Micro Services Architecture - avalanche
Micro-service product line, each service to concentrate on its own business logic, and provide the external interface seems very clear, in fact, there are many things to consider, such as: automatic expansion of services, and current limiting fuse with the expansion of business, the number of services will increase, and will be more complex logic, a logic of a service need to rely on a number of other services to complete. Once a dependency can not provide the service is likely to produce 雪崩效应, leading to the entire service inaccessible.
Carried out between micro service rpcor httpwhen you call, we will generally set up 调用超时, 失败重试such as mechanisms to ensure the successful implementation of the service, looks beautiful, if you do not consider the services of fusing and current limiting, is the source of an avalanche.
Suppose we have two to access a greater amount of service A and B, respectively, dependent on both services C and D, C and D are dependent services Service E
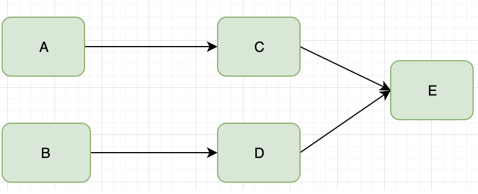
A and B continue to call C, D handle customer requests and return the data needed. When E service can not provide services, C and D 超时and 重试mechanisms will be executed

Due to constantly generate new calls, will lead to a large number of calls to the backlog C and D E services, a large number of calls waiting and retry the call, it will slowly run out of resources C and D such as memory or CPU, and then also down out.
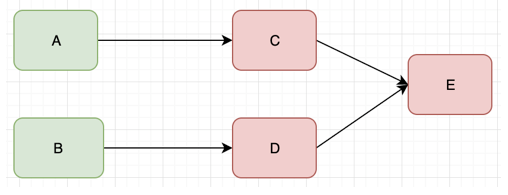
A and B, C and D will be repeated service operations, resource depletion, and then fall down, eventually the whole services are inaccessible.
Common cause avalanche situation are the following:
- Program bug causes the service is not available or is slow
- Cache breakdown, leading to full access to a service call, leading to fall down
- The sudden surge in traffic.
- Hardware problem, this feeling can only say that points back of ⊙︿⊙.
Although the avalanche effect of 10 million, to ensure that services do not hang up and running smoothly is our responsibility, the corresponding avalanche effect there are still many protection schemes.
The lateral expansion of services
现在我们可以利用很多工具来保证服务不会挂掉,然后流量比较大的时候,可以横向扩充服务来保证业务的流畅。比如我们最常使用k8s,能保证服务的运行状态,也可以让服务自动的横向扩充。对于用户访问量的激增情况这样处理还是很不错的,但是,横向扩充也是有尽头的,如果在一定环境下E服务的响应时间过长,依然有可能导致雪崩效应的产生。

限流
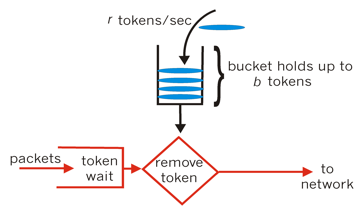
限制客户端的调用来达到限流的做法是很常见的,比如,我们限制每秒最大处理200个请求,超过个数量直接拒绝请求。常见的算法如令牌桶算法
以一定的速度在桶里放令牌,当客户端请求服务的时候,要先从桶里得到令牌,才能被处理,如果桶里的令牌用完了,则拒绝访问。
熔断
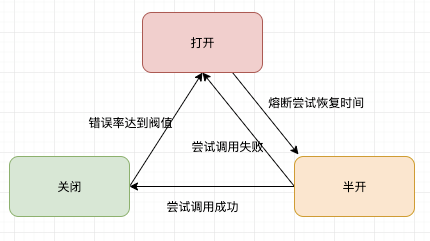
在客户端控制对依赖的访问,如果调用的依赖不可用时,则不再调用,直接返回错误,或者降级处理。开源的库比如hystrix-go,也是我接下来要写的源码分析的一个库。很好的实现了熔断和降级的功能。他的主要思想是,设置一些阀值,比如,最大并发数,错误率百分比,熔断尝试恢复时间等。能过这些阀值来转换熔断器的状态:
- 关闭状态,允许调用依赖
- 打开状态,不允许调用依赖,直接返回错误,或者调用fallback
- 半开状态,根据
熔断尝试恢复时间来开启,允许调用依赖,如果调用成功则关闭失败则继续打开
具体的实现方式和对hystrix-go源码的分析,我在后续的帖子会详细给大家介绍。