Summary:
High-latitude data is not easily calculated, projected onto the low latitude often require space dimensionality reduction.
This chapter introduces a dimension reduction method: PCA (Principal Component Analysis)
Reference Links: https://blog.csdn.net/u012421852/article/details/80458350
Implementation steps
PCA dimensionality reduction steps:
1. All samples were central processing
2. Calculate the covariance matrix
3. Covariance eigenvalues and eigenvectors
4. feature values sorted in descending order, selecting the largest k a, and then eigenvectors corresponding to the k column vectors each composed of a matrix converter
5 through the lower-order conversion matrix to convert the original matrix into a low-dimensional matrix.
Code:
# -*- coding: utf-8 -*-
import numpy as np
import xlrd
import tensorflow as tf
#读取表格数据,填充到矩阵作为数据集
def read_data(X):
worksheet = xlrd.open_workbook(u'img/data.xlsx')
sheet_names= worksheet.sheet_names()
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
for i in range(1,rows) :
X[i-1][0] = sheet.cell_value(i, 1) # 取第2列数据
X[i-1][1] = sheet.cell_value(i, 2) # 取第3列数据
class PCA(object):
def __init__(self, X, K):
self.X = X #样本矩阵X
self.K = K #K阶降维矩阵的K值
self.centrX = [] #矩阵X的中心化
self.C = [] #样本集的协方差矩阵C
self.U = [] #样本矩阵X的降维转换矩阵
self.Z = [] #样本矩阵X的降维矩阵Z
self.centrX = self._centralized()
self.C = self._cov()
self.U = self._U()
self.Z = self._Z() #Z=XU求得
# 1.矩阵X的中心化
def _centralized(self):
centrX = []
mean = np.array([np.mean(attr) for attr in self.X.T]) #样本集的特征均值
centrX = self.X - mean ##样本集的中心化
print('样本集的特征均值:\n',mean)
return centrX
#2.求样本矩阵X的协方差矩阵C
def _cov(self):
#样本集的样例总数
ns = np.shape(self.centrX)[0]
#样本矩阵的协方差矩阵C
C = np.dot(self.centrX.T, self.centrX)/(ns - 1)
print('样本矩阵X的协方差矩阵C:\n', C)
return C
#3.求协方差矩阵C的特征值、特征向量
def _U(self):
#先求X的协方差矩阵C的特征值和特征向量
a,b = np.linalg.eig(self.C) #特征值赋值给a,对应特征向量赋值给b
print('样本集的协方差矩阵C的特征值:\n', a)
print('样本集的协方差矩阵C的特征向量:\n', b)
#给出特征值降序的topK的索引序列
ind = np.argsort(-1*a)
#4.构建K阶降维的降维转换矩阵U
UT = [b[:,ind[i]] for i in range(self.K)] #获取最大的k个值的
U = np.transpose(UT) #构成一维转换矩阵
print('%d阶降维转换矩阵U:\n'%self.K, U)
return U
#5.通过低阶转换矩阵,把原矩阵转换成低维矩阵
def _Z(self):
Z = np.dot(self.X, self.U) #计算X和转换矩阵的乘积,得到降维后的矩阵
print('样本矩阵X的降维矩阵Z:\n', Z)
print('原矩阵的维度:', np.shape(X))
print('降维后的维度:', np.shape(Z))
return Z
if __name__=='__main__':
#读取xlsx的数据
X=np.zeros([50,2]) #创建一个50*2的0矩阵
dataset=read_data(X) #读取表格中的数据,放到矩阵中
#2维变成1维
K = np.shape(X)[1] - 1 #降低一维,k为得到结果的维度
pca = PCA(X,K) #调用PCA主函数
The input data is a table containing two columns of data after the reading obtained is a matrix of 2 * 50
Get the result:
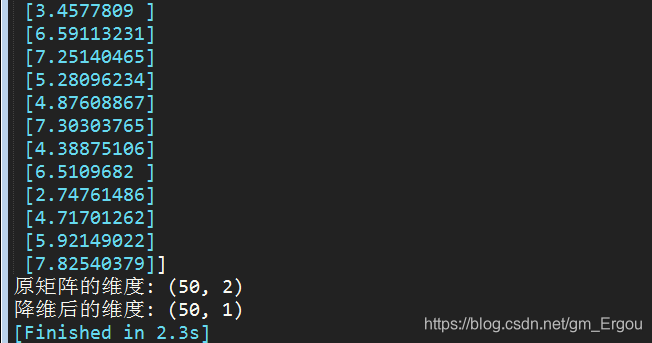
visible newly acquired matrix has become a first-order matrix 50 * 1, to achieve a dimensionality reduction.