
Author: Huan Xiang
Manbang Group, as an "Internet + Logistics" platform enterprise, undertakes the shipping needs of shippers on one end and connects with truck drivers on the other end to improve freight logistics efficiency. It will be listed on the US stock market in 2021, becoming the first digital freight platform to be listed. According to the company's annual report, in 2021, more than 3.5 million truck drivers completed more than 128.3 million orders on the platform, achieving a total transaction value of GTV 262.3 billion yuan, accounting for more than 60% of China's digital freight platform share. In October 2022, the MAU of the driver version of Yunmanman reached 9.4921 million, and the MAU of the driver version of Wagonmanman was 3.9991 million; the MAU of the owner version of Yunmanman was 2.1868 million, and the MAU of the Wagonbang cargo owner version was 637,800. (The following content is compiled and output by Zikui and Congyan)
Business growth challenges service stability
Manbang Group built its own microservice gateway in the business production environment, which is responsible for north-south traffic scheduling, security protection and microservice governance. At the same time, taking into account the multi-active disaster recovery capability, it also provides services such as priority calls in the same computer room, disaster recovery cross-computer room calls, etc. mechanism. As a front-end component of the microservice architecture, the microservice gateway serves as the traffic entrance for all microservices. When a client request comes in, it will first hit the ALB (load balancing), then go to the internal gateway, and then be routed to the specific business service module through the gateway.
Therefore, the gateway needs to use a service registration center to dynamically discover all microservice instances deployed in the current production environment. When some service instances are unable to provide services due to failures, the gateway can also work with the service registration center to automatically forward requests to healthy ones. On service instances, failover and elasticity are achieved, and a self-developed framework is used to cooperate with the service registration center to realize inter-service calls. At the same time, a self-built configuration center is used to implement configuration management and change push. Manbang Group was the first to adopt open source Eureka and ZooKeeper to build cluster implementation. Service registration center and configuration center, this structure also well undertook the rapid business growth of Manbang Group in the early stage.
However, as the business volume gradually increases, there are more and more business modules, and the number of service registration instances grows explosively . The stability problems of the self-built Eureka service registration center cluster and ZooKeeper cluster in this architecture have become increasingly obvious.
During operation and maintenance, students from Manbang Group found that when the number of service registration instances in the self-built Eureka cluster reached 2000+, due to the synchronization of instance registration information between Eureka cluster nodes, some nodes could not handle it, which was very easy. Problems arise where nodes fail to provide services and eventually cause failures; frequent GC in the ZooKeeper cluster causes jitters in inter-service calls and configuration releases, affecting overall stability. Furthermore, because ZooKeeper does not have any authentication and identity authentication capabilities enabled by default, configuration storage faces security risks. Challenges, these problems also bring great challenges to the stable and lasting development of the business.
Smooth migration of business architecture
Under the above business background, Manbang students chose to migrate to the cloud urgently, using Alibaba Cloud MSE Nacos and MSE ZooKeeper products to replace the original Eureka and Zookeeper clusters. However, how can we achieve low-cost and rapid architecture upgrades, as well as the business during the cloud migration? What about lossless and smooth migration of traffic?
On this issue, MSE Nacos has achieved full compatibility with the open source Eureka native protocol. The kernel is still driven by Nacos. The business adaptation layer maps the Eureka InstanceInfo data model and the Nacos data model (Service and Instance) one by one. All this is completely transparent to the business parties that Manbang Group has taken over the self-built Eureka cluster.
This means that the original business side does not need to be changed at the code level. You only need to modify the Endpoint configuration of the server instance connected by Eureka Client to the Endpoint of MSE Nacos. It is also very flexible in use. You can continue to use the native Eureka protocol to use the MSE Nacos instance as an Eureka cluster, or you can use Nacos and Eureka client dual protocols to coexist. The service registration information of different protocols supports mutual conversion, thus Ensure the connectivity of business microservice calls.
In addition, during the cloud migration process, MSE officially provided the MSE-Sync solution, which is an optimized migration supporting data synchronization tool based on the open source Nacos-Sync. It supports two-way synchronization, automatic pull services and one-click synchronization functions. Through MSE-Sync, Manbang students can easily migrate the existing online service registration stock data on the original self-built Eureka cluster to the new MSE Nacos cluster with one click. At the same time, the incremental data newly registered on the old cluster can also be migrated in one click. It will be continuously and automatically synchronized to the new cluster, thus ensuring that the cluster service registration instance information on both sides is always completely consistent before the actual business flow migration. After the data synchronization check passes, replace the original Eureka Client Endpoint configuration, re-publish and upgrade, and successfully migrate to the new MSE Nacos cluster.
Breaking through the performance bottleneck of native Eureka cluster architecture
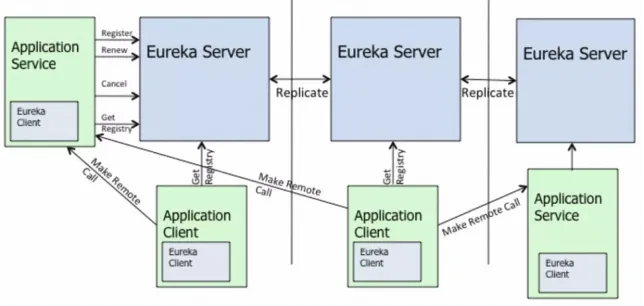
When Manbang Group found the MSE team cooperation technical architecture upgrade, the most important request was to solve the original problem of high pressure to synchronize service registration information between Eureka clusters . This is because Eureka Server is a traditional peer-to-peer star. Due to the synchronization AP model, the roles of each Server node are equal and completely equivalent. For each change (registration/deregistration/heartbeat renewal/service status change, etc.), a corresponding synchronization task will be generated for synchronization of all instance data. In this way, the amount of synchronization jobs increases in direct correlation with the cluster size and the number of instances.
Through practice, students from Manbang Group found that when the cluster service registration scale reached 2000+, they found that the CPU occupancy rate and load of some nodes were very high, and sometimes they would feign death from time to time, causing business jitters. This is also mentioned in the official Eureka documentation. The broadcast replication model of open source Eureka not only causes its own architectural vulnerability, but also affects the overall horizontal scalability of the cluster.
Replication algorithm limits scalability: Eureka follows a broadcast replication model i.e. all the servers replicate data and heartbeats to all the peers. This is simple and effective for the data set that eureka contains however replication is implemented by relaying all the HTTP calls that a server receives as is to all the peers. This limits scalability as every node has to withstand the entire write load on eureka.
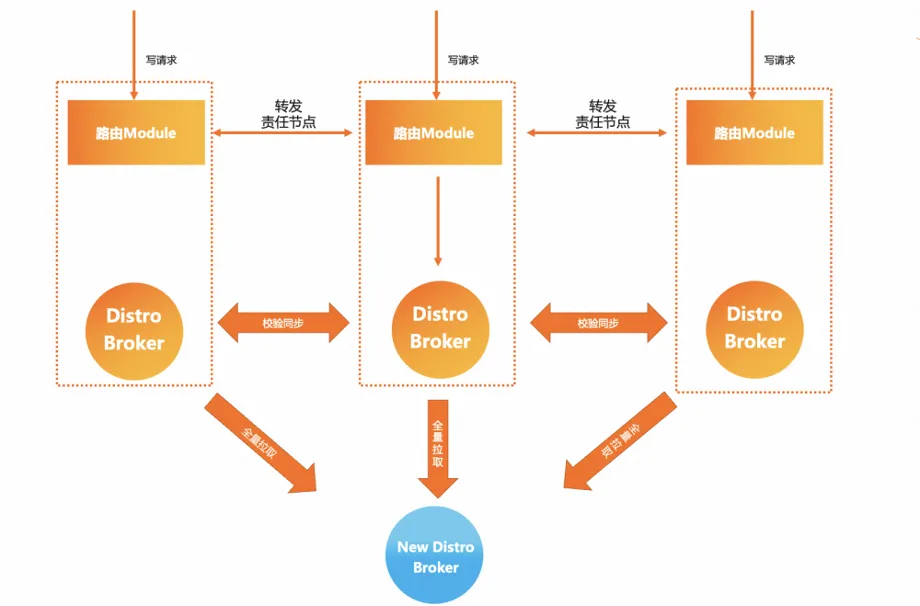
MSE Nacos took this problem into consideration in architecture selection and gave a better solution, which is the self-developed AP model Distro protocol. On the basis of retaining the star synchronization model, Nacos registers instance data for all services. Hash hashing and logical data sharding are performed, and a cluster responsibility node is assigned to each service instance data. Each Server node is only responsible for the synchronization and renewal logic of its own part of the data. At the same time, the granularity of data synchronization between clusters is relatively The Eureka is also smaller. The advantage of this is that even in large-scale deployments and large service instance data, the amount of synchronization tasks between clusters can be relatively controllable , and the larger the cluster size, the greater the performance improvement brought by this model. obvious.
Continuous iterative optimization pursues ultimate performance
After MSE Nacos and MSE ZooKeeper completed the full microservice registration center business of Manbang Group, they continued to iteratively optimize in subsequent upgraded versions, and continued to optimize server performance in every detail through a large number of performance stress testing comparison tests. To optimize the business experience, the optimization points of the upgraded version will be analyzed and introduced one by one.
Service registration high availability disaster recovery protection
Native Nacos provides high-level functions: push protection . The service consumer (Consumer) subscribes to the instance list of the service provider (Provider) through the registration center. When the registration center changes or encounters an emergency, or the service provider and the registration center When the link between centers jitters due to network, CPU and other factors, it may cause subscription exceptions, causing service consumers to obtain an empty service provider instance list.
In order to solve this problem, you can enable the push protection function on the Nacos client or MSE Nacos server to improve the availability of the entire system. We have also introduced this stability function into the protocol support for Eureka. When the MSE Nacos server data is abnormal, when the Eureka client pulls data from the server, it will receive disaster recovery protection support by default to ensure business use. When you do this, you will not get a list of service provider instances that does not meet expectations, causing business failures.
In addition, MSE Nacos and MSE ZooKeeper also provide multiple high-availability guarantee mechanisms . If the business side has higher high reliability and data security requirements, you can choose to deploy with no less than 3 nodes when creating an instance. When one of the instances fails, switching between nodes is completed within seconds, and the failed node automatically leaves the cluster. At the same time, each MSE Region contains multiple availability zones. The network delay between different zones in the same region is very small (within 3ms). Multi-availability zone instances can deploy service nodes in different availability zones. When availability zone A fails, , the traffic will be switched to another availability zone B in a short period of time. The business side has no awareness of the entire process, and the application code level has no awareness and no changes are required. This mechanism only requires configuring multi-node deployment, and MSE will automatically help you deploy to multiple availability zones for scattered disaster recovery.
Support Eureka client to incrementally pull data
After Manbang students migrated to MSE Nacos, the original problem of the server instance being suspended and unable to provide services was well solved. However, it was found that the network bandwidth of the computer room was too high, and occasionally the bandwidth would be full during peak service periods. Later, it was discovered that the reason was that every time the Eureka client pulled the service registration information from MSE Nacos, it only supported full pull, and thousands of levels of data were pulled regularly, resulting in an increase in the number of FGCs at the gateway level. a lot of.
In order to solve this problem, MSE Nacos has launched an incremental pull mechanism for Eureka service registration information. In conjunction with the adjustment of client usage, the client only needs to pull the full amount of data once after the first startup, and subsequently only needs to pull the full amount of data based on the incremental Data is used to maintain the consistency of local data and server data, and periodic full-scale pulls are no longer required. The amount of incremental data changed in a normal production environment is very small, which can significantly reduce the pressure on export bandwidth. After upgrading to this optimized version, Manbang students found that the bandwidth suddenly dropped from 40MB/s before the upgrade to 200KB/s, and the problem of full bandwidth was solved.

Fully stress test to optimize server performance
The MSE team subsequently conducted a larger-scale performance stress test on the MSE Nacos cluster For Eureka scenario, and used various performance analysis tools to identify performance bottlenecks on the business links, and conducted more performance optimization and optimization of the original functions. Low-level performance parameters tuning.
- Caching is introduced for the full and incremental data registration information on the server side, and whether changes have occurred is determined based on the server side data hash. In scenarios where the Eureka server reads more and writes less, it can significantly reduce the performance overhead of CPU calculations to generate returned results.
- It was found that SpringBoot's native StringHttpMessageConverter had a performance bottleneck when processing large-scale data returns, and EnhancedStringHttpMessageConverter was provided to optimize string data IO transmission performance.
- Server-side data return supports chunked.
- The number of Tomcat thread pools is adaptively adjusted according to the container configuration.
After Manbang Group completed the iterative upgrade of the above version, various parameters on the server side have also achieved great optimization results:
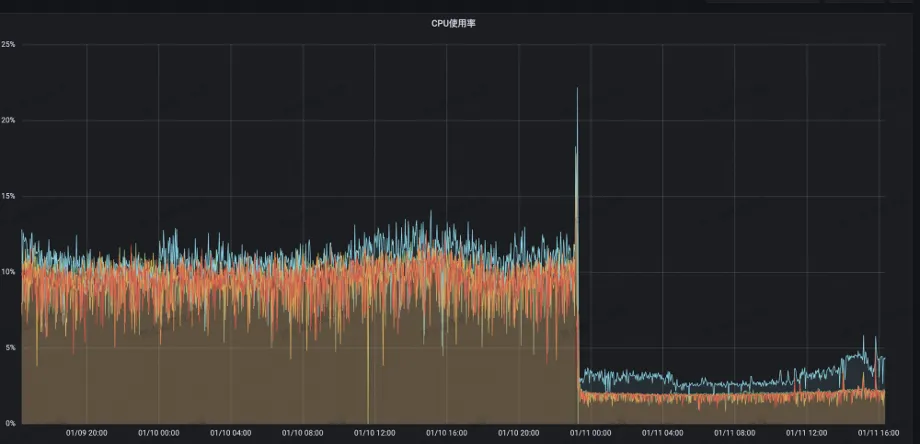
Server CPU utilization dropped from 13% to 2%
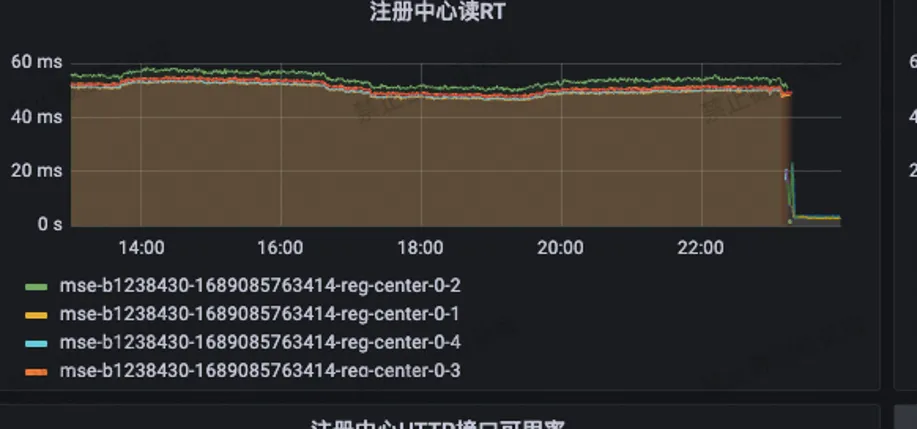
The registration center reading RT has been reduced from the original 55ms to less than 3ms.

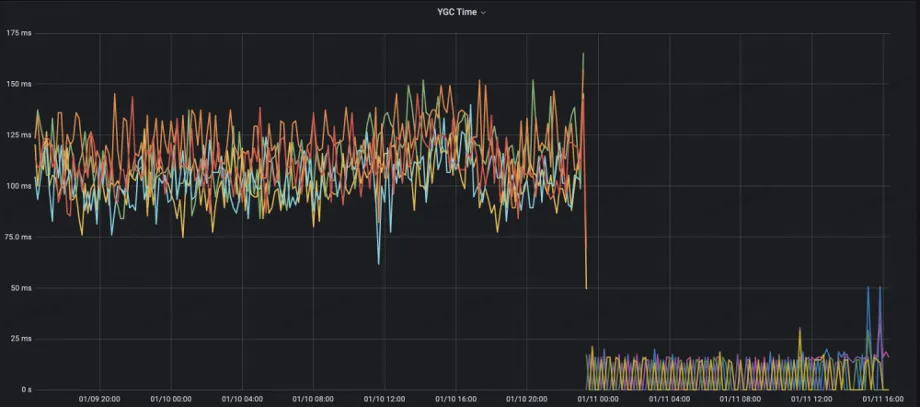
Server-side YGC Count has been reduced from the original 10+ to 1
YGC Time reduced from the original 125ms to less than 10ms
Bypass optimization ensures the stability of the cluster under high pressure
After Manbang students migrated to MSE ZooKeeper for a period of time, Full GC occurred in the cluster again, causing the cluster to become unstable. After MSE emergency investigation, it was found that the reason was because a watch-related statistical indicator of Metrics in ZooKeeper was saved on the current node during calculation. The watch data is fully copied, and the watch scale is very large in a full gang scenario. The metrics calculation copy watch generates a large amount of memory fragments in such a scenario, resulting in the final cluster being unable to allocate qualified memory resources, and ultimately Full GC.
In order to solve this problem, MSE ZooKeeper takes downgrade measures for non-important metrics to ensure that these metrics will not affect cluster stability. For watch copy metrics, it adopts a dynamic acquisition strategy to avoid memory fragmentation problems caused by data copy calculations. After applying this optimization, the cluster Young GC time and number are significantly reduced.
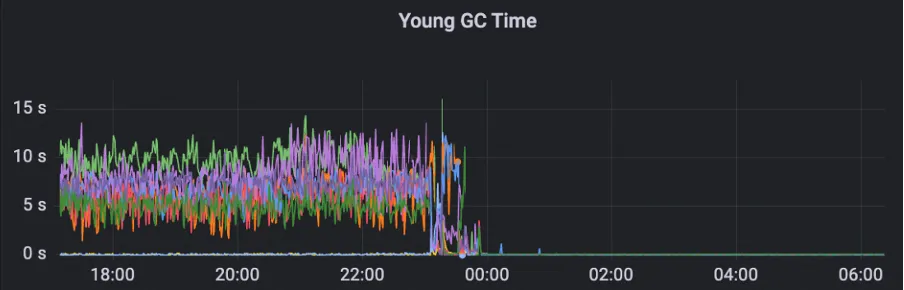

After optimization, the cluster can smoothly handle 200W QPS and GC is stable.
Continuous parameter optimization to find the best balance point between latency and throughput
After Manbang students migrated their self-built ZooKeeper to MSE ZooKeeper, they found that when the application was released, the client's delay in reading the data in ZooKeeper was too large, and the application startup read configuration timeout, resulting in application startup timeout. In order to solve this problem, MSE ZooKeeper Targeted stress testing analysis shows that in a full-service scenario, ZooKeeper needs to handle a large number of requests when the application is released, and the objects generated by the requests cause frequent Young GC in the existing configuration.
针对这种场景,MSE 团队经过多轮压测调整集群配置,寻找请求延时和 TPS 最优的交点,在满足延时需求的前提下,探索集群最优性能,在保证请求延时 20ms 的前提下,集群在日常 10w QPS 的水平下,CPU 从 20% 降低到 5%,集群负载显著降低。
postscript
在数字货运行业竞争激烈和技术快速发展的背景下,满帮集团成功地实现了自身技术架构的升级,从自建的 Eureka 注册中心平滑迁移到了更为高效和稳定的 MSE Nacos 平台。这不仅代表了满帮集团在技术创新和业务扩展上的坚定决心,同时也展现了其对未来发展的深远规划。满帮集团将微服务架构的稳定性和高性能作为其数字化转型的核心,全新的注册中心架构带来的显著性能提高和稳定性增强,为满帮提供了强有力的支撑,使得平台能够更加从容地应对日益增长的业务需求,并且有余力以应对未来可能出现的任何挑战。
It is worth mentioning that Manbang Group’s agile response throughout the entire migration process and the professional execution of its technical team also accelerated the pace of the architecture upgrade. The successful transformation of the business platform not only enhances users' trust in Manbang's services, but also provides valuable experience to other companies. In the future, Manbang will continue to work closely with MSE to further improve the stability, scalability and performance of the technical architecture, continue to set benchmarks for the industry, and promote the digital transformation of the entire logistics industry.
During this migration process, the business was able to be migrated smoothly and without loss and the performance was significantly improved, which proved the excellent performance and reliability of MSE in the field of service registration centers. I believe that with the continuous evolution of MSE, its continuous pursuit of ease of use and stability will undoubtedly bring huge commercial value to more enterprises and play an increasingly important role in the digitalization process of enterprises.
In addition, MSE also fully supports microservice governance functions, including traffic protection, full-link grayscale release, etc. By applying fully configured current limiting rules from the entrance gateway to the backend, the system stability risks caused by sudden traffic are effectively solved, ensuring the continuous and stable operation of the system, and enterprises can focus more on the development of core business. The successful case of Manbang Group has set a new milestone for the industry. We look forward to seeing more companies achieving more brilliant achievements on their digital journey.
Message from Manbang CTO Wang Dong (Dongtian): Fully understanding and utilizing the capabilities of the cloud can free the Manbang technical team from continuous investment at the bottom level, focus on higher-level system stability and engineering efficiency, and achieve better results from the architectural level. High ROI.
Recommended activities:

Click here to register for Feitian Technology Salon’s first AI native application architecture session.
Microsoft's China AI team collectively packed up and went to the United States, involving hundreds of people. How much revenue can an unknown open source project bring? Huawei officially announced that Yu Chengdong's position was adjusted. Huazhong University of Science and Technology's open source mirror station officially opened external network access. Fraudsters used TeamViewer to transfer 3.98 million! What should remote desktop vendors do? The first front-end visualization library and founder of Baidu's well-known open source project ECharts - a former employee of a well-known open source company that "went to the sea" broke the news: After being challenged by his subordinates, the technical leader became furious and rude, and fired the pregnant female employee. OpenAI considered allowing AI to generate pornographic content. Microsoft reported to The Rust Foundation donated 1 million US dollars. Please tell me, what is the role of time.sleep(6) here?