以观察前面的项和正则化项的联系,通过向量的定义!
我们先简化计算,把\(\theta_0\)当做0来处理
为什么不会选择黄色线?
仔细想想向量点积的几何意义!如果这样的话,就会非常小!意思是\(\theta\)的范数会十分大!
然后对比一下右图的绿色线!
这样P和\(\theta\)相乘就变大了!!!
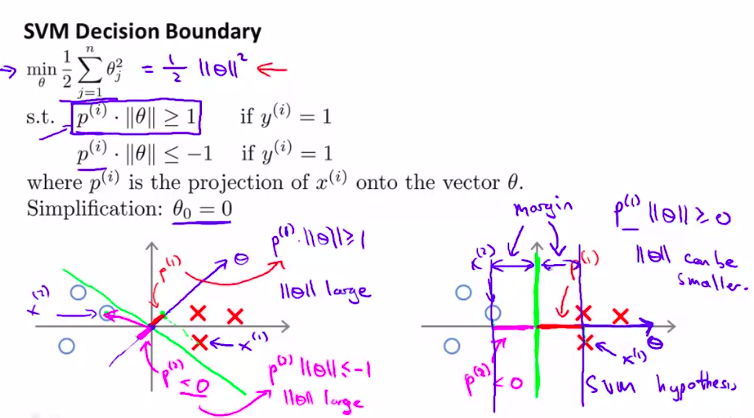
这样就得到了一个大间距分类器
(找到了一个\(\theta\)较小的范数)
当然,\(\theta_0\)也可以不为0.
但是无论如何,都会优化这个函数
4. Kernels I
构造浮躁的非线性分类器
使用kernels
核函数(也叫高斯核函数)
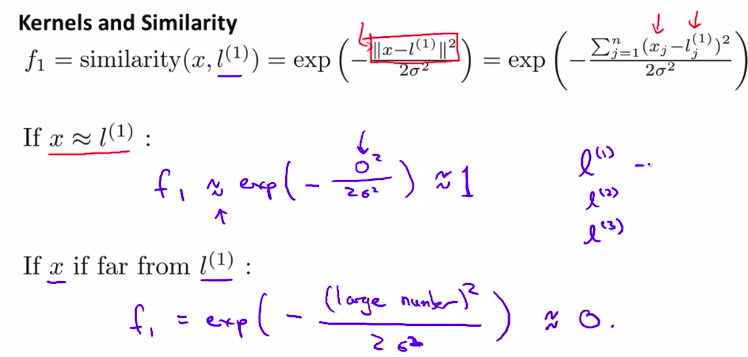
这是 相似度函数
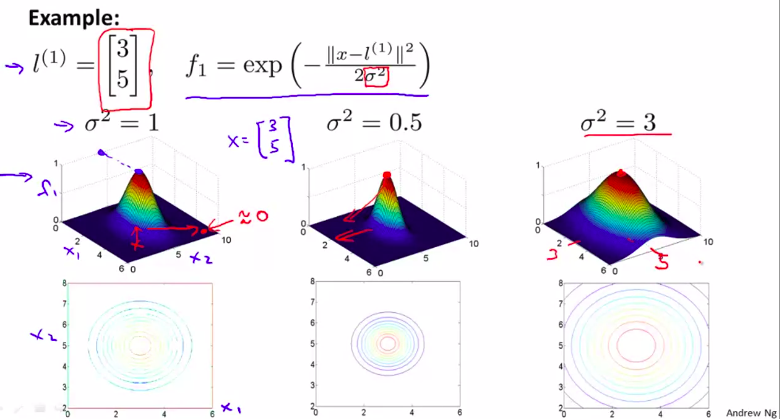
注意观察,当x越靠近l 的时候,函数值越接近于 0 。然后随着 \(\delta\)的变大,越大的话图像越胖,但是最高高度不变

所以,由这张图,思考一下,为什么这样可以表示多变量的分类器?
有3个点,越接近一个点,其对应的值越接近1 。越远离, 其对应的值越接近于 0-
这就是如何用核函数来实现复杂的非线性分类器!!
但是,仍有一些不懂的,其中一个是 我们如何得到这些标记点 我们怎么来选择这些标记点 另一个是 其他的相似度方程是什么样的 如果有其他的话 我们能够用其他的相似度方程 来代替我们所讲的这个高斯核函数吗
5. Kernels II 核函数进一步!
上节课回顾:

实际应用的时候,如何选择标记点?
只需要直接将训练样本当做标记点!
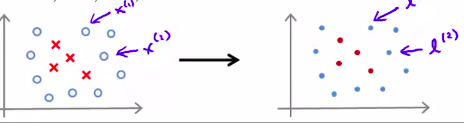
所以,下面是如何应用:
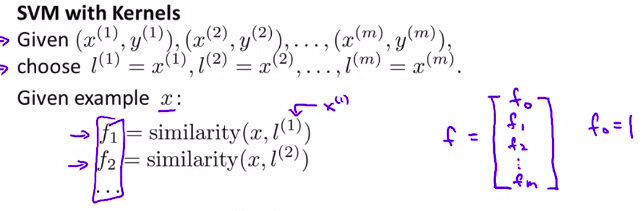
以上就是步骤。
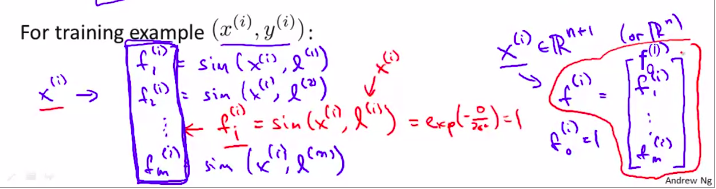
当然,这个f完全可以向量化。
如何具体操作?很简单!
只需要将hy函数替换一下

注:此时,仍然不用对 0 作正则化处理
正则项可以这样写:

一点的数学小细节
这样可以让支持向量机更高效的运行。因为这样可以适应超大量的训练集
再有一点,如何选择支持向量机中的参数?(2个参数)

如何进行方差和偏差折中?

总结的话,\(\delta\)变小,函数变化的越剧烈,导数越大。导致出现高方差,也就是over-fitting. 过拟合
变大的话,就是under-fitting欠拟合
6. 实际例子
一般计算参数\(\theta\)不需要自己写算法来实现,因为已经有高效实现的软件库。 但是,我们仍需要做一些事情:

For example: linear kernel, Gaussian kernel and the like.

When linear classifiers (linear kernel):
a large number of feature quantity, little training set.
When using a Gaussian kernel?
Wherein less complex, non-linear
When using matlab implementation:
with the Gaussian kernel when different feature amounts must remember that normalization

Because the gap between the different characteristic quantities can be very large! !
Note: some other kernel kernals

Finally two details:
Multi-classification problem
of how to make the appropriate output SVM decision boundary between the various categories?

First, using built-in functions, the software library in
two, with many methods, one vs all
Using logistic regression or vector machine?

Note: logistic regression and linear kernel function is very similar, but there are different algorithms
for neural networks:
