Lecturer _ @ Wang Xiaochun
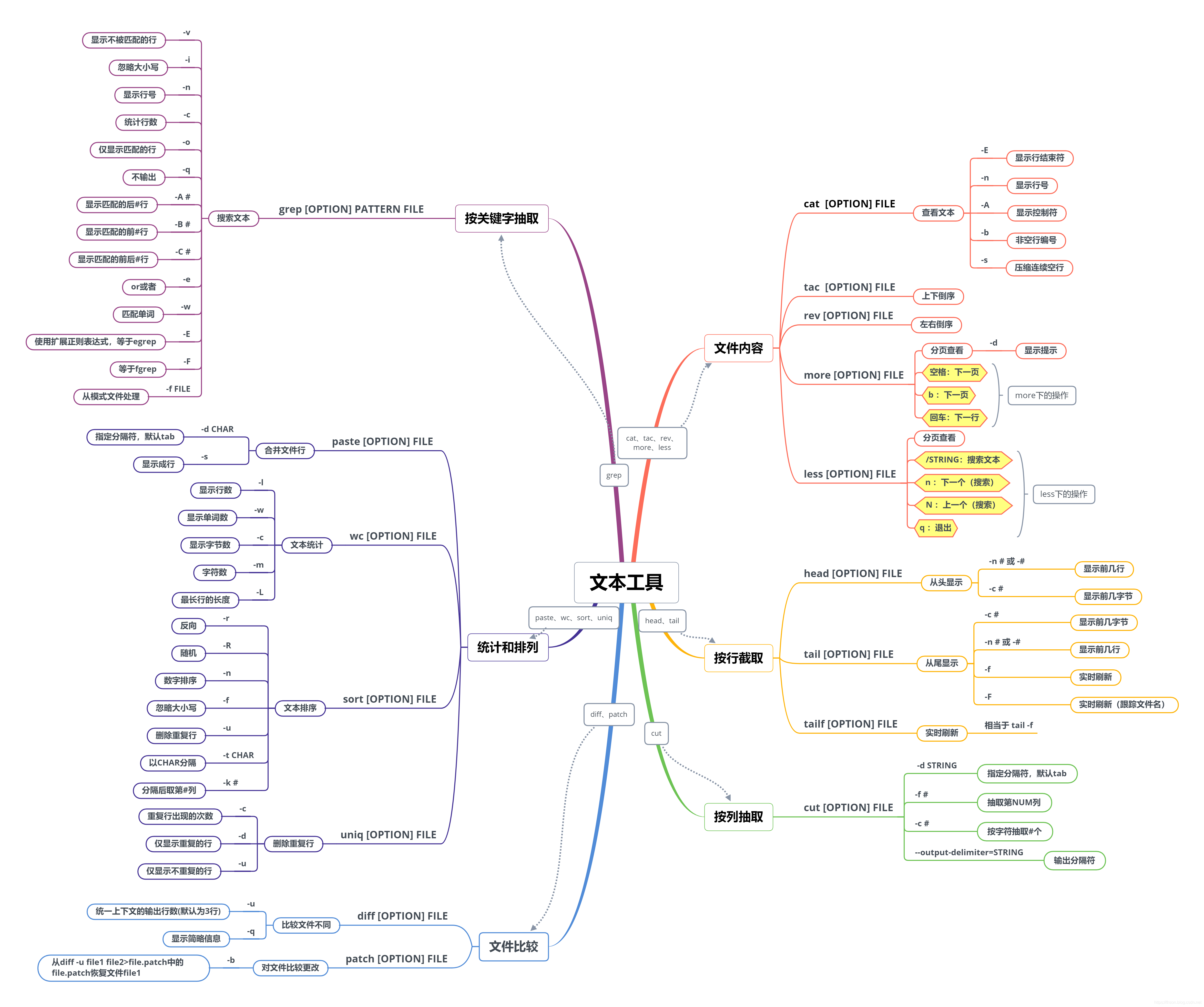
▼ Text tool ▷ document capture tools ● File contents : less, more and CAT, tac, Rev ● File interception : head and tail ● extraction columns : Cut, Paste ● Keywords : grep
file 查看文本文件
[OPTION]
meaning
-E$ Display line endings
-nShow Line Numbers
-ADisplay control character
-bNon-empty row number
-sConsecutive blank lines into one line
[ root@CentOS7 dir1] $cat f1[ root@CentOS7 dir1] $cat -E f1[ root@CentOS7 dir1] $tac f1[ root@CentOS7 dir1] $rev f1file 分页查看
[OPTION] meaning
-dTips page display
b
上一页
Blank 下一页
Enter 下一行
file 分页查看/ STRING `搜索文本` `下一个(搜索)` N `下一个(搜索)` `退出` * man命令使用less命令
file
[OPTION]
meaning
c NUM 选取前num字节
-n NUM 选取前num行
[ root@CentOS7 dir1] $head -n 3 /etc/passwd` 生成随机密码` [ root@CentOS7 dir1] $cat /dev/urandom | tr -dc [ :alnum:] | head -c 8[ root@CentOS7 dir1] $
[OPTION] meaning
c NUM 选取前num字节
-n NUM 或 -num 选取前num行
-f
实时刷新文件
-F
实时刷新文件/跟踪文件名
tailf = tail -f[ root@CentOS7 dir1] $tail -n 3 /etc/passwdfile
[OPTION] meaning
-d STRING
指定分隔符string,默认tab
NUM t 第num列
c NUM 按字符切割
–output-delimiter=STRING
输出分隔符string
#: The first field # # # [#]: a plurality of discrete fields, e.g. 1,3,6 # - #: a plurality of consecutive fields, for example 1-6 in combination: 1-3, 7
[ root@CentOS7 dir1] $cut -d : -f 1 /etc/passwd` 按字符分隔` [ root@CentOS7 dir1] $cat f4[ root@CentOS7 dir1] $cut -c2-3 f4.. .
[ tomcat@centos7 dir] $ echo 12345678 | cut -c 1-7Paste 7. The [the OPTION] File merge the two files into one row counterparts column number
[OPTION] meaning
-d CHAR
指定分隔符,默认tab
-s
显示成行
[ root@CentOS7 dir1] $paste -d: f1 f3▷ text analysis tool Text statistics: wc organize text: sort compare files: diff and patch
file
[OPTION] meaning
-l
行数
-w
单词数
-c
字节数
-m
字符数
-L
最长行的长度
[ root@CentOS7 dir1] $wc /etc/passwd| | | |
` 行数` ` 字数` ` 字节数` ` 文件名` [ root@CentOS7 dir1] $ls /run/media/root/CentOS\ 7\ x86_64/Packages/*.rpm | wc -lfile 文本排序
[OPTION] meaning
-r
反向
-R
随机
-n
数字
-f 忽略大小写
-u 删除重复行
-t CHAR
以CHAR为分隔符
NUM -k 分隔后的第NUM列
Uniq 10. [OPTION] file 删除重复行
[OPTION] meaning
-c 重复行出现次数
-d
仅显示重复的行
-u 仅显示不重复的行
file1 file2 [ root@CentOS7 dir1] $diff - u f1 f2
-- - f1 2019 - 05 - 03 16 : 33 : 25.294186421 + 0800
++ + f2 2019 - 05 - 03 15 : 48 : 55.998025353 + 0800
@@ - 1 , 2 + 1 , 5 @@
- wang
- jibill
+ 1
+ 2
+ 3
+ 4
+ 5
`复原文件` - u f1 f2 > file. patch- b f1 file. patch
STRING file
[OPTION] meaning
-v 显示不被匹配的行
-i
忽略大小写
-n 显示行号
-c 统计行数
-O 仅显示匹配到的STRING
-q
不输出
-A NUM 显示后NUM行
-B NUM 显示前NUM行
NUM -C 显示前后NUM行
-e
or
-w 匹配单词
-E
使用ERE,扩展正则表达式,egrep
-F fgrep,不支持正则表达式
-f FILE
从模式文件处理
to sum up
▼ Regular Expressions Regular Expressions:
The basic regular expressions: BRE Extended regular expressions: ERE 元字符:字符匹配、匹配次数、位置锚定、分组
字符匹配
匹配次数
位置锚定
.匹配单个字符
*匹配前面字符>0次
^行首
[]中括号里任意字符
.*匹配任意长度任意字符
$行尾
[^]排除中括号里任意字符
\?匹配前面字符0/1次
^$空行
[:alnum:]字母和数字
\+匹配前面字符>1次
\< 或 \b词首
[:digit:]数字
\{n\}匹配前面字符n次
\> 或 \b词尾
[:alpha:]字母
\{m,n\}匹配前面至少m次,最多n次
\<WORD\>整个单词
[:lower:]小写字母
{,n\}匹配前面字符最多n次
[:upper:]大写字母
{n,\}匹配前面字符最少n次
分组
[:blank:]空白字符(空格和tab)
\(WORD\)字符串做为整体
[:space:]水平和垂直空白字符
\|或者
[:cntrl:]不可打印控制字符
\1 \2分组引用
[:graph:]要打印的非空字符
[:print:]要打印字符
[:punct:]标点符号
字符匹配
匹配次数
位置锚定
.匹配单个字符
*匹配前面字符>0次
^行首
[]中括号里任意字符
.*匹配任意长度任意字符
$行尾
[^]排除中括号里任意字符
?匹配前面字符0/1次
^$空行
[:alnum:]字母和数字
+匹配前面字符>1次
\< 或 \b词首
[:digit:]数字
{n}匹配前面字符n次
\> 或 \b词尾
[:alpha:]字母
{m,n}匹配前面至少m次,最多n次
\<WORD\>整个单词
[:lower:]小写字母
{,n}匹配前面字符最多n次
[:upper:]大写字母
{n,}匹配前面字符最少n次
分组
[:blank:]空白字符(空格和tab)
(WORD)字符串做为整体
[:space:]水平和垂直空白字符
|或者
[:cntrl:]不可打印控制字符
\1 \2分组引用
[:graph:]要打印的非空字符
[:print:]要打印字符
[:punct:]标点符号
file 相当于grep -E [OPTION] PATTERN FILE
1、找出ifconfig “网卡名” 命令结果中本机的IPv4地址(答案 )答案 )答案 )答案 )答案 )答案 )答案 )答案 )答案 )答案 )答案 )答案 )答案 )答案 )答案 )答案 )答案 )答案 )
1、找出ifconfig “网卡名” 命令结果中本机的IPv4地址
ifconfig ens33 | egrep -o "(([1-9]?[0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])[.]){3}([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])[[:blank:]]"
2、查出分区空间使用率的最大百分比值
[ root@centos7 dir] $df | egrep -o "[0-9]{1,3}%" | tr -d %| sort -rn| head -13、查出用户UID最大值的用户名、UID及shell类型
[ root@centos7 dir] $cat /etc/passwd | sort -t: -k3 -n | tail -1| cut -d: -f1,3,74、查出/tmp的权限,以数字方式显示
[ root@centos7 dir] $stat -c %a /tmp5、统计当前连接本机的每个远程主机IP的连接数,并按从大到小排序
netstat -tun | grep ESTAB | tr -s ” ” : | cut -d: -f6 | sort -nr | uniq -c
6、显示三个用户root、mage、wang的UID和默认shell
[ root@centos7 dir] $cat /etc/passwd| cut -d: -f1,3,7| egrep "wang|mage|root" 7、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一个小括号的行
[ root@centos7 dir] $cat /etc/rc.d/init.d/functions | egrep "^[[:alpha:]]*_?\("
checkpid( ) {
daemon( ) {
killproc( ) {
pidfileofproc( ) {
.. .
8、使用egrep取出/etc/rc.d/init.d/functions中其基名
[ root@centos7 dir] $echo /etc/rc.d/ini.d/functions | egrep -o "/[^/]*" | tail -1| tr -d /9、使用egrep取出上面路径的目录名
[ root@centos7 dir] $echo /etc/rc.d/ini.d/functions | egrep -o "^/.*/" 10、统计last命令中以root登录的每个主机IP地址登录次数
[ root@centos7 dir] $last | egrep -o "(([1-9]?[0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])[.]){3}([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])" | sort -n| uniq -c11、利用扩展正则表达式分别表示0-9、10-99、100-199、200-249、250-255
[ 0-9] 、[ 1-9] [ 0-9] 、1[ 0-9] [ 0-9] 、2[ 0-4] [ 0-9] 、25[ 0-5]
12、显示ifconfig命令结果中所有IPv4地址
[ root@centos7 dir] $ifconfig | egrep -o "(([1-9]?[0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])[.]){3}([1-9]?[0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])" 13、将此字符串:welcome to magedu linux 中的每个字符去重并排序,重复次数多的排到前面
[ root@centos7 dir] $echo "welcome to magedu linux" | grep -o [ [ :alpha:] ] | sort | uniq -c| sort -t " " -k 1 -r14、复制/etc/profile至/tmp/目录,用查找替换命令删除/tmp/profile文件中的行首的空白字符
:%s@^[ [ :space:] ] *@@gc
15、复制/etc/rc.d/init.d/functions文件至/tmp目录,用查找替换命令为/tmp/functions的每行开头为空白字符的行的行首添加一个#号
:%s@^[[:blank:]]@#@g
16、在vim中设置tab缩进为4个字符
set ts= 4
17、复制/etc/rc.d/init.d/functions文件至/tmp目录,替换/tmp/functions文件中的/etc/sysconfig/init为/var/log
:%s
18、删除/tmp/functions文件中所有以#开头,且#后面至少有一个空白字符的行的行首的#
:%s@[ [ :space:] ] *