1.Presto briefing note
Presto is an open source distributed SQL query engine for interactive analysis query, the amount of data to support GB PB bytes.
Presto is designed and written entirely in order to solve problems like interactive analysis and processing speed commercial data warehouse of this size of Facebook.
Presto enables online data queries, including Hive, Cassandra, relational databases, and proprietary data stores. Presto a query data from multiple data sources are combined, it can be analyzed across the entire organization.
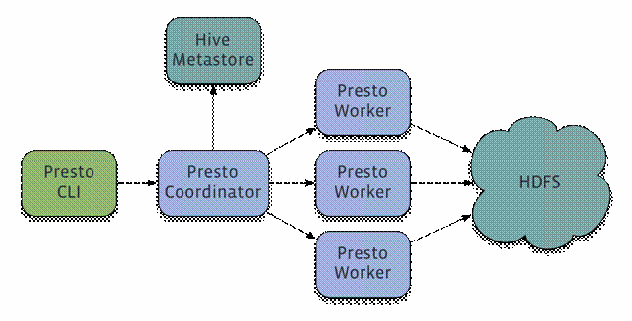
Presto is a run on multiple servers in a distributed system. Complete installation comprising a coordinator and a plurality of worker. Submit a query by the client, to submit to the CLI command line from Presto coordinator. coordinator parse, analyze and execute the query plan, and then distribute the processing queue to worker.
2. official document: https://prestodb.github.io/docs/current/installation.html
3. Download: wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.220/presto-server-0.220.tar.gz
4. unpack, create folders and files
cd /data/bigdata/presto && mkdir etc && touch etc/{config.properties,jvm.config,log.properties,node.properties} && mkdir etc/catalog
5. Modify Profile
etc vim / config.properties # configuration properties: Presto server's configuration information
Each Presto server is both a coordinator is also a worker. But in a large cluster, in a performance reasons, we recommend using a separate machine as coordinator. A coordinator's etc / the config.properties should contain at least the following information: coordinator = to true Node -scheduler.include =-coordinator to false HTTP -server.http.port = 8080 query.max -memory The = 50GB query.max -memory The-per- = the Node 1GB Discovery -server.enabled = to true discovery.uri = HTTP: // ip_ address: 8080 the following configuration is the most basic worker: Coordinator = false HTTP -server.http.port = 8080 query.max= - MEMORY 50GB query.max - MEMORY-per-the Node = 1GB discovery.uri = HTTP: // ip_ Address: 8080 but if you were testing a machine, then this machine will ie as a coordinator, also as a worker. Profile will be as follows: Coordinator = to true Node -scheduler.include-Coordinator = to true HTTP -server.http.port = 8080 query.max -memory The = 5GB query.max -memory The Node-per-= 1GB Discovery -server = .Enabled to true discovery.uri = HTTP: // ip_ address: 8080
To resolve the above configuration items:
coordinator: Specifies whether operation and maintenance Presto (execution of each query management affection is receiving a query from a client) as an example of a coordinator. the Node -scheduler.include- coordinator: whether to allow the scheduling coordinator to work in the service. For large clusters on a node that is the Presto server as coordinator and as worke will reduce query performance. Because if a server is used as a worker, then most of the resources will not be occupied worker, then there would be enough resources for mission-critical scheduling, management and monitoring query execution. HTTP - server.http.port: Specifies the HTTP server port. Presto uses HTTP for all internal and external communications. task.max - MEMORY = 1GB: maximum memory use of a separate task (a portion of a query execution plan will be executed on a specific node). This limits the number of configuration parameters in Group GROUP BY statement, the right size JOIN association relation table, the number of rows in ORDER BY statement number of rows and a window function processing. This parameter should be adjusted according to the number and complexity of queries concurrent queries. If this parameter is set too low, many queries will not be executed; but if set too high will cause the JVM to run out of memory. Discovery -server.enabled: Presto to find all the nodes in the cluster by the Discovery service. In order to be able to find all the nodes in the cluster, each instance of Presto will be at startup to register itself to discovery services. Presto To ease deployment, and do not want to add a new service process, Presto coordinator can run a built-in coordinator inside Discovery service. The Discovery service embedded HTTP server and Presto share and use the same port. discovery.uri: URI Discovery server is. Because Presto coordinator embedded Discovery service enabled, so this is the uri uri Presto coordinator of. Modify example.net: 8080 , according to your actual environment settings that URI. Note: This URI must not end with "/."
etc vim / the jvm.config #JVM configuration: JVM command-line options
-server -Xmx4G -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:+ExitOnOutOfMemoryError
etc vim / the log.properties # Log Level
com.facebook.presto = ABOUT
etc Vim / node.properties # node attributes: configuration information of each node environment
= node.environment Production's # cluster name. All must have the same cluster name in the same cluster node Presto the Node. The above mentioned id = FFFFFFFFFFFF-ffff-ffff- uniquely identifies each ffffffffffff # Presto node. Node.id each node must be unique. Or restart the upgrade process node.id each node in the Presto must remain unchanged. Presto If multiple instances installed on one node (e.g.: Presto plurality of nodes installed on the same machine), then each node must have a unique Presto node.id node.data - the dir = / Data / with BigData / presto_data # position data storage directory, the best kept separate, easy to upgrade presto
etc Vim / Catalog / jmx.properties #Catalog properties: configuration forConnectors (data source) configuration information
connector.name=jmx
etc Vim / Catalog / mysql.properties # data source connected mysql
connector.name=mysql connection-url=jdbc:mysql://mysql_ip:3336 connection-user=root connection-password=xxxxx
6. Run Presto
Background: cd / data / bigdata / presto / bin && ./launcher start
Foreground: cd / data / bigdata / presto / bin && ./launcher run
web monitoring interface: http: // ip_ Address: 8080 / ui /
7.部署presto client:https://prestodb.github.io/docs/current/installation/cli.html
Download: wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.220/presto-cli-0.220-executable.jar
重 命名: cp -r soon-cli-0220-executable.jar soon-cli
Given execute permissions: chmod + x presto-cli
Connecting the source data mysql:
/ Data / with BigData / Presto-CLI --server localhost: 8080 --catalog MySQL --schema moodscat
parameters:
--catalog: Specifies the data source connection, connector.name specified in the etc / catalog / mysql.properties in
--schema: Specifies a database connected to this particular example of the data
8. Perform data query:

