DBSCAN (Density-Based Spatial Clustering of Application with Noise) algorithm is a typical density-based clustering method. It will set the maximum point is defined as the density of the clusters are connected, it is possible to have a sufficient density area division into clusters, and clusters of discover arbitrary shape can be concentrated in the space of noisy data.
1. Basic Concepts
DBSCAN algorithm has two important parameters: Eps and MmPtS. Eps neighborhood radius is defined density, MmPts to define the threshold at the core point.
Divided into the following three categories of data points in the DBSCAN algorithm.
1) The core point
If an object contains more than the number of points within a radius MmPts Eps, the object is a core point.
2) border point
If the number of objects in a radius somewhat less than the Eps MinPts contents, but the object falls core points neighborhood, the object is a boundary point.
3) Noise point
If an object is neither a point nor the core boundary point, the object is a noise point.
More simply, the core points corresponding to points interior dense region, boundary points corresponding to the dense edge region, the noise point corresponding points of the sparse area.
In Figure 1, it is assumed MinPts = 5, as shown in FIG. Eps arrow lines, the point A is the core point, the point B as a boundary point, point C is the point noise. A point because it contains seven points in its neighborhood Eps over the Eps = 5, it is the core point.
Points E and C because of its neighborhood point number Eps containing less than 5 are, so it is not a core point; point B falls Eps neighborhood because the point A, the point B is a boundary point; point C because of does not fall within any of the core point of the neighborhood, so is the noise point.
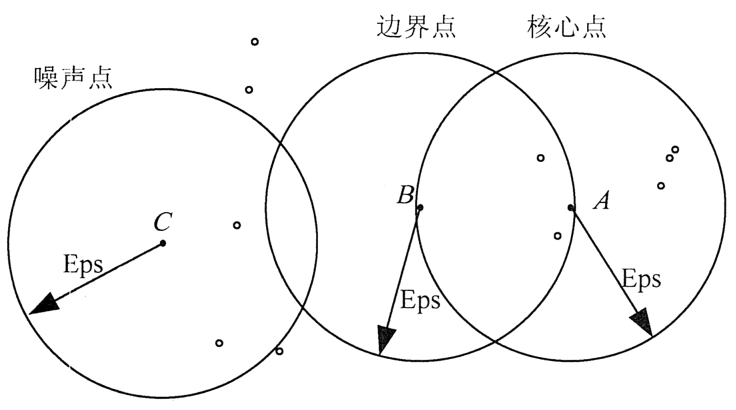
FIG 1 DBSCAN data point type schematically algorithm
Further speaking, DBSCAN algorithm also involves some of the following concepts.
| name | Explanation |
|---|---|
| Eps neighborhood | Simply put, that is, the distance of a point less than or equal set of all points of Eps. |
| Direct density of up to | If the point p in the neighborhood Eps core point q, p called data objects from the data object q is directly density reachable. |
| Density of up to | If the data of strands are present 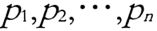  from from  about Eps and MinPts directly density-reachable, the data object about Eps and MinPts directly density-reachable, the data object 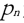 from the data object from the data object 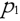 on EpsMinPts density-reachable. on EpsMinPts density-reachable. |
| Linked density | P and q objects for the object, if the core samples o the object exists, so that the data objects p and q are reachable objects from the density o, p and q are connected called density. Clearly, having a density of symmetries is connected. |
| Density Clustering clusters | All objects consists of a core point and its density cluster density of up to constitute a cluster. |
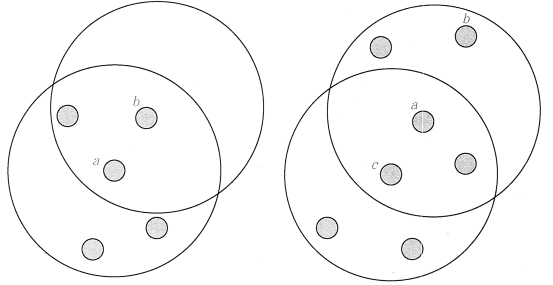
FIG 2 is directly reachable density and density up to a schematic
In FIG. 2, point A is a core point, point b as a boundary point, and since a direct density-reachable b. But b does not directly density of up to a (since b is not a core point). Since the density is directly reachable c a, a direct density of up to b, c so that a density of up to b. But because the density is not directly reachable b a, b is not so density of up to c. However, density b and c are connected.
2. The algorithm description
DBSCAN algorithm is very simple to define clusters, connected by the maximum density sample density of up relations derived collection is the final cluster of a cluster.
Inside a cluster of DBSCAN you can have one or more core points. If only one core point, the cluster in other non-core samples are at this point core point Eps neighborhood zone. If more than one core point, a core cluster in any point of Eps neighborhood must have a central point of the other, or else these two core point density can not reach. Eps neighborhood of these points in the core collection of all samples of a DBSCAN cluster cluster.
DBSCAN algorithm described below.
- Input: data set, Eps radius neighborhood, the neighborhood data object MinPts threshold number;
- Output: China Unicom density clusters.
Process is as follows.
1) from the data set to select a data object in any point p;
2) If the parameter for Eps and MinPts, the selected data points as the core target point p, then find all reachable objects from the p-density data points, form a cluster;
3)如果选取的数据对象点 p 是边缘点,选取另一个数据对象点;
4)重复(2)、(3)步,直到所有点被处理。
DBSCAN 算法的计算复杂的度为 O(n²),n 为数据对象的数目。这种算法对于输入参数 Eps 和 MinPts 是敏感的。
3. 算法实例
下面给出一个样本数据集,如表 1 所示,并对其实施 DBSCAN 算法进行聚类,取 Eps=3,MinPts=3。
| p1 | p2 | p3 | p4 | p5 | p6 | p7 | p8 | p9 | p10 | p11 | p12 | p13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 2 | 4 | 5 | 6 | 6 | 7 | 9 | 1 | 3 | 5 | 3 |
| 2 | 1 | 4 | 3 | 8 | 7 | 9 | 9 | 5 | 12 | 12 | 12 | 3 |
数据集中的样本数据在二维空间内的表示如图 3 所示。
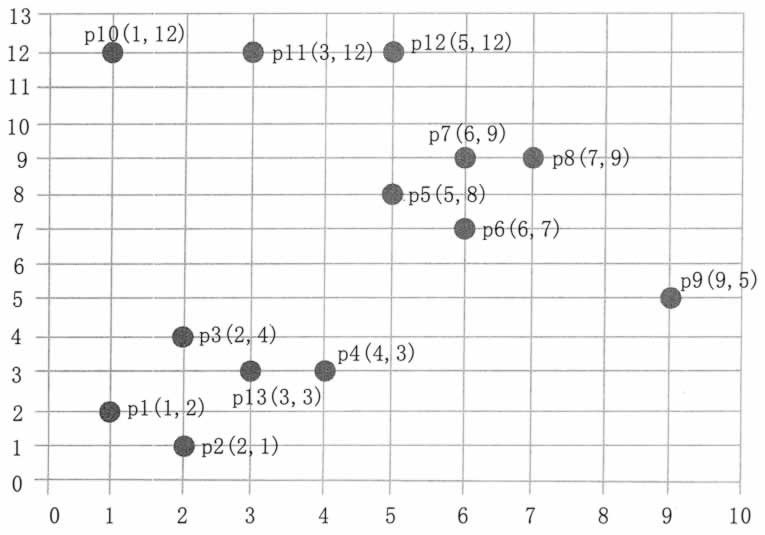
图 3 直接密度可达和密度可达示意
第一步,顺序扫描数据集的样本点,首先取到 p1(1,2)。
1)计算 p1 的邻域,计算出每一点到 p1 的距离,如 d(p1,p2)=sqrt(1+1)=1.414。
2)根据每个样本点到 p1 的距离,计算出 p1 的 Eps 邻域为 {p1,p2,p3,p13}。
3)因为 p1 的 Eps 邻域含有 4 个点,大于 MinPts(3),所以,p1 为核心点。
4)以 p1 为核心点建立簇 C1,即找出所有从 p1 密度可达的点。
5)p1 邻域内的点都是 p1 直接密度可达的点,所以都属于C1。
6)寻找 p1 密度可达的点,p2 的邻域为 {p1,p2,p3,p4,p13},因为 p1 密度可达 p2,p2 密度可达 p4,所以 p1 密度可达 p4,因此 p4 也属于 C1。
7)p3 的邻域为 {p1,p2,p3,p4,p13},p13的邻域为 {p1,p2,p3,p4,p13},p3 和 p13 都是核心点,但是它们邻域的点都已经在 Cl 中。
8)P4 的邻域为 {p3,p4,p13},为核心点,其邻域内的所有点都已经被处理。
9)此时,以 p1 为核心点出发的那些密度可达的对象都全部处理完毕,得到簇C1,包含点 {p1,p2,p3,p13,p4}。
第二步,继续顺序扫描数据集的样本点,取到p5(5,8)。
1)计算 p5 的邻域,计算出每一点到 p5 的距离,如 d(p1,p8)-sqrt(4+1)=2.236。
2)根据每个样本点到 p5 的距离,计算出p5的Eps邻域为{p5,p6,p7,p8}。
3)因为 p5 的 Eps 邻域含有 4 个点,大于 MinPts(3),所以,p5 为核心点。
4)以 p5 为核心点建立簇 C2,即找出所有从 p5 密度可达的点,可以获得簇 C2,包含点 {p5,p6,p7,p8}。
第三步,继续顺序扫描数据集的样本点,取到 p9(9,5)。
1)计算出 p9 的 Eps 邻域为 {p9},个数小于 MinPts(3),所以 p9 不是核心点。
2)对 p9 处理结束。
第四步,继续顺序扫描数据集的样本点,取到 p10(1,12)。
1)计算出 p10 的 Eps 邻域为 {p10,pll},个数小于 MinPts(3),所以 p10 不是核心点。
2)对 p10 处理结束。
第五步,继续顺序扫描数据集的样本点,取到 p11(3,12)。
1)计算出 p11 的 Eps 邻域为 {p11,p10,p12},个数等于 MinPts(3),所以 p11 是核心点。
2)从 p12 的邻域为 {p12,p11},不是核心点。
3)以 p11 为核心点建立簇 C3,包含点 {p11,p10,p12}。
第六步,继续扫描数据的样本点,p12、p13 都已经被处理过,算法结束。
4. 算法优缺点
和传统的 k-means 算法相比,DBSCAN 算法不需要输入簇数 k 而且可以发现任意形状的聚类簇,同时,在聚类时可以找出异常点。
DBSCAN 算法的主要优点如下。
1)可以对任意形状的稠密数据集进行聚类,而 k-means 之类的聚类算法一般只适用于凸数据集。
2)可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
3)聚类结果没有偏倚,而 k-means 之类的聚类算法的初始值对聚类结果有很大影响。
DBSCAN 算法的主要缺点如下。
1)样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用 DBSCAN 算法一般不适合。
2)样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的 KD 树或者球树进行规模限制来进行改进。
3) When debugging complex parameters, primarily the need for distance threshold Eps, the number of neighborhood samples MinPts threshold parameter adjustment joint, different combinations of parameters have a greater impact on the final clustering result.
4) for the entire data set using only a set of parameters. If data exists in different densities or concentrated clusters nested clusters, the algorithm can not handle DBSCAN. To solve this problem, it was suggested that the OPTICS algorithm.
. 5) DBSCAN noise filtering algorithm may point, which is also the disadvantage that it causes discomfort to certain areas, such as the determination of the field of network security malicious attacks.
57 association rules data mining analysis
58. The Apriori algorithm and FP-Tree algorithm
59. Based on a large data precision marketing of
60. based personalized recommendation system big data
61. Big Data predictive
62. The other big data applications
63. big data can be used in which industries
64. in the financial industry, large application data
65. big data applications in the Internet industry
66. the application of big data in the logistics industry