title: PySpark SQL knowledge presentation
summary: Keywords: Big Data Hadoop Hive Pig Kafka Spark PySpark SQL cluster manager Cassandra MongoDB PostgreSQL
DATE: 2019-06-06 13:56
urlname: 2,019,060,601
the Categories: Big Data
tags:
- PySpark
- Big Data
img: /medias/featureimages/9.jpg
author: foochane
toc: to true
MathJax: false
Author: foochane
This link: https://foochane.cn/article/2019060601.html
1 Introduction to Big Data
Big Data is one of the hottest topics of this era. But what is big data? It describes a large data set, and is growing at an alarming rate. In addition to large data volumes (Volume) and velocity (Velocity), the characteristics of a large variety of data (Variety) and accuracy (Veracity) is a large data. Let us discuss in detail the volume, speed, diversity and accuracy. These are also known large data characteristic 4V.
1.1 Volume
Amount of data volumes (Volume) designated to be processed. For large amounts of data, we need a large machine or distributed systems. Computation time increases the amount of data increases. So if we can parallelize the calculation, it is best to use a distributed system. Data may be structured data, unstructured data, or data interposed therebetween. If we have unstructured data, then the situation will become more complex and computationally intensive. You might be thinking, big data in the end how much? This is a controversial issue. But in general, we can say that we can not use the traditional system the amount of data processing is defined as big data. Now let's talk about speed data.
1.2 Velocity
More and more organizations paying attention to the data. All the time to collect large amounts of data. This means that the data rate is increasing. How a system to deal with this speed? When must analyze real-time data influx, the problem becomes complicated. Many systems are being developed to deal with this huge inflow data. Another factor will be the traditional data and big data distinguish the diversity of the data.
1.3 Variety
Diversity of data makes it very complicated, traditional data analysis system can not analyze it correctly. We say what kind? No data is data? Image data is different from the form data, because of the different way it is organized and stored. You can use an unlimited number of file systems. Each file system requires a different approach to deal with it. Read and write JSON files and CSV files of different manner. Now, data scientists have to deal with a combination of data types. Your data will be processed may be a combination of images, video, text and so forth. Diversity makes big data analysis becomes more complicated.
1.4 Veracity
Can you imagine a logic error in the computer program to generate the correct output it? Also, inaccurate data will provide misleading results. Accuracy or correctness of the data, is an important issue. For large data, we must consider abnormal data.
2 Hadoop Introduction
Hadoop is a distributed problem solving big data, scalable framework. Hadoop by Doug Cutting and Mark Cafarella development. Hadoop is written in Java. It may be mounted on a set of commercially available hardware, and can be horizontally extended on a distributed system.
Work on commodity hardware, making it very efficient. If our work is in the commodity hardware failure is an unavoidable problem. However Hadoop provides a fault tolerant data storage and calculation system. This fault tolerance makes Hadoop very popular.
Hadoop has two components: The first component is HDFS (Hadoop Distributed File System), which is a distributed file system. The second component is MapReduce. HDFS for distributed data storage, MapReduce for performing calculations on the data stored in the HDFS.
2.1 HDFS Introduction
HDFS for distributed fault-tolerant manner and storing large amounts of data. HDFS is written in Java, it runs on commodity hardware. It was inspired by the Google research papers Google File System (GFS) is. It is a write-once read-many systems, a large amount of data is valid. HDFS has two components NameNode and DataNode.
These two components are Java daemon. NameNode responsible for maintaining metadata files distributed across the cluster, which is the primary node of many datanode. HDFS large file into pieces, and these blocks are stored in different datanode. The actual file data block resides on datanode. Providing a set of classes HDFS unix-shell commands. However, we can use the Java filesystem API HDFS provides processing large files on a finer level. Fault tolerance is accomplished by copying the data block.
We can use single-threaded process concurrent access HDFS file. HDFS provides a very useful utility invocation of DistCp is referred to, it is usually used to transfer data in parallel from one system to another HDFS HDFS system. It uses a parallel mapping task to copy the data.
2.2 MapReduce Introduction
MapReduce computation model first appeared in Google's research paper. The calculation engine is MapReduce Hadoop Hadoop frame, it calculates the distributed data in HDFS. MapReduce has been found can be scaled horizontally on commodity hardware in distributed systems. It also applies to big problems. In MapReduce, the problem is divided into stages Map and Reduce phase. In Map stage, processing the data block, in Reduce stage, the results of the polymerization runs Map stage or shrink operation. Hadoop's MapReduce framework is written in Java.
MapReduce is a master-slave model. In Hadoop 1, MapReduce computation is managed by the two daemons Jobtracker and Tasktracker. Jobtracker is the main process to handle many tasks tracker. Tasktracker is Jobtracker from the node. However, in the Hadoop 2, Jobtracker and Tasktracker substituted YARN.
We can use the API and framework written in Java MapReduce code. Hadoop streaming body module enables programmers have knowledge of Python and Ruby can write MapReduce programs.
MapReduce algorithms have many uses. As many machine learning algorithms are implemented Apache Mahout, it can be run on the Pig and Hive Hadoop.
But MapReduce is not suitable iterative algorithm. At the end of each job Hadoop, MapReduce HDFS save data to and reads data again for the next job. We know that the data read and write files are costly activities. Apache Spark by providing data persistence and computing memory, MapReduce reduce disadvantages.
More about Mapreduce and Mahout can see the following pages:
3 Apache Hive Introduction
Computer science is an abstract world. Everyone knows that the data is in the form of bits of information appear. Such as the C programming language provides an abstract machine and assembly language. Other high-level language provides more abstract. Structured Query Language (Structured Query Language, SQL) is one of these abstract. Many data modeling experts from around the world are using SQL. Hadoop is ideal for large data analysis. So, how to understand the majority of users take advantage of SQL Hadoop big data computing capabilities on it? In order to write Hadoop's MapReduce program, the user must know the programming language can be used to write Hadoop's MapReduce programs.
Everyday problems in the real world follow a certain pattern. Some problems are common in everyday life, such as data manipulation, handling missing values, data conversion and data collection. Write MapReduce code for these everyday problems is a dizzying work for non-programmers. Write code to solve the problem is not a very smart thing. But writing efficient code having scalability and performance scalability is valuable. Taking into account this problem, Apache Hive in Facebook developed, it can solve everyday problems, without the need to write MapReduce code for the general problem.
According Hive wiki language, Hive is a data warehouse infrastructure based on Apache Hadoop. Hive has its own SQL dialect, called the Hive query language. It is called HiveQL, sometimes called HQL. Use HiveQL, Hive query data in HDFS. Hive is not only running on HDFS, also runs on Spark and other big data frameworks, such as Apache Tez.
Hive provides a relational database management system abstraction similar to the structured data to users in HDFS. You can create tables and run queries similar to sql on it. Hive table mode stored in some RDBMS. Apache Derby is Apache Hive release comes with default RDBMS. Apache Derby is entirely written in Java, it is the Apache License Version 2.0 comes with open source RDBMS.
HiveQL command is converted into the Hadoop MapReduce code, and then run on a Hadoop cluster.
SQL understand people can easily learn Apache Hive and HiveQL, and can use Hadoop storage and computing power in everyday big data analysis work. PySpark SQL also supports HiveQL. You can run HiveQL PySpark SQL commands in. In addition to performing HiveQL queries, you can also read the data directly from the Hive and writes the result to PySpark SQL Hive
Related Links:
4 Apache Pig Introduction
Apache Pig frame is a data stream, for performing data analysis of large amounts of data. It was developed by Yahoo! and to the Apache Software Foundation open source. It can now be used under the Apache License version 2.0. Pig Pig Latin programming language is a scripting language. Pig loosely connected to Hadoop, which means we can connect it to Hadoop and perform many analysts. But the Pig can be used with other tools such as Apache Tez and Apache Spark.
Apache Hive as reporting tools, wherein Apache Pig used to extract, transform, and load (ETL). We can use the user-defined function (UDF) extended Pig functionality. User-defined functions can be written in multiple languages, including Java, Python, Ruby, JavaScript, Groovy and Jython.
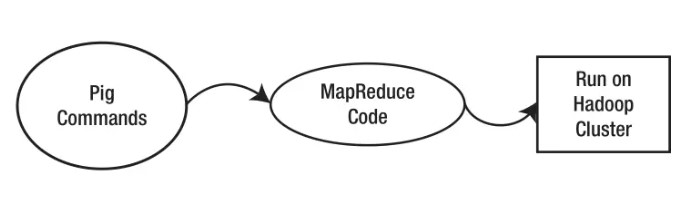
Apache Pig read and store data using HDFS, MapReduce algorithm execution of Hadoop. Apache Pig is similar to Apache Hive in using Hadoop cluster. On Hadoop, Pig command is first converted into Hadoop's MapReduce codes. MapReduce then converts them into code that runs on Hadoop cluster.
The best part of the Pig is to optimize the code and test, in order to deal with everyday problems. So users can install Pig and start using it. Pig provides Grunt shell to run the interactive command Pig. Therefore, any understanding of Pig Latin people can enjoy the benefits of HDFS and MapReduce without having to know Java or Python and other high-level programming language.
Related Links
5 Apache Kafka Introduction
Apache Kafka is a publish - subscribe distributed messaging platform. It was developed by LinkedIn, and further open source to the Apache Foundation. It is fault tolerant, scalable and fast. Kafka terminology message (the smallest unit of data) from the producer to the consumer through the server Kafka, and may be persisted and used at a later time.
Kafka provides a built-in API, developers can use it to build their applications. Next we discuss the three main components of Apache Kafka.
5.1 Producer
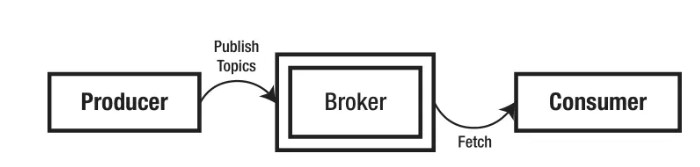
Kafka Producer will generate a message to Kafka theme, it can publish data to multiple topics.
5.2 Broker
This is run on a dedicated machine Kafka server, the message Producer pushed Broker. Broker theme will be stored in different partitions, these partitions are copied to a different Broker to handle errors. It is essentially stateless, so the user must keep track of its consumer news.
5.3 Consumer
Consumer get messages from Kafka agent. Remember, it gets the message. Kafka Broker message will not be pushed Consumer; contrary, Consumer extract the data from Kafka Broker. Consumer subscribe to one or more topics on Kafka Broker, and read messages. Broker also tracks all messages it uses. Data is saved in the specified time in Broker. If the user fails, it can obtain the data after the restart.
Related Links:
6 Apache Spark Introduction
Apache Spark is a generic framework for distributed programming. It is considered well suited for iterative and batch data. It was developed in the laboratory of AMP, which provides an in-memory computing framework. It is open source software. On the one hand, it is the most suitable for batch processing, on the other hand, its real-time or near real-time data is very effective. And graphics on the machine learning algorithm is iterative in nature, this is the magic of Spark. According to its research papers, it is much faster than its peers Hadoop. Data can be cached in memory. In the middle of the iterative algorithm cached data provide amazing fast processing. Spark can use Java, Scala, Python, and R programming.
If you think Spark is improved Hadoop, to some extent, it can indeed think so. Because we can implement MapReduce algorithm in Spark, Spark so use the advantages of HDFS. This means that it can read data from and store data to HDFS HDFS, and it can effectively deal with the iterative calculation, because the data can be stored in memory. In addition to in-memory computing, interactive data analysis also applies to.
There are many other libraries are located on PySpark, to make it easier to use PySpark. Here we will discuss some of them:
- MLlib: MLlib PySpark core is a wrapper that handles machine learning algorithms. MLlib library of machine learning api very easy to use. MLlib supports a variety of machine learning algorithms, including classification, clustering, text analysis, and so on.
- ML: ML is located PySpark a core of machine learning library. ML api machine learning can be used for data streams.
- GraphFrames: GraphFrames library provides a set of api, you can use PySpark core and PySpark SQL efficiently graphical analysis.
7 PySpark SQL Introduction
Most of the data processing of data scientists, in essence, is either structured or semi-structured. To handle structured and semi-structured data sets, PySpark SQL module is a higher level of abstraction above the PySpark core. We will learn PySpark SQL throughout the book. It is built in PySpark, which means it does not require any additional installation.
Use PySpark SQL, you can read data from many sources. PySpark SQL supports reading systems from a number of file formats, including text files, CSV, ORC, Parquet, JSON, etc. You can read data from a relational database management system (RDBMS), such as MySQL and PostgreSQL. You can also save a lot of analysis of the systems and file formats.
7.1 DataFrames
DataFrames is an abstraction, similar to a relational database system tables. They consist of the specified column. DataFrames line is a collection of objects, these objects are defined in the PySpark SQL. DataFrames also consist of columns specified object. The user knows the pattern table form, it is easy to operate on the data stream.
DataFrame column element will have the same data type. The DataFrame line may be composed of different types of data elements. The basic data structure called elastic distributed data set (RDD). Packaging the data stream on the RDD. They are RDD or row objects.
Related Links:
7.2 SparkSession
Alternatively the object is SparkSession HiveContext SQLContext and entry points. To make PySpark SQL code compatible with previous versions, SQLContext and HiveContext will continue to run in PySpark. In PySpark console, we get a SparkSession object. SparkSession we can create an object using the following code.
To create SparkSession object, we must import SparkSession, as shown below.
from pyspark.sql import SparkSessionAfter importing SparkSession, we can use SparkSession.builder operate:
spark = SparkSession.builder.appName("PythonSQLAPP") .getOrCreate()appName function sets the name of the application. Function returns: Returns SparkSession an existing object. If SparkSession object does not exist, getOrCreate () function creates a new object and return it.
7.3 Structured Streaming
We can use the structure of the frame stream (PySpark SQL wrapper) streaming data analysis. We can perform flow analysis using structured in a similar way streaming data, just as we use the same static data PySpark SQL to perform batch analysis. Spark flow module as small as batch execution flow operation, the flow of the structure of the smaller batch execution engines stream operation. The best part of the flow structure is that it uses a similar PySpark SQL API. Therefore, a high learning curve. To optimize the operation of the data stream, and in a similar manner to optimize the performance of the structured stream in the context API.
7.4 Catalyst Optimizer
SQL is a declarative language. Using SQL, SQL engine we told what to do. We do not tell it how to perform tasks. Similarly, PySpark SQL command does not tell it how to perform tasks. These commands tell it just what you want to perform. Therefore, PySpark SQL query need to optimize the implementation of its mandate. catalyst optimizer performs in PySpark SQL query optimization in. PySpark SQL query is converted to a lower elasticity distributed data sets (RDD) operation. catalyst optimizer first PySpark SQL queries into logical plan, then plan to convert this logic optimized logic program. Create a physical plan from the optimized logic program. Creating multiple physical plan. Cost analyzer, selecting an optimal physical embodiment. Finally, create a low-level RDD operation code.
8 Cluster Manager (Cluster Managers)
In a distributed system, a job or application is divided into different tasks, which can be on different machines in a cluster in parallel. If the machine fails, you must rearrange the task on another machine.
Due to poor resource management, distributed systems typically faced scalability issues. Consider an already running on the cluster job. Another person wanted to do another job. The second task must wait until the first job is completed. But we do not make optimal use of resources. Resource management is very easy to explain, but difficult to achieve on a distributed system. Development Cluster Manager is to optimize the management of cluster resources. There are three clusters Spark Manager can be used stand-alone, Apache Mesos and YARN. The best part of these cluster manager is that they provide a layer of abstraction between the user and the cluster. Since the abstract cluster manager provides a user experience like working on a machine, even though they work on the cluster. Cluster Manager cluster application resource scheduling to running.
8.1 Stand-alone Cluster Manager (Standalone Cluster Manager)
Apache Spark comes with a stand-alone cluster manager. It provides a master-slave architecture to excite clusters. It is only spark a cluster manager. You can only use this independent run Spark cluster manager application. Its main components are the components and assembly work. Workers are slaves of the primary process, it is the most simple cluster manager. Sbin directories can be used in the script configuration Spark Spark separate cluster manager.
8.2 Apache Mesos cluster manager (Apache Mesos Cluster Manager)
Apache Mesos is a general-purpose cluster manager. It is in the AMP Lab at UC Berkeley developed. Apache Mesos distributed solutions help to effectively expand. You can use Mesos different frameworks use different applications running on the same cluster. What do the different applications from different framework is? This means that you can run applications on Mesos Hadoop and Spark application. When multiple applications are running on the Mesos, they shared resource cluster. Apache Mesos There are two important components: the main assembly and the assembly. This master-slave architecture is similar to Spark separate cluster manager. Applications running on Mesos called the framework. Slaves tell the owner as an available resource resources available. Slave provide resources on a regular basis. Master server allocation module determines which frame access to resources.
8.3 YARN Cluster Manager (YARN Cluster Manager)
YARN represents another resource negotiators (Resource Negotiator). YARN introduced in Hadoop 2 extend Hadoop. Separation resource management and job management. This component enables two separate Hadoop better stretchability. The main ingredient is YARN Resource Manager (Resource Manager), Application Manager (Application Master) and Node Manager (Node Manager). There is a global resource manager, each cluster will run a number of Node Manager. Node Manager is a slave to the resource manager. The scheduler is a component ResourceManager, it allocates resources to different applications on the cluster. The best part is that you can run the Spark application and any other applications simultaneously on YARN managed cluster, such as Hadoop or MPI. Each application has an application master, processing tasks that run in parallel on a distributed system. In addition, Hadoop and Spark have their own ApplicationMaster.
Related Links:
9 PostgreSQL Introduction
Relational database management systems in many organizations are still very common. The relationship here is what does this mean? Relational tables. PostgreSQL is a relational database management systems. It runs on all major operating systems such as Microsoft Windows, unix-based operating system, MacOS X, and so on. It is an open source code is available under license PostgreSQL. Therefore, you can freely use it and modify it to your needs.
PostgreSQL databases can be connected through other programming languages (such as Java, Perl, Python, C and c ++) and many other languages (through different programming interfaces). You can also use the PL / SQL programming language similar process PL / pgSQL (Procedural Language / PostgreSQL) be programmed. You can add custom functions to the database. You can write custom functions using C / c ++ and other programming languages. You can also use PostgreSQL JDBC connector to read data in from the PySpark SQL.
PostgreSQL follow the ACID (Atomicity, Consistency, Isolation and
Durability Rev / atomicity, consistency, isolation and durability) principle. It has many features, some of which are unique to PostgreSQL. It supports updatable views, transactional integrity, complex queries, triggers, and so on. PostgreSQL uses a multi-version concurrency control model concurrency management.
PostgreSQL has been widespread community support. PostgreSQL is designed and developed to be extensible.
Related Links:
10 MongoDB Introduction
MongoDB NoSQL database is based on a document. It is an open source distributed database, MongoDB developed by the company. MongoDB is written in c ++, it is scalable level. Many organizations use it for back-end databases and many other uses.
MongoDB comes with a mongo shell, which is a MongoDB server to a JavaScript interface. mongo shell can be used to run queries and perform administrative tasks. In the mongo shell, we can also run JavaScript code.
Use PySpark SQL, we can read from MongoDB data and perform analysis. We can also write the result.
Related Links:
11 Cassandra Introduction
Cassandra is an open source distributed database, with the Apache license. This is a development of Facebook's NoSQL database. It is horizontally scalable, the most suitable for processing structured data. It provides a high level of consistency, and has an adjustable consistency. It does not have a single point of failure. It uses the distributed architecture of the duplicated data, etc. on different nodes. Node uses gossip protocol to exchange information.
Related Links: