1.grep
meaning:
grep (Globally search a Regular Expression and Print) is a powerful text search tool that can search for text using specific pattern matching (including regular expressions) and output matching lines by default.
The Unix grep family includes grep, egrep and fgrep. The commands of egrep and fgrep are only slightly different from grep. egrep is an extension of grep, supporting more re meta characters, fgrep is fixed grep or fast grep, they treat all letters as words, that is, meta characters in regular expressions represent their own literal meaning , No longer special. Linux uses the GNU version of grep. It is more powerful. You can use the functions of egrep and fgrep through the -G, -E, and -F command line options.
The way grep works is this, it searches for string templates in one or more files. If the template includes spaces, it must be quoted, and all strings after the template are treated as file names. The search results are sent to standard output without affecting the content of the original file. grep can be used in shell scripts because grep returns a status value to indicate the status of the search. If the template search is successful, it returns 0, if the search is unsuccessful, it returns 1, if the search file does not exist, it returns 2. We can use these return values to perform some automated text processing.
grep format
grep match condition processing file
Example:
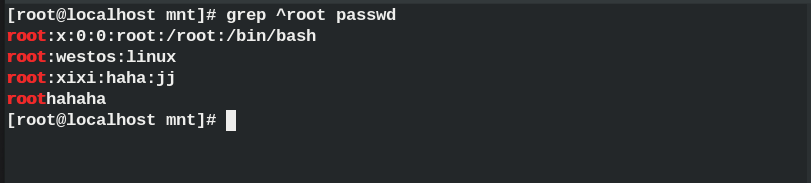
grep root passwd ## Filter root keyword
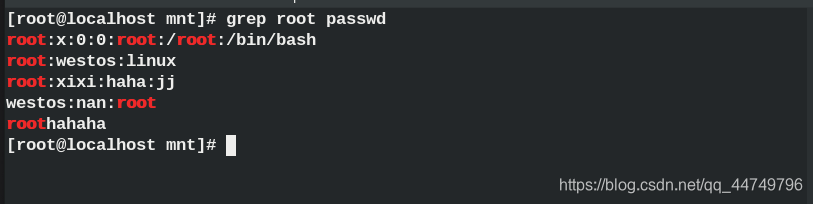
grep -i root passwd ## Ignore case
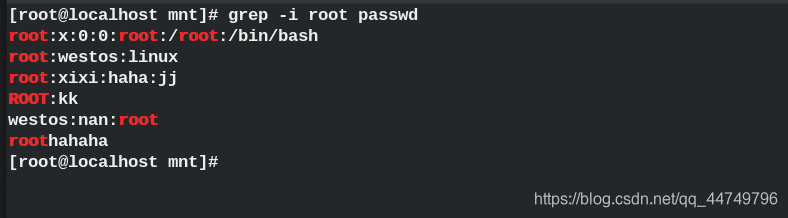
grep ^ root passwd ## Start with root
grep root $ passwd ## End with root

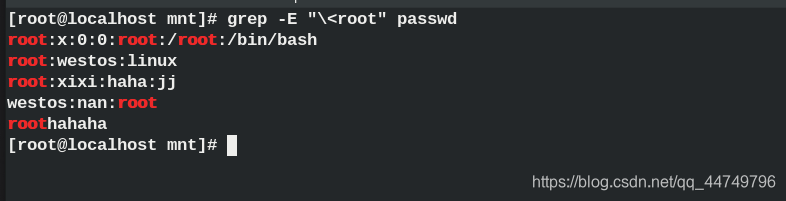
grep -E “\ <root” passwd ## The root character must not have the character
grep -E "root \>" passwd ## The root must not have the character

grep -number ## Display the filter line and the upper and lower lines
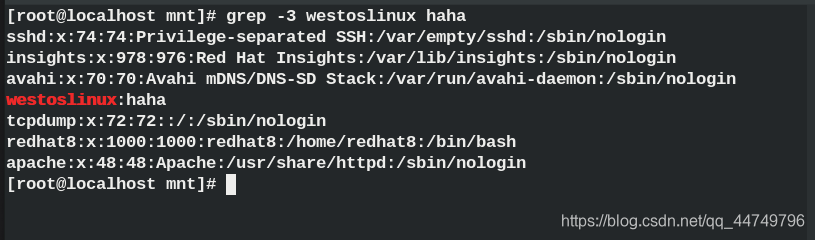
grep -n ## Display the matching line No.

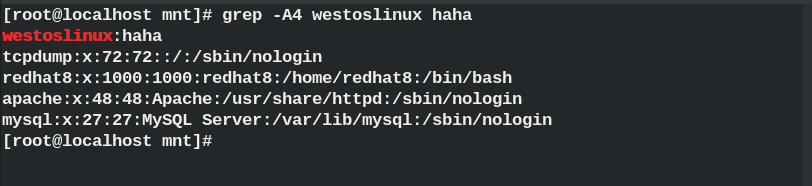
grep -A ## Display the filter line and the lines below the filter line
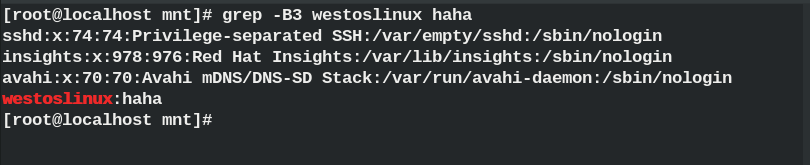
grep -B #Display the filter line and the lines above the filter line
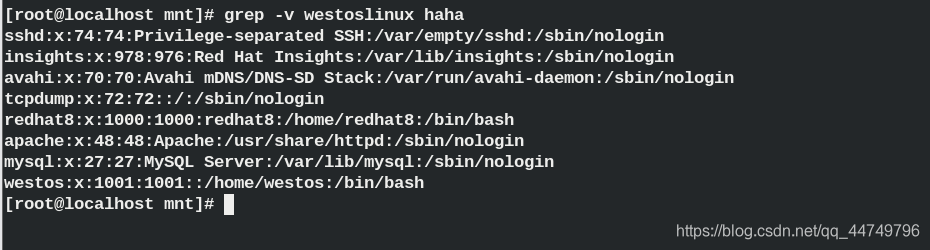
grep -v ## Reverse filter, display the lines except the filter line
grep character number matching rules
Example:
w....s ##以w开头s结尾中间4个任意字符
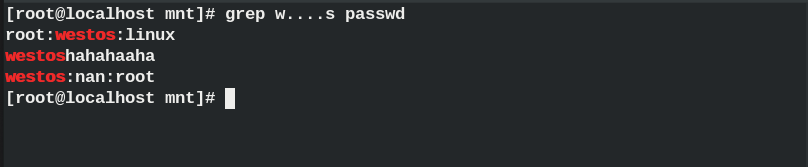
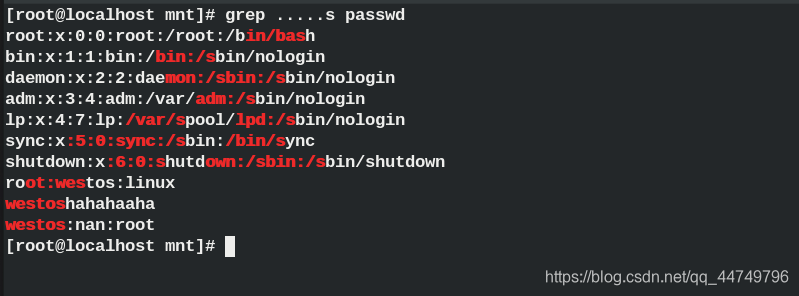
.....s ##以s结尾,前面5个任意字符
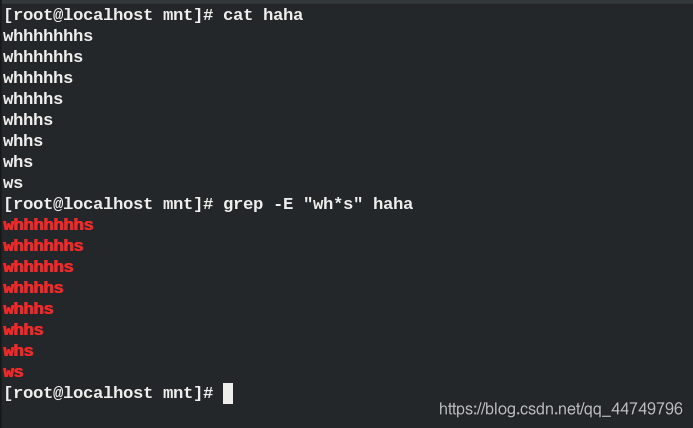
* ##字符出现0次到任意次
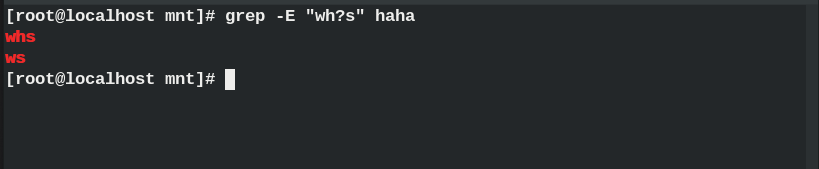
? ##0到1次

{n} ## appears n times
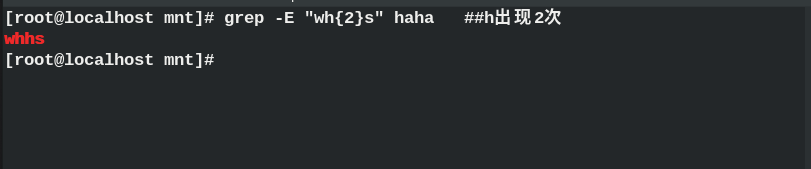
{m, n} ## appears m to n times
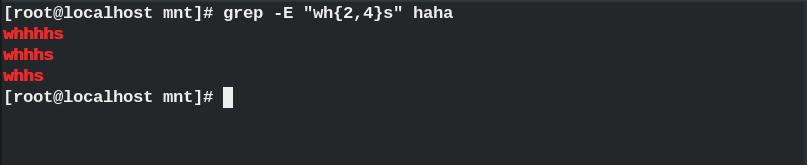
{0, n} ## Occurrence 0-n times
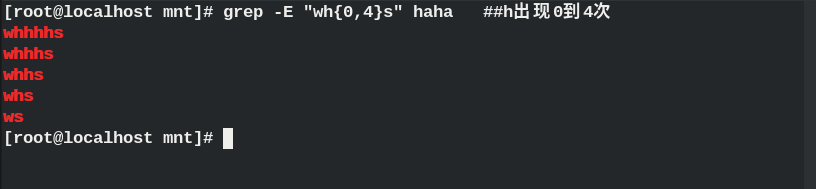
{, n} ## Occurrence 0-n times
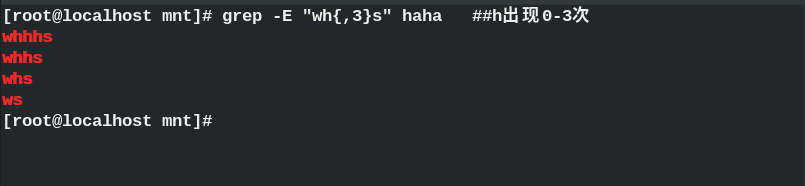
{m,} ## appears at least m times

(lee) {2} ## lee string appears twice

Practice script
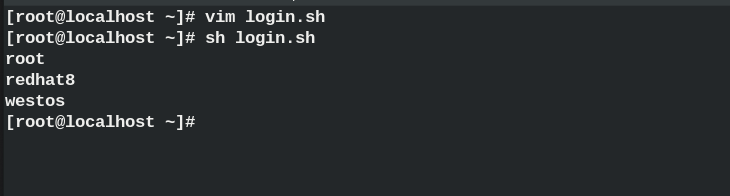
Please display the user name in the system that can be switched by the su command

2.sed (stream editor)
(1) Concept of sed command
sed is a linux command, the function is similar to awk, the difference is that sed is simple, the function of column processing is worse, the function of awk is complex, and the function of column processing is stronger.
sed is used to manipulate text in pure ASCII code.
During sed processing, the current line is stored in a temporary buffer, called "pattern space", and you can specify which lines are processed only.
sed processing that meets the pattern conditions, not processing that does not meet the conditions, after the processing is completed, the content of the buffer is sent to the screen, and then the next line is processed, so that it repeats continuously until the end of the file.
The original content was placed on the disk. Now when the sed command is used for processing, the content is dropped into a place in the memory for user processing. This processing space is also called the pattern space.
(2) Command format
sed parameter command processing object
sed parameter processing object -f processing rule file
(3) Handling of characters
| p | display |
|---|---|
| d | delete |
| a | Add to |
| c | replace |
| w | Write the matching line to the specified file |
| i | insert |
| r | Integrated document |
1) p
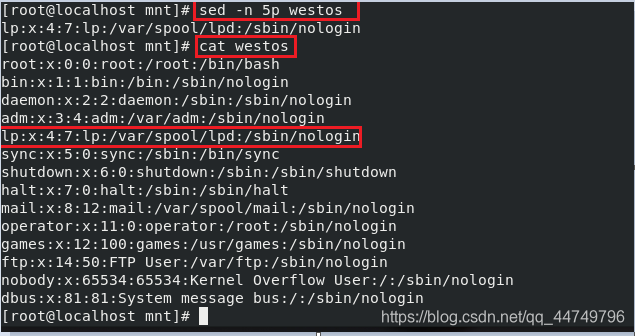
sed -n 5p westos ##显示westos中的第五行
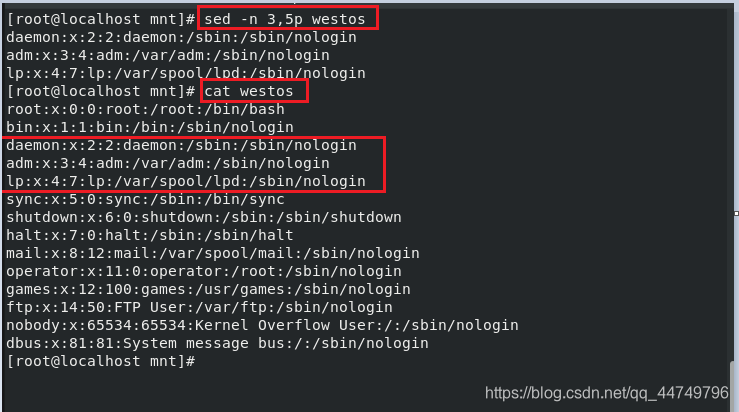
sed -n 3,5p westos ##显示westos文件中的3到5行
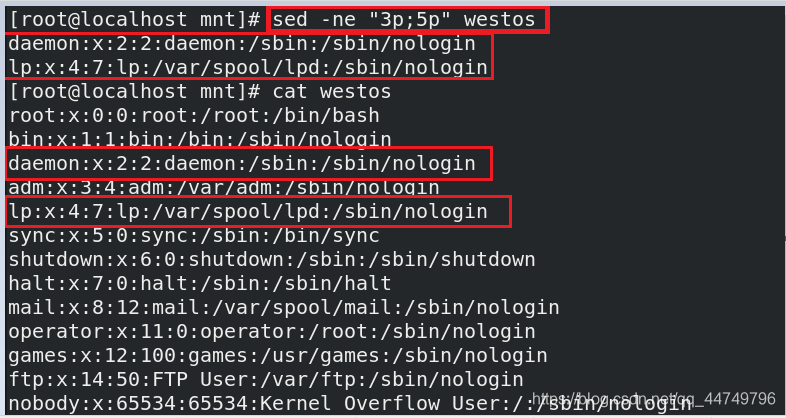
sed -ne "3p;5p" westos ##显示3行和5行
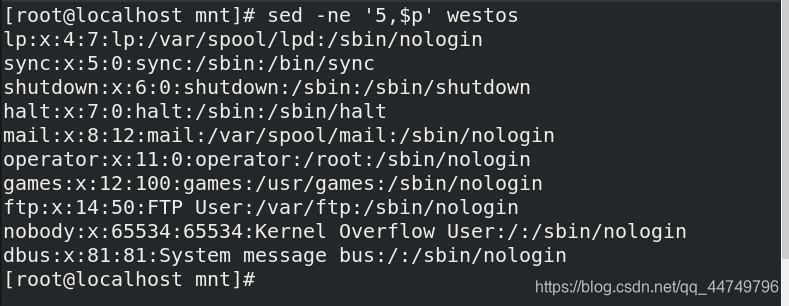
sed -ne '5, $ p' westos ## Display 5 to the last line in the westos file
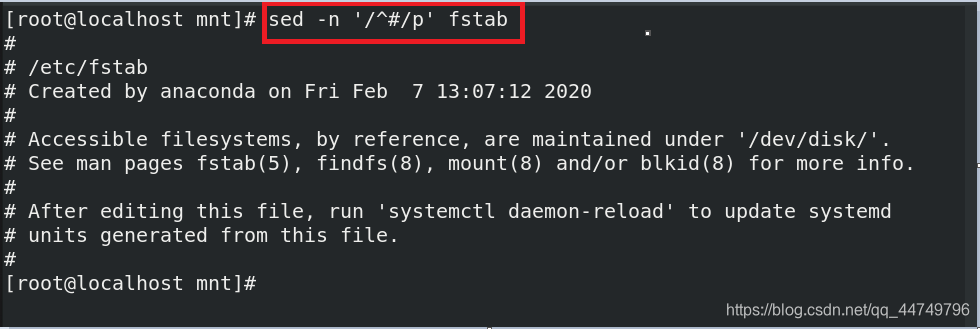
sed -n '/^#/p' fstab ##显示fstab文件中以#开头的行
2) d ## Delete
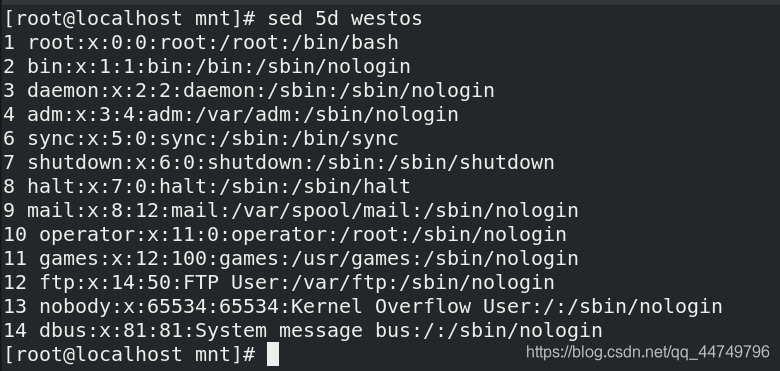
sed 5d westos ##删除westos文件中的第五行
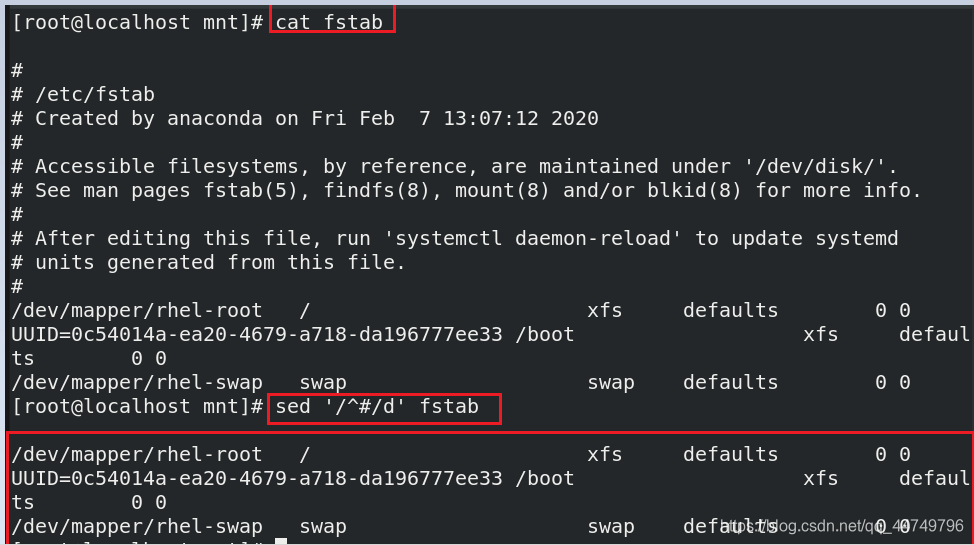
sed '/^#/d' fstab ## fstab文件中以#开头的行
sed '/^UUID/!d/' fstab ##除了以UUID开头的行不删,其他行都删
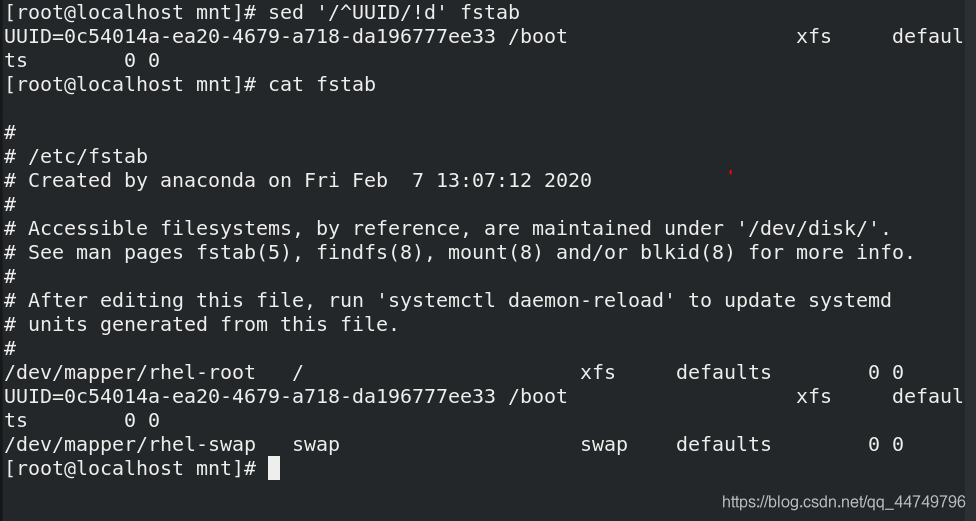
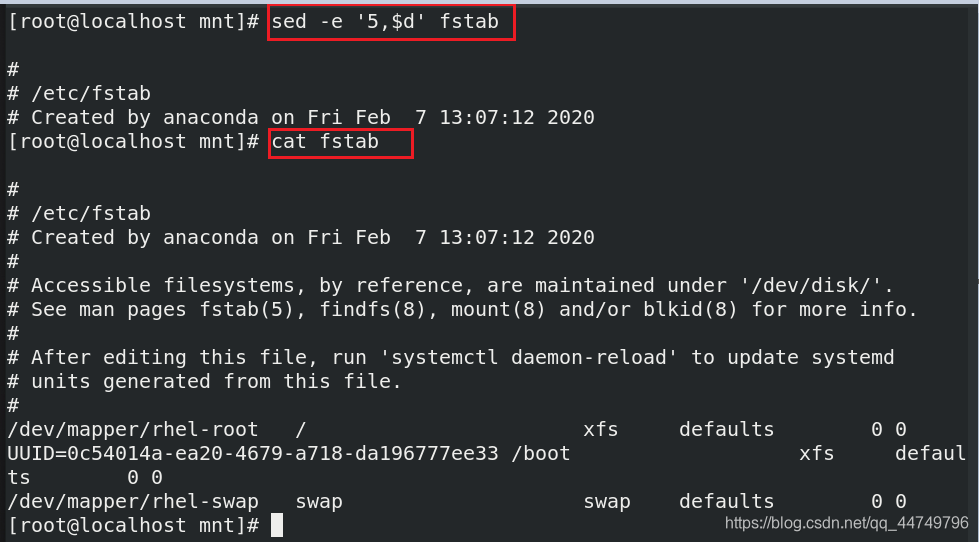
sed -e '5,$d' westos ##删除第五行到最后一行
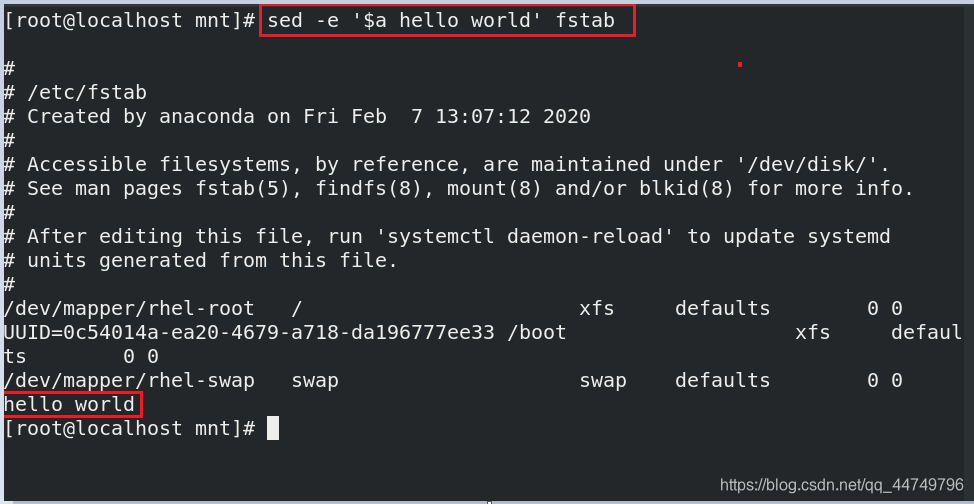
3) a ## Add
sed -e '$a hello world' fstab ##在fstab文件最后添加一行hello world
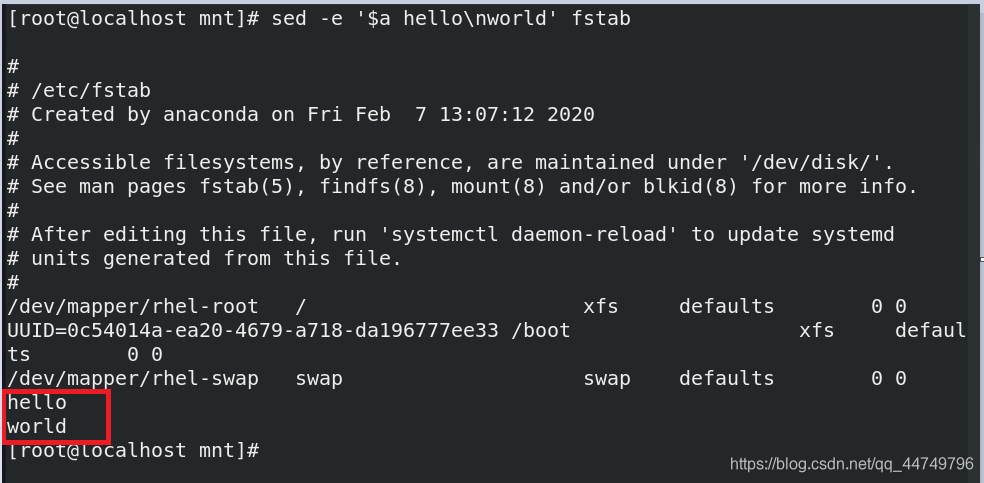
sed -e '$a hello\nworld' fstab ##在fstab文件最后添加hello world 俩行
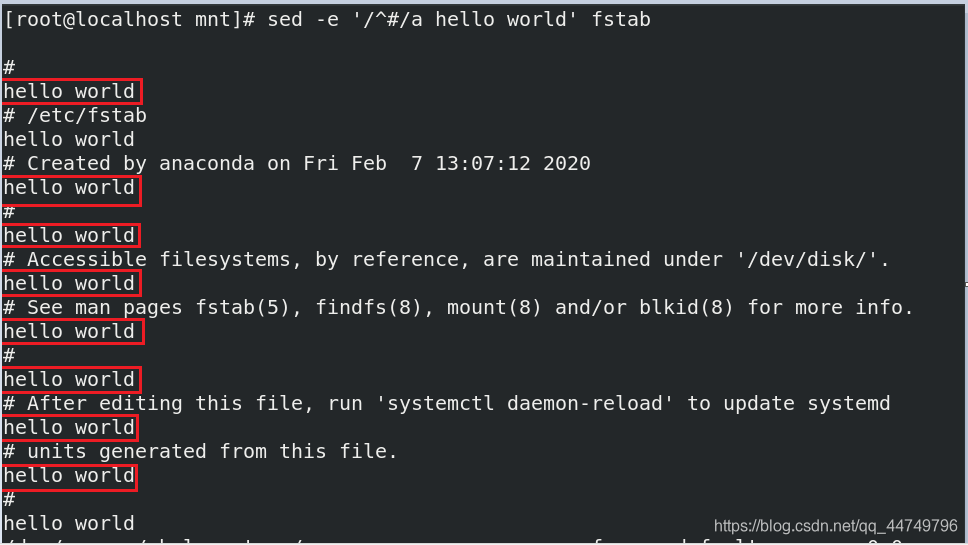
sed -e '/^#/a hello world' fstab ##在fstab文件中每一行以#开头的行下面添加一串 hello world
4) c ## replace
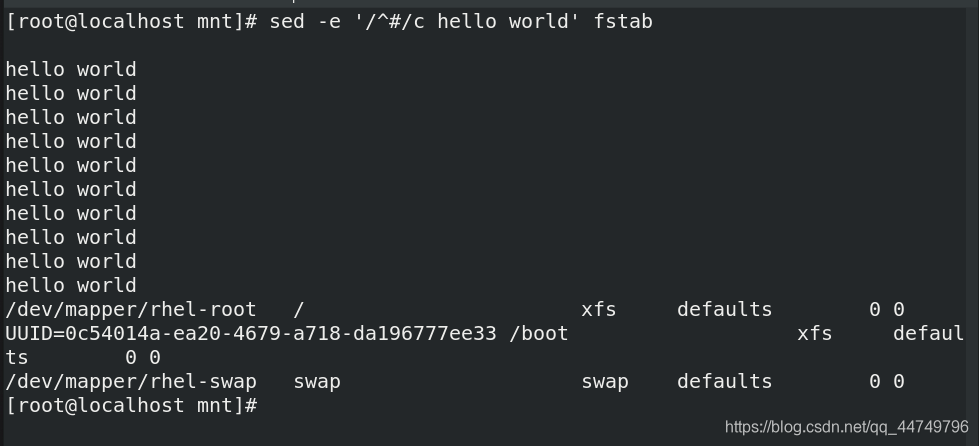
sed -e '/^#/c hello world' fstab ##讲fstab文件中以#开头的行替换成hello world
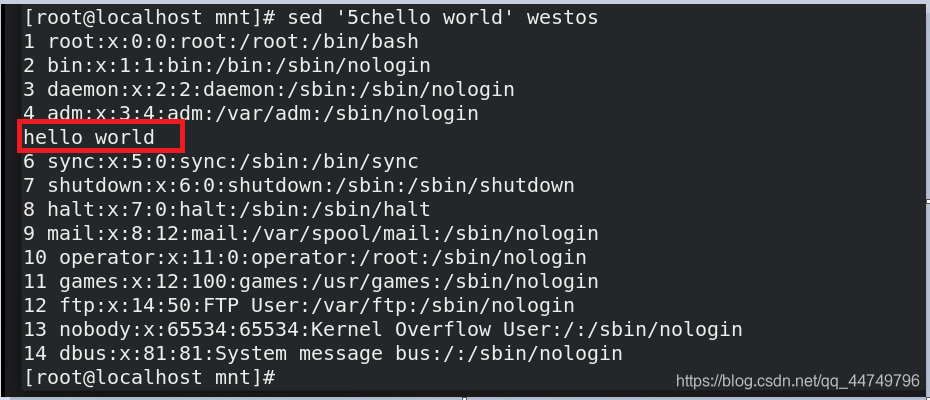
sed '5chello world' westos ##讲westos文件中的第5行替换成hello world
5) w ## Write the matching line to the specified file
sed '/^UUID/w westosfile' westos ##把westos中UUID开头的行写入westosfile中
6) i ## insert
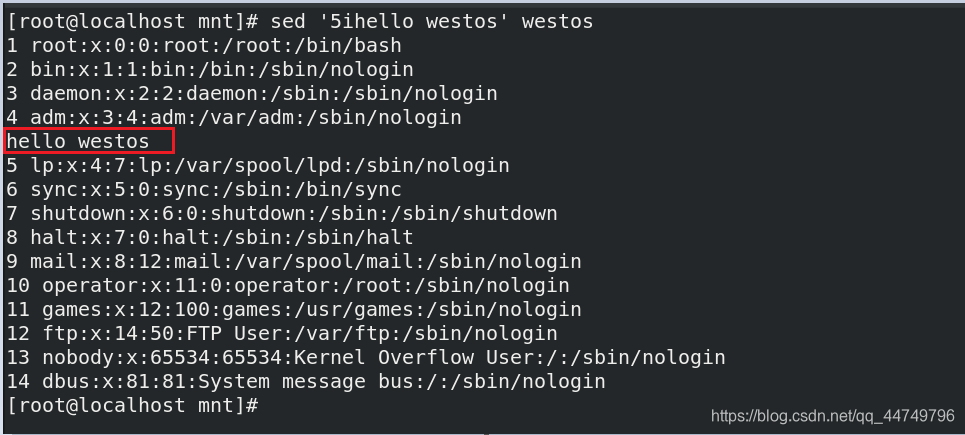
sed '5ihello westos' westos ##在westos 文件中的第五行上面插入 hello westos行
7) r ## integrated file
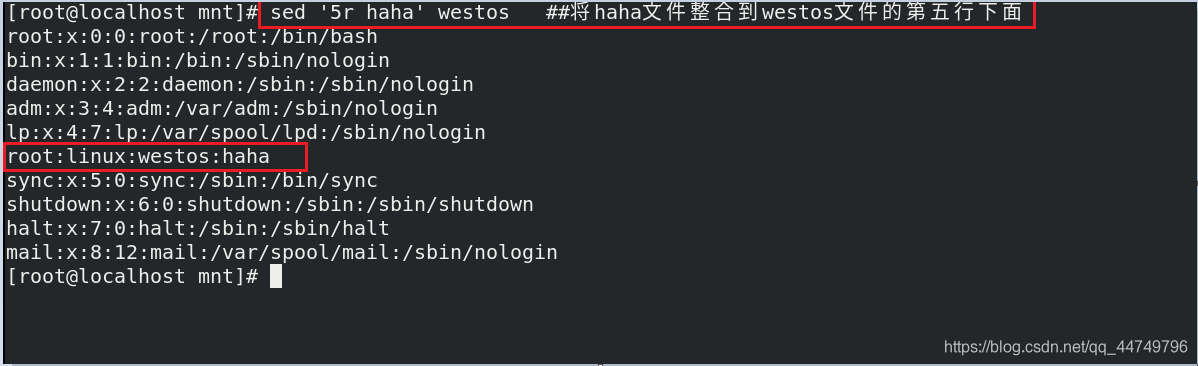
sed '5r haha' westos ##将haha文件整合到westos文件中第五行的下面
(4) Character replacement
1)
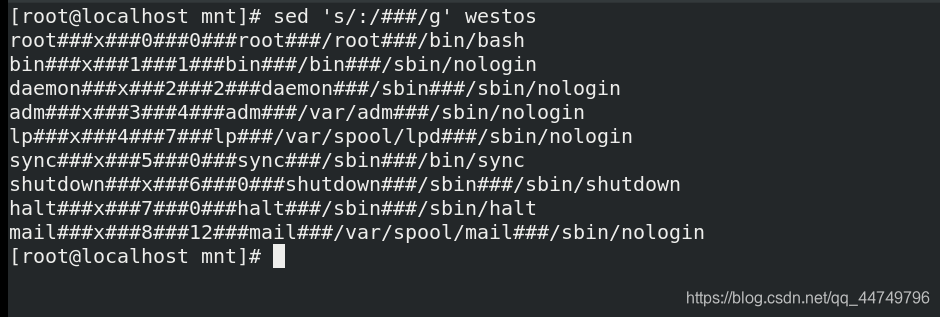
sed 's/:/###/g' westos ##将westos文件中所有的:替换成###,其中g代表所有列,不写g将默认第一列
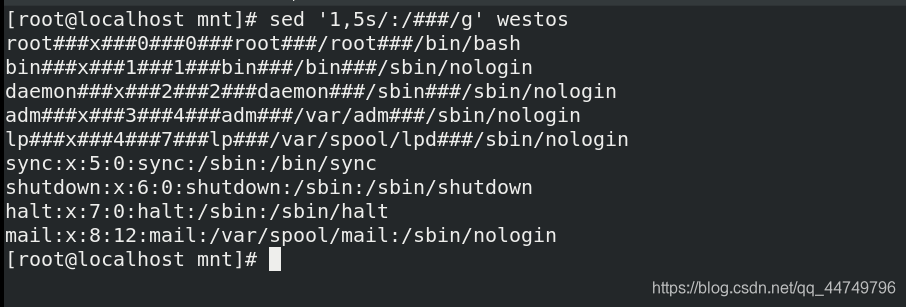
sed '1,5s/:/###/g' westos ##将westos文件中1-5行的:替换成###
3)
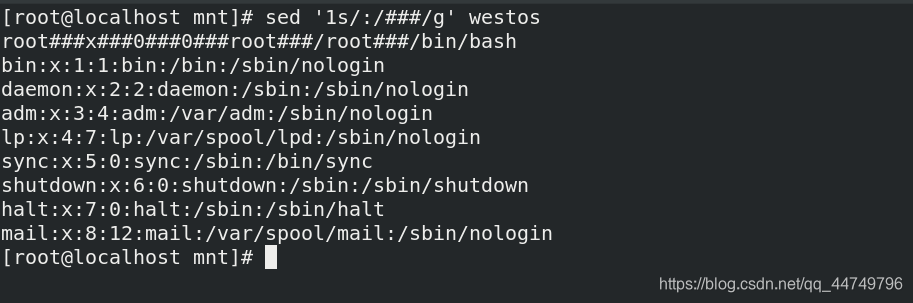
sed '1s/:/###/g' westos ##将westos文件中第一行的:替换成###
4)
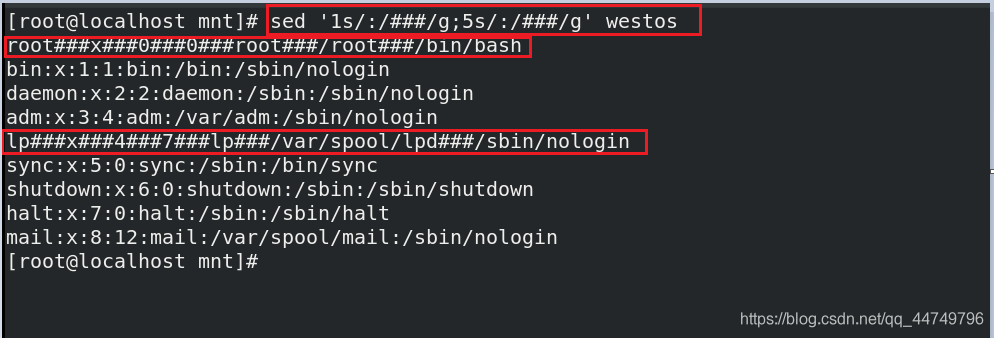
sed '1s/:/###/g;5s/:/###/g' westos ##将westos文件中的第一行和第五行中的:替换成###
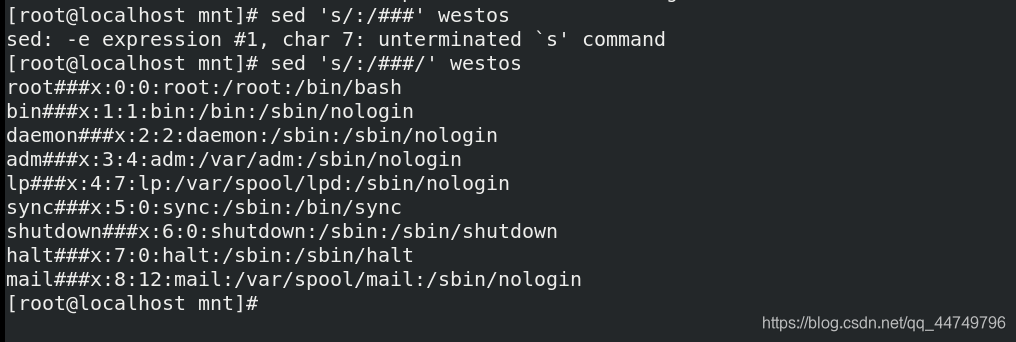
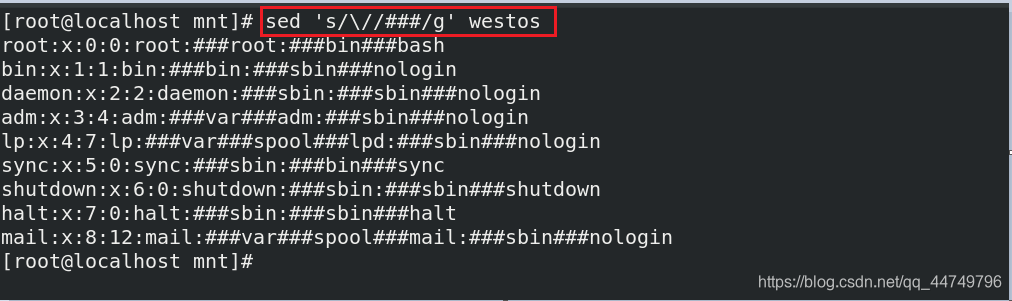
sed 's/\//###/g' westos ##将westos文件中的/转换为###
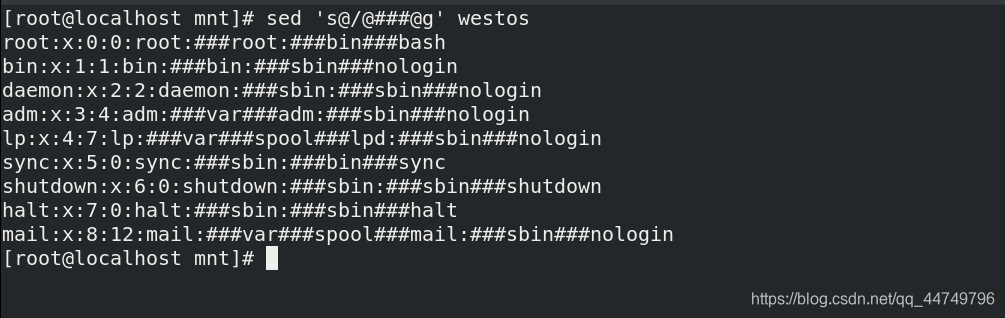
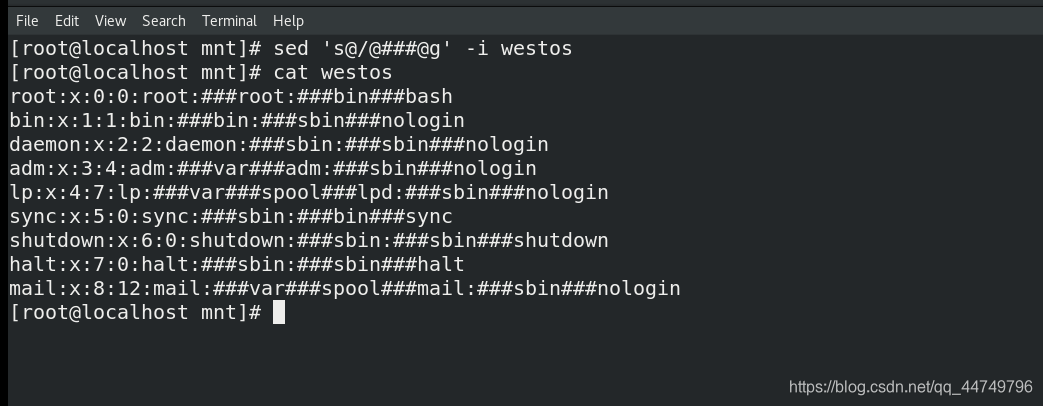
sed 's@/@###@g' westos ##@符号用作分隔符,和/一样,将westos中的/符号转换为###符号
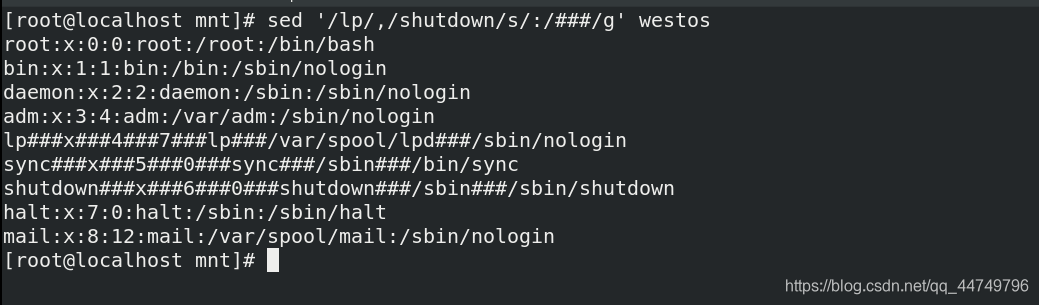
sed '/lp/,/shutdown/s/:/###/g' westos ##将westos文件中的lp到shutdowns行的:替换成###
sed 's@/@###@g' -i westos ##把sed处理的内容保存到westos文件中
3.awk
Instructions: Awk -F separator BEGIN {} {} END {} FILENAME
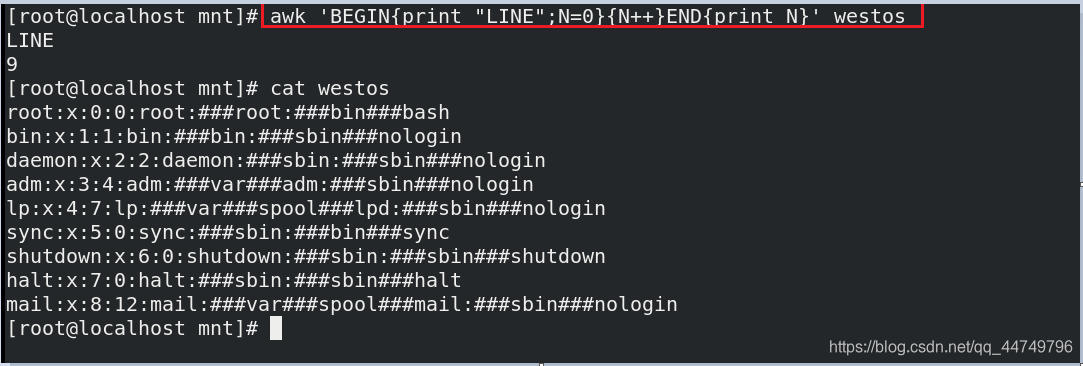
awk 'BEGIN{print "LINE";N=0}{N++}END{print N} westos ##BEGIN是预处理,awk是逐行处理,N++依次+1,可以统计westos文件的行数
NR ## 行 数
NF ## Column 数
FILENAME ## File name
westos ## westos variable value
"westos" ## westos string
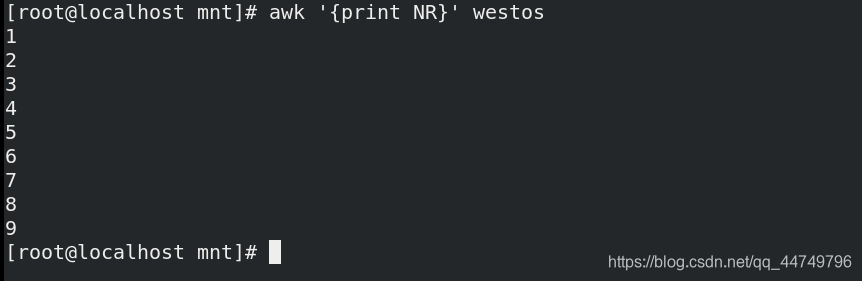
awk '{print NR}' westos ##打印westos文件的行号
awk '{print NF}' westos ##每行打印westos文件的列数,默认-F分隔为空格
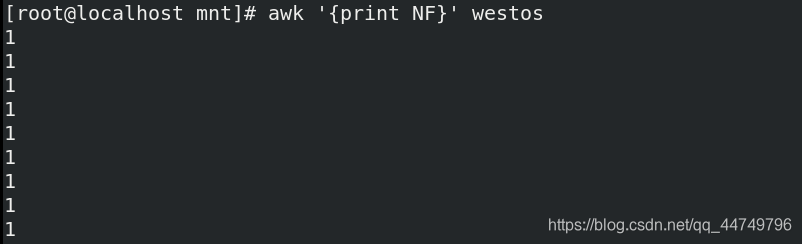
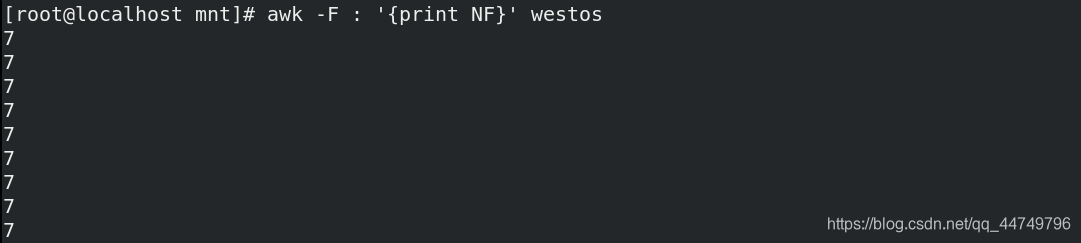
awk -F : '{print NF}' westos ##以:为分隔符,逐行打印westos中的列数
awk -F : '$7~/bash$/{print FILENAME}' /etc/passwd ##将/etc/passwd文件中是以bash结尾的行的文件名称打印出来

Add conditions:
/ Condition 1 | Condition 2 ## Condition 1 or Condition 2
/ Condition 1 || / Condition 2 ## Condition 1 or Condition 2
/ Condition 1 &&& / Condition 2 ## Condition 1 and Condition 2
awk -F : '/bash$/{print}' westos ##将westos中以bash结尾的行打印出来
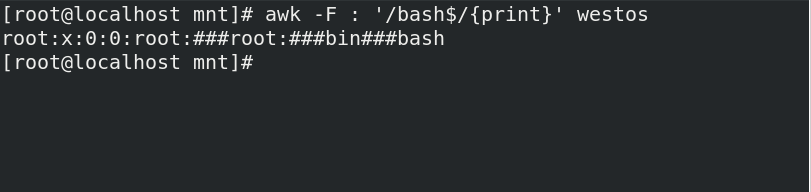
awk -F : '/bash$/{print NF}' westos ##打印westos文件中以bash结尾的行的列数

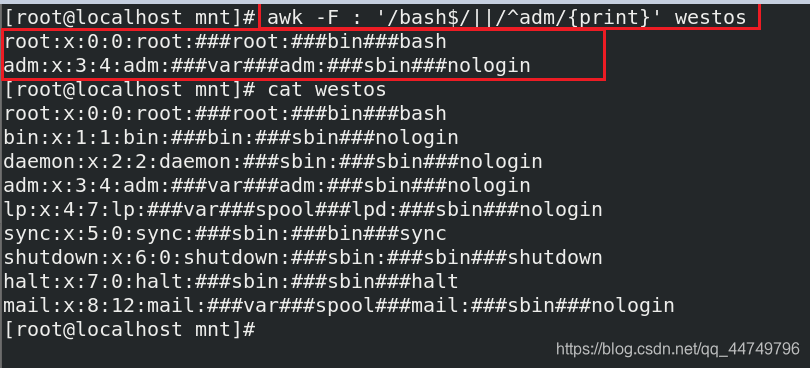
awk -F : '/bash$/||/^adm/{print}' westos ##将westos文件中的以bash结尾的或者adm开头的行打印出来
awk -F '/bash$/&&/^root/{print}' westos ##将westos文件中以bash结尾并且root 开头的行打印出来

| $0 | All columns |
|---|---|
| $1 | first row |
| $2 | the second list |
awk -F '/bash$/&&/^root/{print $1,$7}' westos ##显示打印westos文件中以bash结尾,root 开头行的第一列和第七列

awk -F : '/bash$/&&/^root/{print $0}' westos ##将westos中以bash结尾,root 开头行的所有列打印出来

awk -F '$6!~/home/&&/bash$/{print}' /etc/passwd ##/etc/passwd 文件的第六列没有home关键字并且以bash结尾的行

