Personal cognition, for reference only, welcome to criticize and correct!
Introduction to Knowledge Graph
I. Overview
Since Google put forward the concept of knowledge graph in 2012, knowledge graph has gradually become a jewel in the field of AI. Especially in recent years, knowledge graph has become a mess. In Internet-related companies, people will ask if they are doing knowledge graphs. Regardless of technology, products, front-end, and sales, they all have an infinitely beautiful vision for the knowledge graph.
But here comes the problem. Against the background of such a hot development of knowledge graphs, many people are misled by amplified propaganda and believe that knowledge graphs have the same potential as an intelligent brain, which can achieve unstructured to structured data, intelligent recommendation, Powerful functions such as intelligent search and intelligent reasoning. It is true that these functions can be done based on the knowledge graph, but they are not entirely due to the knowledge graph. The knowledge graph can be understood as a powerful knowledge base, like Transformers, which can turn the relational database storage mode into a dot-by-side entity relationship storage structure, and can be well displayed, which is more intuitive, more vivid and more convenient .
However, the entity relationship in the knowledge graph is the function of NLP information extraction, as well as related text analysis, visual analysis, audio analysis and other AI algorithms, which convert multi-modal unstructured data into structured data and store it in knowledge In the map, and proceed to the next application. The so-called intelligent reasoning is also realized based on the knowledge graph and combined with related algorithms.
Although the independent knowledge graph seems relatively simple, a series of technologies that depend on the knowledge graph, including information extraction, entity linking, knowledge reasoning and other technologies, as well as downstream applications based on the knowledge graph, are very powerful. The knowledge graph also provides good inspiration for some previously difficult and easy-to-solve problems.
In the following chapters, let me briefly introduce the process and application of knowledge graph construction, so that everyone can understand more directly.
2. Knowledge graph construction
The construction of knowledge graph includes two parts, the data layer and the model layer .
The data layer stores specific entities and relationships/attributes, including entity-relation-entity , and entity-attribute-value . Entities and values are represented by nodes, and relationships and attributes are represented by edges. Through the relationship between entities and entities in the data layer, a database stored in fact units can be established. At the same time, entities can be described and added by attributes.
The model layer, above the data layer, is refined, but managed through the ontology library, and the data layer content such as entities, relationships, and entity types and attributes are restricted by the ontology library.
The difference between the data layer and the pattern layer can be understood as the difference between classes and objects in the code. The pattern layer is equivalent to the class, and the data layer is equivalent to the object after instantiation.
For example:
Mode level: company-legal person-person; company-establishment time-time;
Data layer: Tencent-legal person-Ma Huateng; Tencent-establishment time-November 1998;
There are two ways to construct the knowledge graph: top-down and bottom-up. Top-down construction usually uses structured data sources such as encyclopedia websites to extract ontology and pattern information from high-quality data and add it to the knowledge base; the so-called bottom-up construction, through the use of certain technical means, from public collection Relevant models are extracted from the data, and new models with high confidence are selected, and after manual review, they are added to the knowledge base. At present, most of the knowledge graph construction adopts a bottom-up construction method. This article also mainly introduces the bottom-up knowledge graph construction technology. According to the process of knowledge acquisition, it is divided into three levels: information extraction, knowledge fusion and knowledge processing.
2.1 Knowledge graph construction technology
Information extraction
Extract entities (concepts), attributes, and relationships between entities through different types of data sources, and form ontological knowledge expression on the basis again.
The current data sources include text (webpages, charts, files, etc.), voice, pictures, videos, etc. At present, there are more text-based information extractions. This article mainly introduces text-based information extraction methods, self-study on voice and video.
Text-based information extraction mainly includes: entity recognition, relationship extraction, and attribute extraction.
Entity extraction NER: Unsupervised methods mostly use dictionaries, rules, syntax, etc. Supervised NER methods mainly include HMM, EMHMM, CRF, LSTM+CRF, BERT+LSTM+BERT. For specific methods, you can browse my other blog posts or Baidu yourself.
Relation extraction: Initially, it is realized by grammatical and semantic rules. Under the premise of labeling data, it can be transformed into a binary classification problem of entity-relation-entity is correct. Features can be constructed artificially (such as distance in text, whether there are punctuation marks, etc.) Entity location, relationship type, etc.), through the machine learning classification (SVM, NB, LR, GBDT, etc.) method for two classification. With the rise of neural networks and the training of the BERT pre-training model, dual attention models, end-to-end entity + relationship extraction models, etc. have also appeared.
Attribute extraction is the same as relationship extraction. It also includes some semi-structured data for automatic extraction training.
Let me say a little bit more here. The logic of remote supervision. For relation extraction, because it is difficult to label large-scale corpus, you can consider using remote supervision, and use existing labeled entity pairs to perform text labeling to obtain approximate manual labeling data. Further model training and tuning.
Knowledge fusion
The structured data obtained from information extraction may contain a lot of redundancy and error information. The relationship between the data is also flat, lacking in hierarchy and logic, and needs to be further cleaned and integrated. A lot of knowledge fusion related technologies were born with it, including entity linking and knowledge merging.
Before talking about technology, let me first talk about a lot of headaches that I have seen: entity linking, entity disambiguation, entity chain fingering, entity alignment, attribute alignment, co-reference resolution... (Have you seen Very dizzy)
Entity link/entity alignment/entity link refers to : These three are the same thing, referring to the same entity (may have different descriptions) of different data sources pointing to the same object for alignment.
Entity disambiguation : judging whether entities of the same name in the knowledge base represent different meanings, which can be understood as solving the polysemy phenomenon of the entity concept. The classic example is that "apple" refers to fruits or mobile phones. Entity disambiguation is a subtask under entity linking.
Attribute alignment : Combine different descriptions of the same attribute.
Co-reference resolution : whether there are other named entities in the knowledge base that have the same meaning as the current entity.
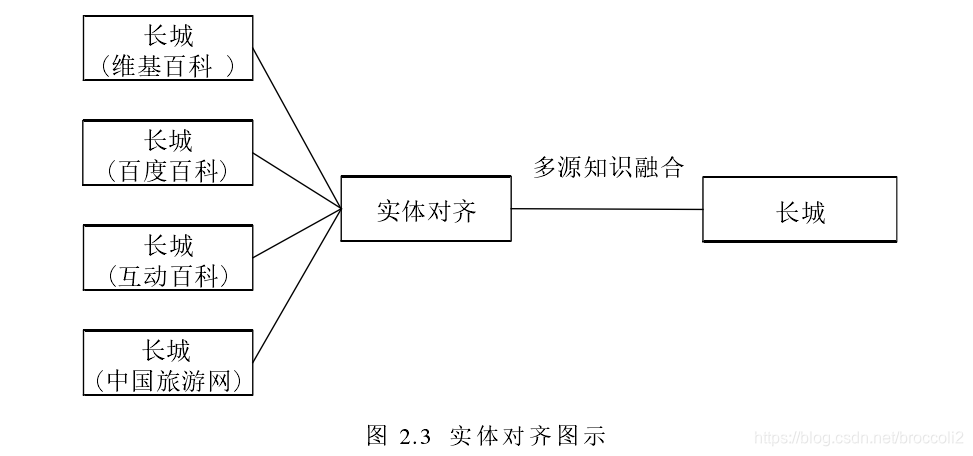
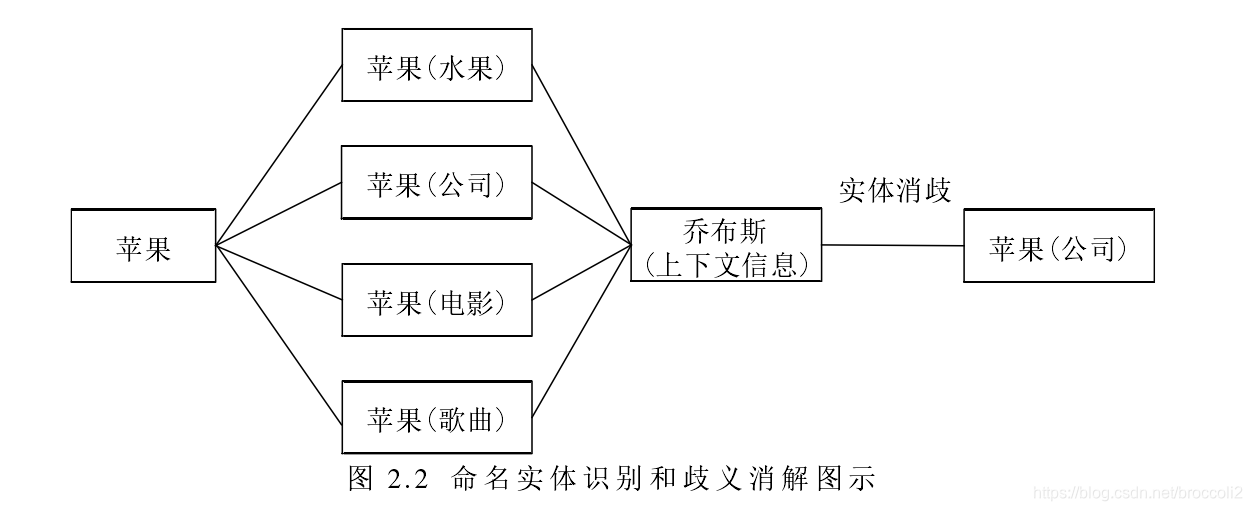
The general process of entity linking:
1. Extract entity referents from the text
2. Perform entity disambiguation and coreference resolution
3. After confirming the correct entity object in the knowledge base, link the entity reference to the corresponding entity in the knowledge base
Knowledge consolidation
Combine the existing knowledge base with a third-party knowledge base. The third-party knowledge base may be a relational database or an external knowledge base. The merging operation mainly includes the fusion of the data layer and the fusion of the model layer.
The integration of the data layer includes the designation, attributes, relationships, and categories of entities. The main problem is how to avoid conflicts between instances and relationships, resulting in unnecessary redundancy;
The integration of the pattern layer is mainly to integrate the obtained ontology into the existing ontology library.
Knowledge processing
Through information extraction, knowledge elements such as entities, relationships, and attributes can be extracted from the original corpus, and then through knowledge fusion, the ambiguity between the entity reference item and the entity object can be eliminated, and a series of basic fact expressions can be obtained. However, the fact itself is not equal to knowledge. In order to finally obtain a structured and networked knowledge system, one needs to go through the process of knowledge processing. Knowledge processing mainly includes three aspects: ontology construction , knowledge reasoning and quality evaluation .
Ontology construction
That is, the construction of the ontology concept template of the pattern layer is usually formulated by domain experts, or through entity similarity calculation, after rough classification, and then manually obtained by relevant statistical induction.
Knowledge reasoning
Most of the relationships between the knowledge graphs are incomplete, and the missing values are very serious. Knowledge reasoning refers to starting from the existing entity relationship data in the knowledge base, performing computer inference, establishing new associations between entities, thereby expanding and enriching the knowledge network . Knowledge reasoning is an important means and key link in the construction of knowledge graphs. Through knowledge reasoning, new knowledge can be discovered from existing knowledge. Suppose, A’s child Z and B have child Z, then the relationship between A and B is likely to be a spouse relationship
The object of knowledge inference is not limited to the relationship between entities, but can also be the attribute value of the entity, the conceptual hierarchical relationship of the ontology, etc.
Knowledge reasoning methods can be divided into two categories: logic-based reasoning and graph-based reasoning .
Logic-based reasoning mainly includes first-order logic predicates , description logic and rule-based reasoning .
Rule-based reasoning can use a special rule language, such as SWRL (semantic Web rule language).
Graph-based reasoning methods are mainly based on neural network models or Path Ranking algorithms . The basic idea of the Path Ranking algorithm is to treat the knowledge graph as a graph (using entities as nodes and relationships or attributes as edges), starting from the source node, and performing a random walk on the graph. If the target node can be reached through a path, then It is speculated that there may be a relationship between the source and destination nodes.
Quality assessment
Quantify the credibility of knowledge, and by discarding knowledge with low confidence, the quality of the knowledge base can be guaranteed.
Knowledge update
Including the update of the concept layer and the update of the data layer
- The update of the concept layer means that new concepts are obtained after adding data, and the new concepts need to be automatically added to the concept layer of the knowledge base
- The update of the data layer is mainly to add or update entities, relationships, and attribute values. The update of the data layer needs to consider the reliability of the data source, the consistency of the data (whether there are contradictions or redundancy, etc.) and other reliable data sources, and select Facts and attributes that appear frequently in each data source are added to the knowledge base.
There are two ways to update the content of the knowledge graph:
- Comprehensive update: refers to constructing a knowledge graph from scratch with all updated data as input. This method is relatively simple, but it consumes a lot of resources and requires a lot of human resources to maintain the system;
- Incremental update: taking the current new data as input, adding new knowledge to the existing knowledge graph. This method consumes less resources, but still requires a lot of manual intervention (defining rules, etc.), so it is very difficult to implement.
------------------------------------------------------
Related reference links:
https://zhuanlan.zhihu.com/p/84861905 (zh recommended)
Knowledge integration:
https://blog.csdn.net/pelhans/article/details/80066810
Knowledge reasoning https://zhuanlan.zhihu.com/p/89803165
Entity link https://zhuanlan.zhihu.com/p/88766473
KBQA :https://m.sohu.com/a/163278588_500659/?pvid=000115_3w_a