1. Generate text before Transformer
It is important to note that generative algorithms are not new. Previous language models used an architecture called a recurrent neural network, or RNN. Although powerful in their day, RNNs 
were limited in their capabilities due to the large amount of computation and memory required to perform generative tasks well. Let's look at an example of an RNN performing a simple next word prediction generation task.
The model has only seen one previous word, and the prediction cannot be very good. When you scale up your RNN implementation to be able to see more preceding words in the text, you have to drastically scale up the resources used by the model. As for prediction, well, the model fails here.

Even if you scale up the model, it still hasn't seen enough input to make good predictions. To successfully predict the next word, the model needs to see more than just the previous words. Models need to understand entire sentences or even entire documents. The problem here is that language is complex.
In many languages, a word can have more than one meaning. These are homophones. In this case, it is only in the context of the sentence that we can see what type of bank it is.

Words in sentence structure can be ambiguous, or what we might call syntactic ambiguity. Take this sentence, for example: "The teacher teaches the students with books." Does the teacher teach with books or does the student have books, or both? If sometimes we ourselves cannot understand human language, how can algorithms understand it?

Well, in 2017, everything changed after Google and the University of Toronto released the paper "Attention is All You Need". The transformer architecture has arrived.
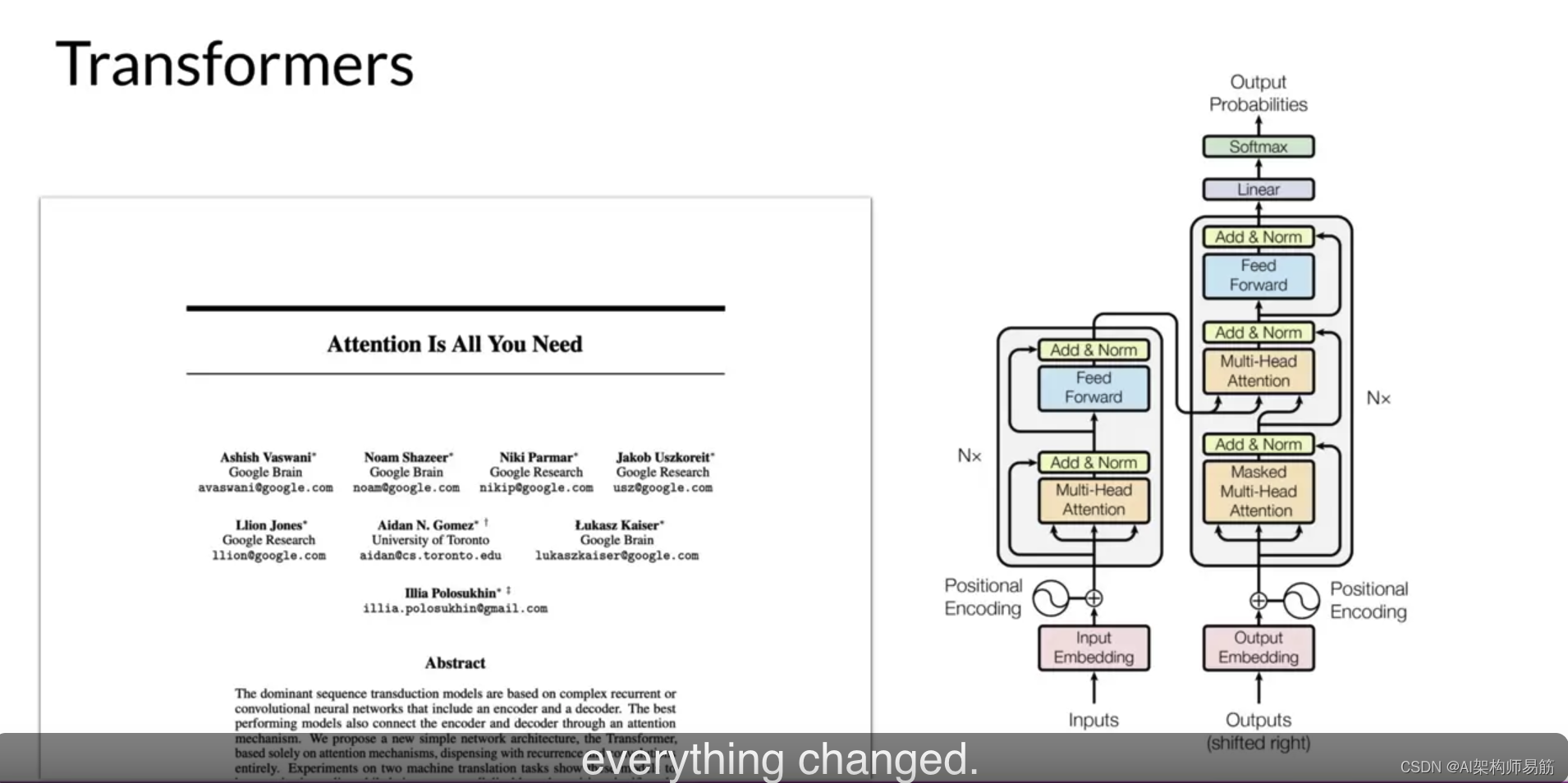
This novel approach unlocked the advances in generative AI we see today. It scales efficiently to use multi-core GPUs, it can process input data in parallel, use larger training datasets, and crucially, it can learn to pay attention to the meaning of the words it is processing. And Attention is All You Need. That's the title.

reference
https://www.coursera.org/learn/generative-ai-with-llms/lecture/vSAdg/text-generation-before-transformers