
This article is based on a speech given by Shao Wei, senior R&D engineer of Volcano Engine, at the QCon Global Software Development Conference. Speaker|Shao Wei’s speech time|QCon Guangzhou in May 2023
PPT | Katalyst: ByteDance Cloud Native Cost Optimization Practice
1.Background
Byte has started to transform its services into cloud-native services since 2016. As of today, Byte's service system mainly includes four categories: traditional microservices are mostly RPC Web services based on Golang; the promotion search service is a traditional C++ service with higher performance requirements; in addition There are also machine learning, big data and various storage services .
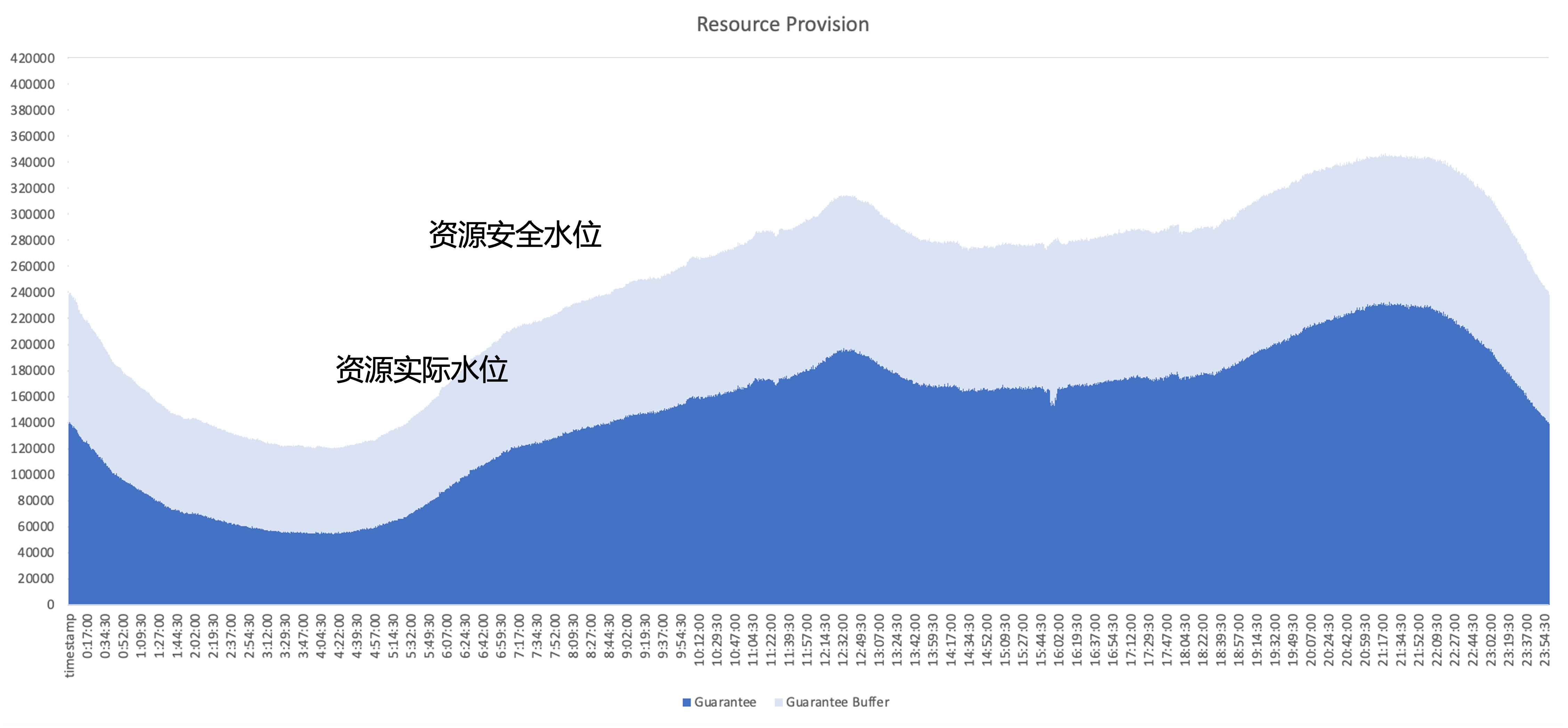
The core issue that needs to be solved after cloud native is how to improve the resource utilization efficiency of the cluster; taking the resource usage of a typical online service as an example, the dark blue part is the amount of resources actually used by the business, and the light blue part is the security buffer provided by the business area, even if the buffer area is increased, there are still many resources that have been applied for but not used by the business. Therefore the optimization focus is to utilize these unused resources as much as possible from an architectural perspective.
resource management plan
Byte has tried several different types of resource management solutions internally, including
- Resource operation: regularly help the business run resource utilization status and promote resource application management. The problem is that the operation and maintenance burden is heavy and the utilization problem cannot be solved.
- Dynamic overbooking: Evaluate the amount of business resources on the system side and proactively reduce the quota. The problem is that the overbooking strategy is not necessarily accurate and may lead to a run risk.
- Dynamic scaling: The problem is that if you only target online services for scaling, since the peaks and troughs of traffic in online services are similar, it will not be able to fully improve utilization throughout the day.
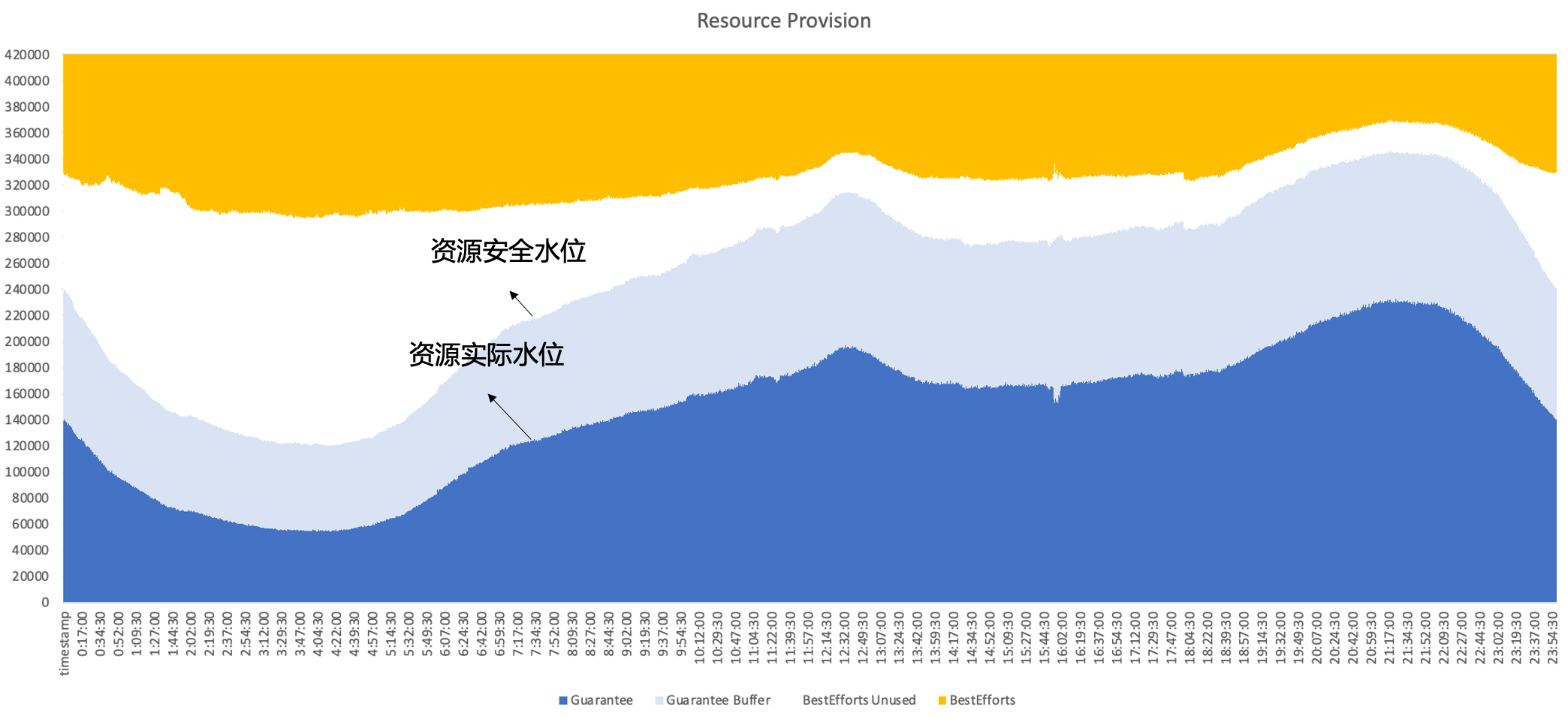
Therefore, in the end, Byte adopts hybrid deployment, running online and offline on the same node at the same time, making full use of the complementary characteristics between online and offline resources to achieve better resource utilization; ultimately we expect to achieve the following effect, that is, secondary sales are online Unused resources can be well filled with offline workloads to maintain resource utilization efficiency at a high level throughout the day.
2. Development history of byte hybrid deployment
As Byte Cloud becomes native, we choose appropriate hybrid deployment solutions based on business needs and technical characteristics at different stages, and continue to iterate our hybrid system in the process.
2.1 Phase 1: Offline time-sharing mixing
The first stage mainly involves online and offline time-sharing hybrid deployment.
- Online: At this stage, we have built an online service elasticity platform. Users can configure horizontal scaling rules based on business indicators; for example, if business traffic decreases in the early morning and the business proactively shrinks some instances, the system will perform resource bing packing on the basis of instance shrinkage. This frees up the entire machine;
- For offline: At this stage, offline services can obtain a large number of spot type resources, and because their supply is unstable, they can enjoy a certain discount on the cost; at the same time, for online, selling unused resources to offline can obtain a certain rebate on the cost. .
The advantage of this solution is that it does not require a complex single-machine side isolation mechanism, and the technical implementation is relatively low; however, there are also some problems, such as
- The conversion efficiency is not high, and problems such as fragmentation may occur during the bing packing process;
- The offline experience may not be good either. When the online traffic fluctuates occasionally, the offline user may be forcibly killed, resulting in strong resource fluctuations.
- It will cause instance changes to the business. In actual operations, the business usually configures a relatively conservative elastic policy, resulting in a low upper limit for resource improvement.
2.2 Phase 2: Kubernetes/YARN joint deployment
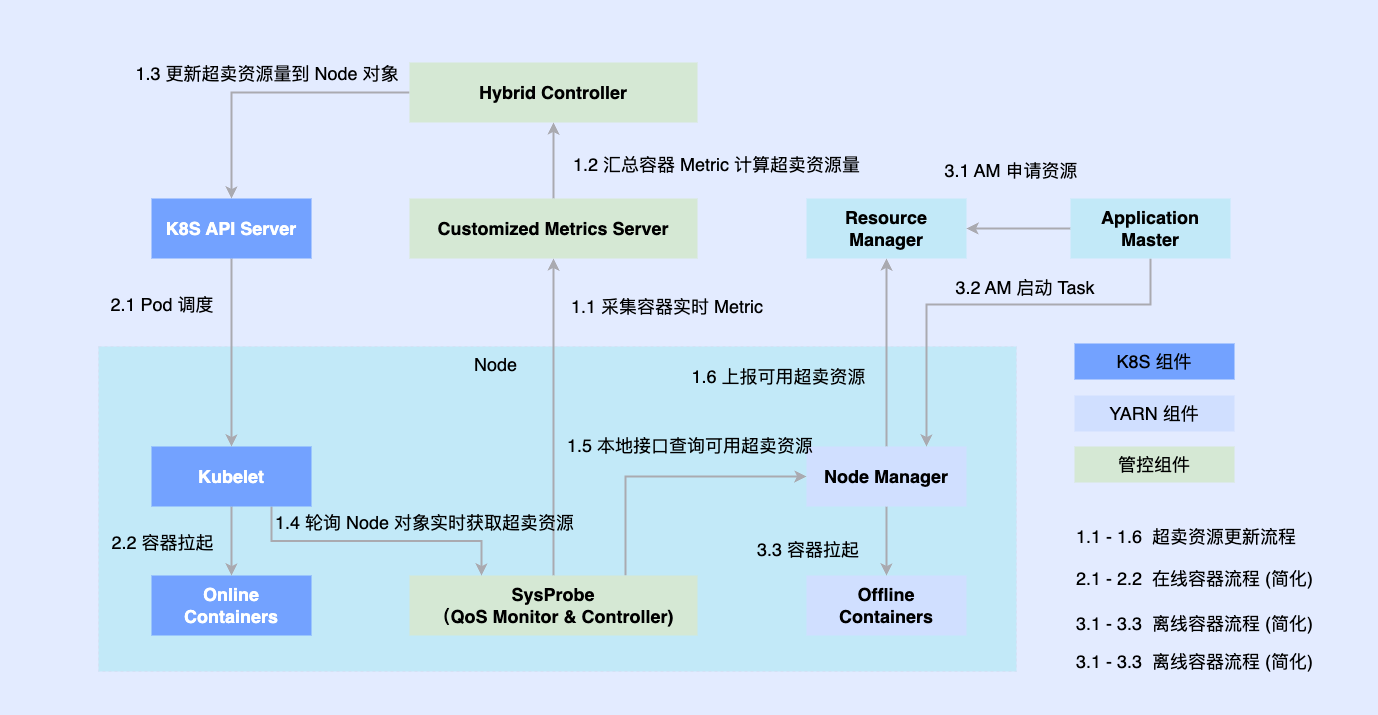
In order to solve the above problems, we entered the second stage and tried to run offline and online on one node.
Since the online part has been natively transformed based on Kubernetes earlier, most offline jobs are still run based on YARN. In order to promote hybrid deployment, we introduce third-party components on a single machine to determine the amount of resources coordinated to online and offline, and connect them with stand-alone components such as Kubelet or Node Manager; at the same time, when online and offline workloads are scheduled to nodes, they are also coordinated by The coordination component asynchronously updates resource allocations for both workloads.
This plan allows us to complete the reserve accumulation of co-location capabilities and verify the feasibility, but there are still some problems
- The two systems are executed asynchronously, so that the offline container can only bypass management and control, and there is a race; and there is too much resource loss in the intermediate links.
- The simple abstraction of offline workloads prevents us from describing complex QoS requirements
- The fragmentation of offline metadata makes extreme optimization difficult and cannot achieve global scheduling optimization.
2.3 Phase 3: Unified scheduling and mixed deployment offline
In order to solve the problems in the second stage, in the third stage we completely realized unified offline hybrid deployment.
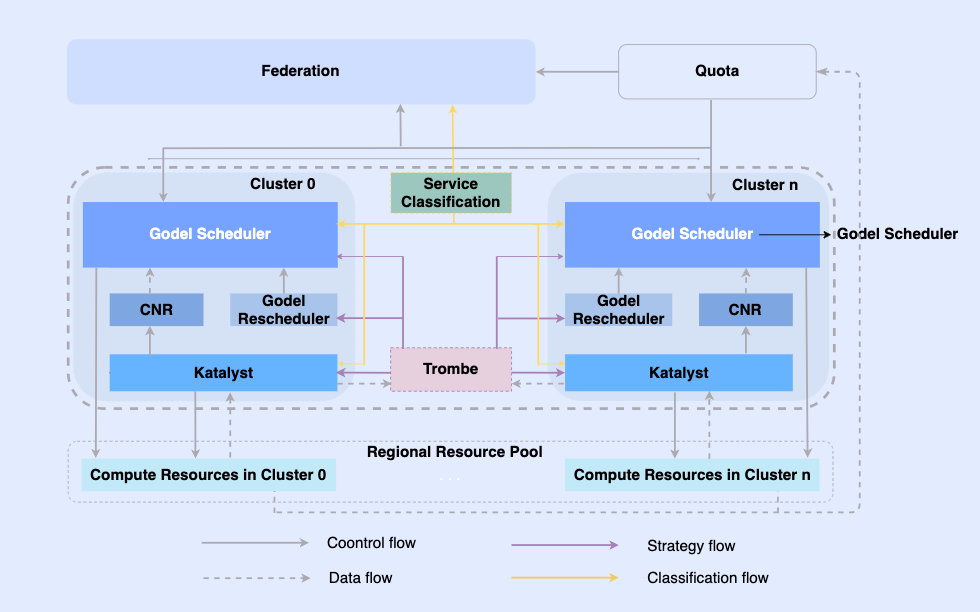
By making offline jobs cloud-native, we enable them to be scheduled and resource managed on the same infrastructure. In this system, the topmost layer is a unified resource federation to realize multi-cluster resource management. In a single cluster, there is a central unified scheduler and a stand-alone unified resource manager. They work together to achieve offline integrated resource management capabilities.
In this architecture, Katalyst serves as the core resource management and control layer and is responsible for realizing real-time resource allocation and estimation on the single machine side. It has the following characteristics
- Abstraction standardization: Open up offline metadata, make QoS abstraction more complex and richer, and better meet business performance requirements;
- Management and control synchronization: The management and control policy is issued when the container is started to avoid asynchronous correction of resource adjustments after startup, while supporting free expansion of the policy;
- Intelligent strategy: By building service portraits, you can sense resource demands in advance and implement smarter resource management and control strategies;
- Operation and maintenance automation: Through integrated delivery, operation and maintenance automation and standardization are achieved.
3. Katalyst system introduction
Katalyst is derived from the English word catalyst, which originally means catalyst. The first letter is changed to K, which means that the system can provide more powerful automated resource management capabilities for all loads running in the Kubernetes system.
3.1 Katalyst system overview
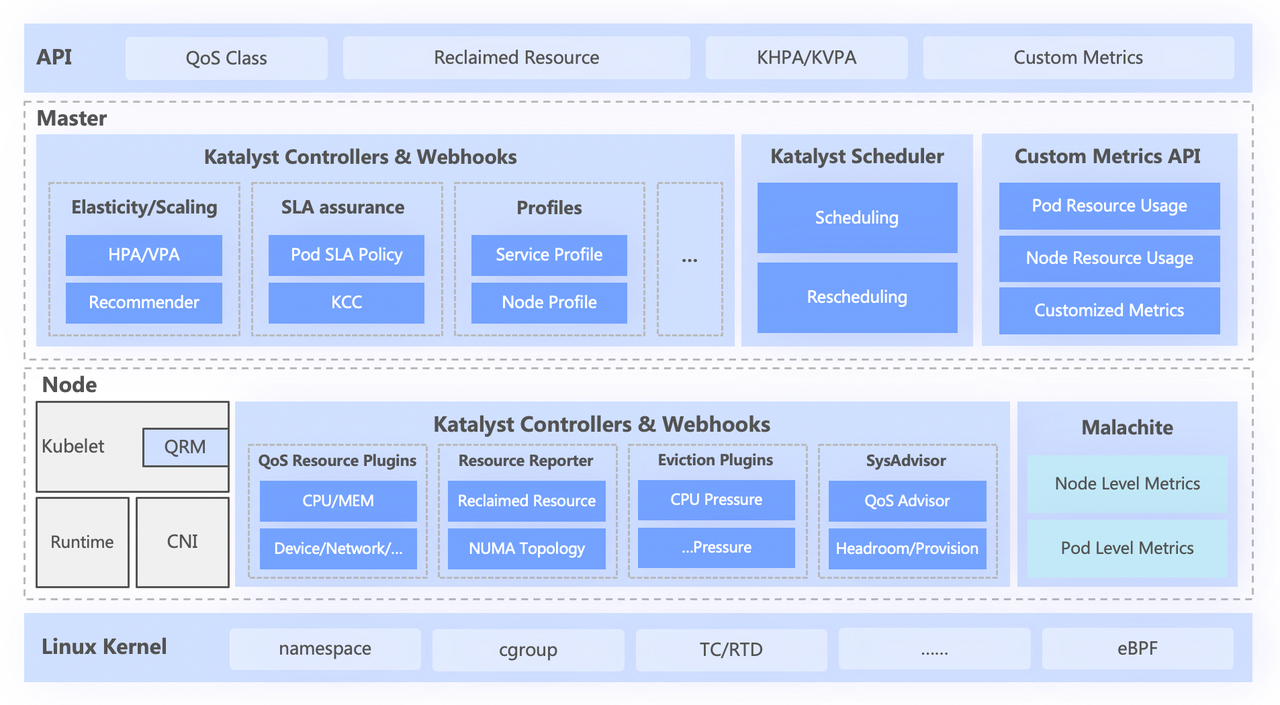
The Katalyst system is roughly divided into four layers, including
- The top-level standard API abstracts different QoS levels for users and provides rich resource expression capabilities;
- The central layer is responsible for basic capabilities such as unified scheduling, resource recommendation, and building service portraits;
- The stand-alone layer includes a self-developed data monitoring system and a resource allocator responsible for real-time allocation and dynamic adjustment of resources;
- The bottom layer is a byte-customized kernel, which solves the problem of single-machine performance when running offline by enhancing the kernel patch and underlying isolation mechanism.
3.2 Abstract standardization: QoS Class
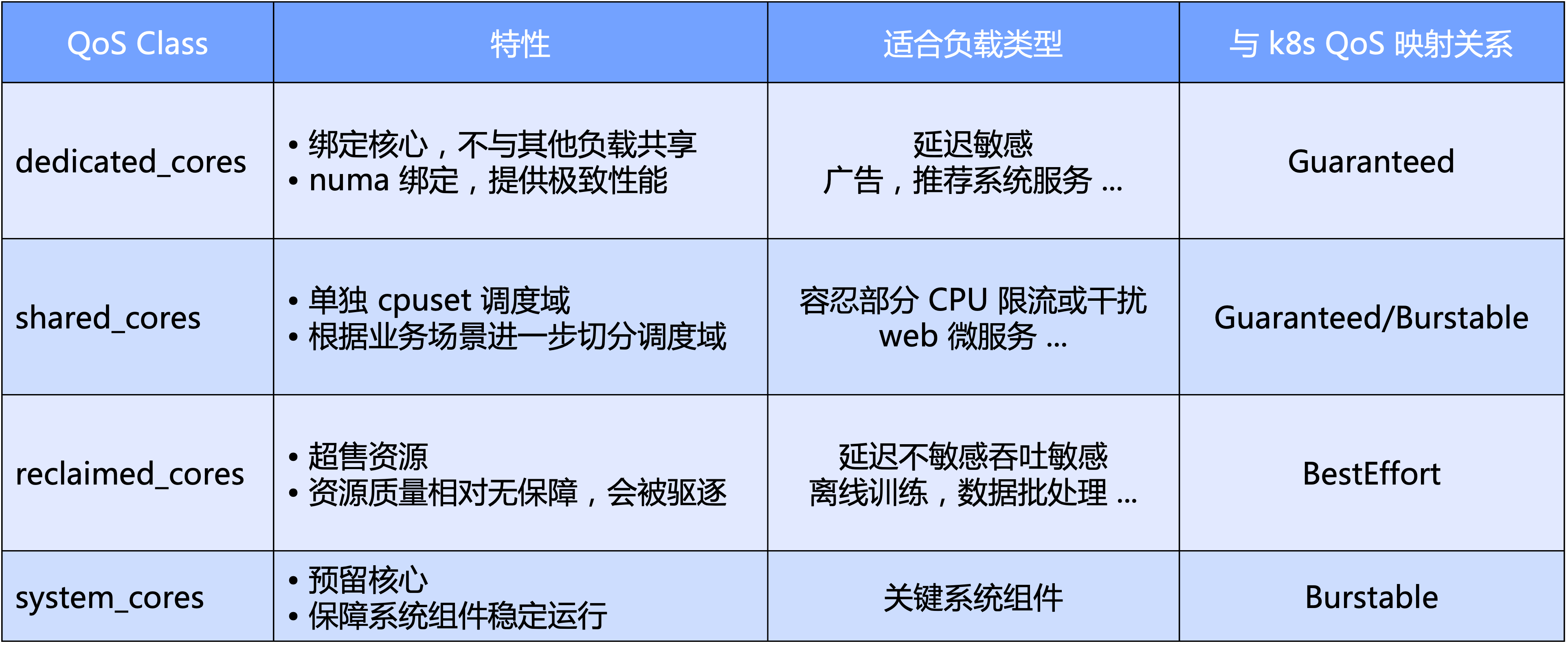
Katalyst QoS can be interpreted from both macro and micro perspectives
- At a macro level, Katalyst defines standard QoS levels based on the main dimension of CPU; specifically, we divide QoS into four categories: exclusive, shared, recycling and system type reserved for key system components;
- From a micro perspective, Katalyst's final expectation is that no matter what kind of workload it is, it can be run in a pool on the same node without the need to isolate the cluster through hard cutting, thereby achieving better resource traffic efficiency and resource utilization efficiency.
On the basis of QoS, Katalyst also provides a wealth of extension enhancements to express other resource requirements in addition to CPU cores.
- QoS Enhancement: Extended expression of business requirements for multi-dimensional resources such as NUMA/network card binding, network card bandwidth allocation, IO Weight, etc.
- Pod Enhancement: Extends the expression of the sensitivity of the business to various system indicators, such as the impact of CPU scheduling delay on business performance
- Node Enhancement: Express the combined demands of micro-topology among multiple resource dimensions by extending the native TopologyPolicy
3.3 Management and control synchronization: QoS Resource Manager
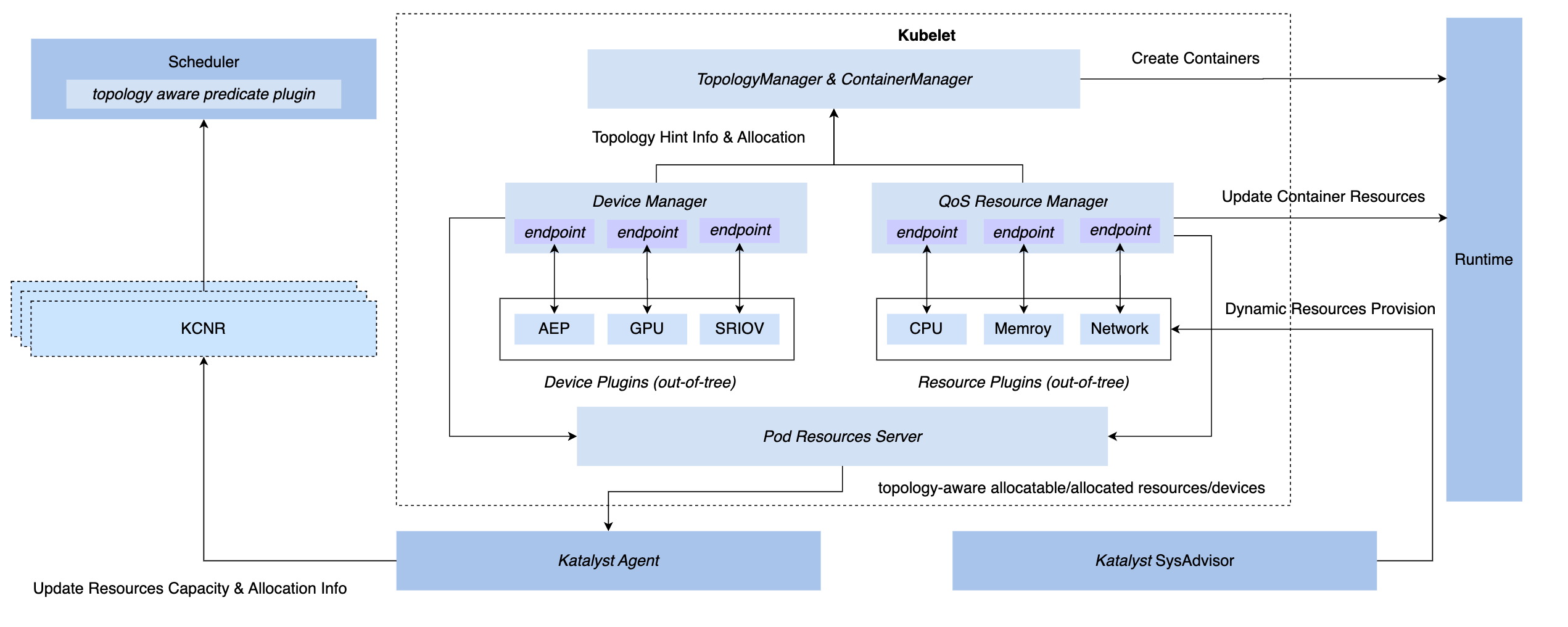
In order to achieve synchronous management and control capabilities under the K8s system, we have three hook methods: CRI layer insertion, OCI layer, and Kubelet layer. In the end, Katalyst chose to implement management and control on the Kubelet side, that is, to implement a QoS Resource Manager at the same level as the native Device Manager. Advantages of this program include
- Implement interception during the admit stage, eliminating the need to rely on covert measures to achieve control in subsequent steps.
- Connect metadata with Kubelet, report single-machine microtopology information to node CRD through standard interface, and realize docking with scheduler
- Based on this framework, pluggable plugins can be flexibly implemented to meet customized management and control needs.
3.4 Intelligent strategy: service portrait and resource estimation
Usually, it is more intuitive to choose to use business indicators to build a service portrait, such as service P99 delay or downstream error rate. But there are also some problems. For example, compared with system indicators, it is usually more difficult to obtain business indicators; businesses usually integrate multiple frameworks, and the meanings of the business indicators they produce are not exactly the same. If there is a strong reliance on these indicators, the entire The implementation of control will become very complicated.
Therefore, we hope that the final resource control or service portrait is based on system indicators rather than business indicators; the most critical one is how to find the system indicators that the business is most concerned about. Our approach is to use a set of offline pipelines to discover business indicators. and system indicators. For example, for the service in the figure, the core business indicator is P99 delay. Through analysis, it is found that the system indicator with the highest correlation is CPU scheduling delay. We will continue to adjust the resource supply of the service to approach its goal as much as possible. CPU scheduling delays.
On the basis of service portraits, Katalyst provides rich isolation mechanisms for CPU, memory, disk and network, and customizes the kernel when necessary to provide stronger performance requirements; however, for different business scenarios and types, These means are not necessarily applicable, so it needs to be emphasized that isolation is more of a means than an end. In the process of undertaking business, we need to choose different isolation solutions based on specific needs and scenarios.
3.5 Operation and maintenance automation: multi-dimensional dynamic configuration management
Although we hope that all resources are under a resource pool system, in a large-scale production environment, it is impossible to put all nodes in a cluster; in addition, a cluster may have both CPU and GPU machines, although The control plane can be shared, but certain isolation is required on the data plane; at the node level, we often need to modify the node dimension configuration for grayscale verification, resulting in differences in the SLOs of different services running on the same node.
To solve these problems, we need to consider the impact of different configurations of nodes on services during business deployment. To this end, Katalyst provides dynamic configuration management capabilities for standard delivery, evaluating the performance and configuration of different nodes through automated methods, and selecting the most suitable node for the service based on these results.
4. Katalyst co-location application and case analysis
In this section, we will share some best practices based on internal cases from Byte.
4.1 Utilization effect
In terms of Katalyst implementation effects, based on Byte's internal business practices, our resources can be maintained at a relatively high state during the quarterly cycle; in a single cluster, resource utilization also shows a relatively high level in various time periods of each day. Stable distribution; at the same time, the utilization of most machines in the cluster is also relatively concentrated, and our hybrid deployment system runs relatively stably on all nodes.
| Resource Forecasting Algorithm | Reclaimed resource ratio | Day-level average CPU utilization | Day-level peak CPU utilization |
|---|---|---|---|
| Utilization fixed buffer | 0.26 | 0.33 | 0.58 |
| k-means clustering algorithm | 0.35 | 0.48 | 0.6 |
| System indicator PID algorithm | 0.39 | 0.54 | 0.66 |
| System indicator model estimation + PID algorithm | 0.42 | 0.57 | 0.67 |
4.2 Practice: offline senseless access
After entering the third stage, we need to carry out cloud-native transformation offline. There are two main methods of transformation. One is for services already in the K8s system. We will directly connect the resource pool based on Virtual Kubelet. The other is for services under the YARN architecture. If the service is directly connected to the Kubernetes system, A complete transformation of the framework will be very costly for the business and will theoretically lead to rolling upgrades for all businesses. This is obviously not an ideal state.
In order to solve this problem, Byte refers to the glue layer of Yodel, that is, business access still uses the standard Yarn API; but in this glue layer, we will interface with the underlying K8s semantics and abstract the user's request for resources into something like Pod or Description of the container. This method allows us to use more mature K8s technology at the bottom level to manage resources, achieve offline cloud-native transformation, and at the same time ensure the stability of the business.
4.3 Practice: Resource Operation Governance
During the co-location process, we need to adapt and transform the big data and training framework, and do various retries, checkpoints, and grading to ensure that after we cut these big data and training jobs to the entire co-location resource pool, The experience of using them is not too bad.
At the same time, we need to have complete basic capabilities in resource commodities, business classification, operational governance, and quota management in the system. If the operation is not done well, the utilization rate may be very high during certain peak periods, but there may be a large resource gap during other periods, causing the utilization rate to fail to meet expectations.
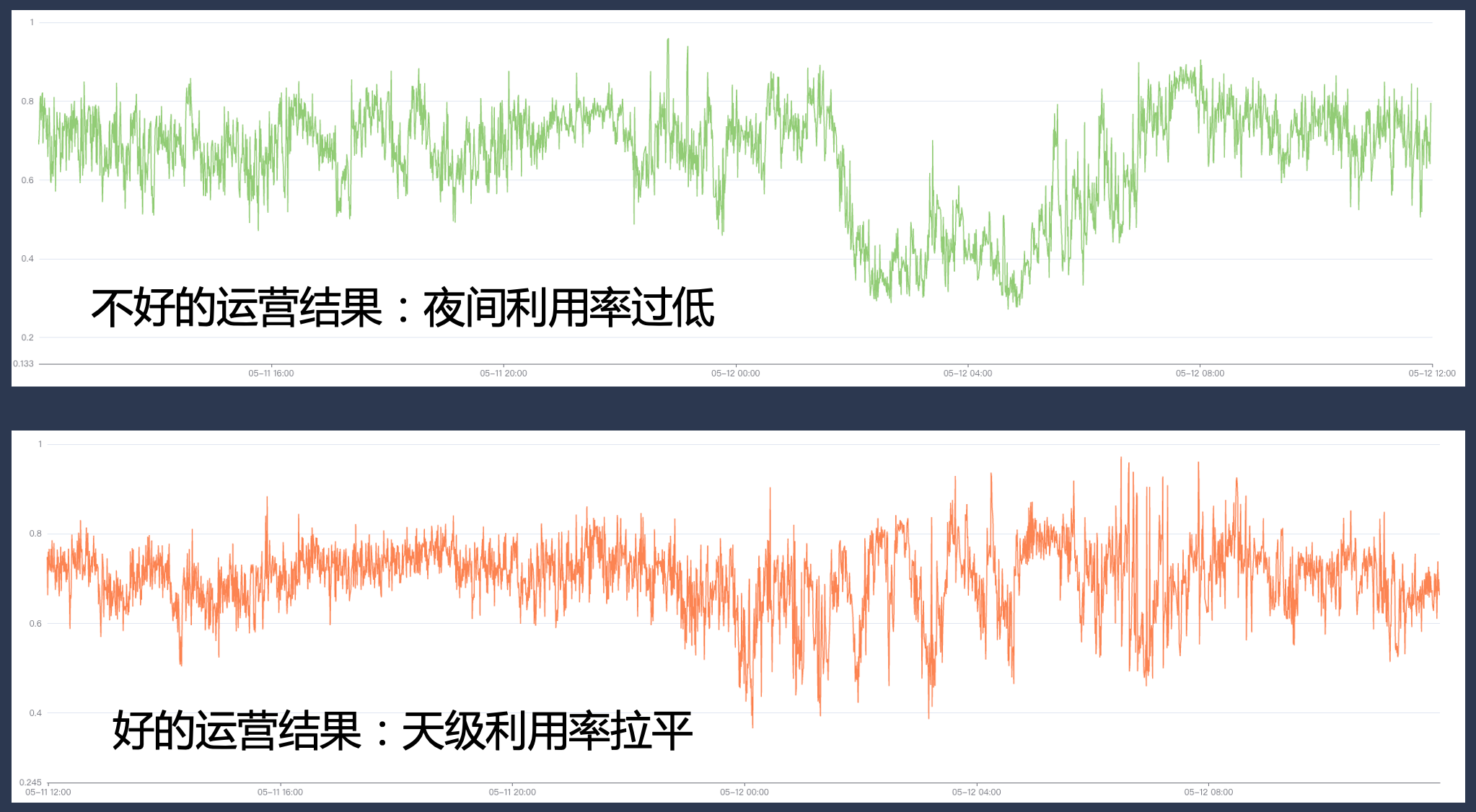
4.4 Practice: Maximizing Resource Efficiency Improvement
When building service portraits, we use system indicators for management and control. However, static system indicators based on offline analysis cannot keep up with changes on the business side in real time. It is necessary to analyze changes in business performance within a certain period of time to adjust static values.
To this end, Katalyst introduces models to fine-tune system metrics. For example, if we think that the CPU scheduling delay may be x milliseconds, and after a period of time, we calculate through the model that the business target delay may be y milliseconds, we can dynamically adjust the value of the target to better evaluate business performance.
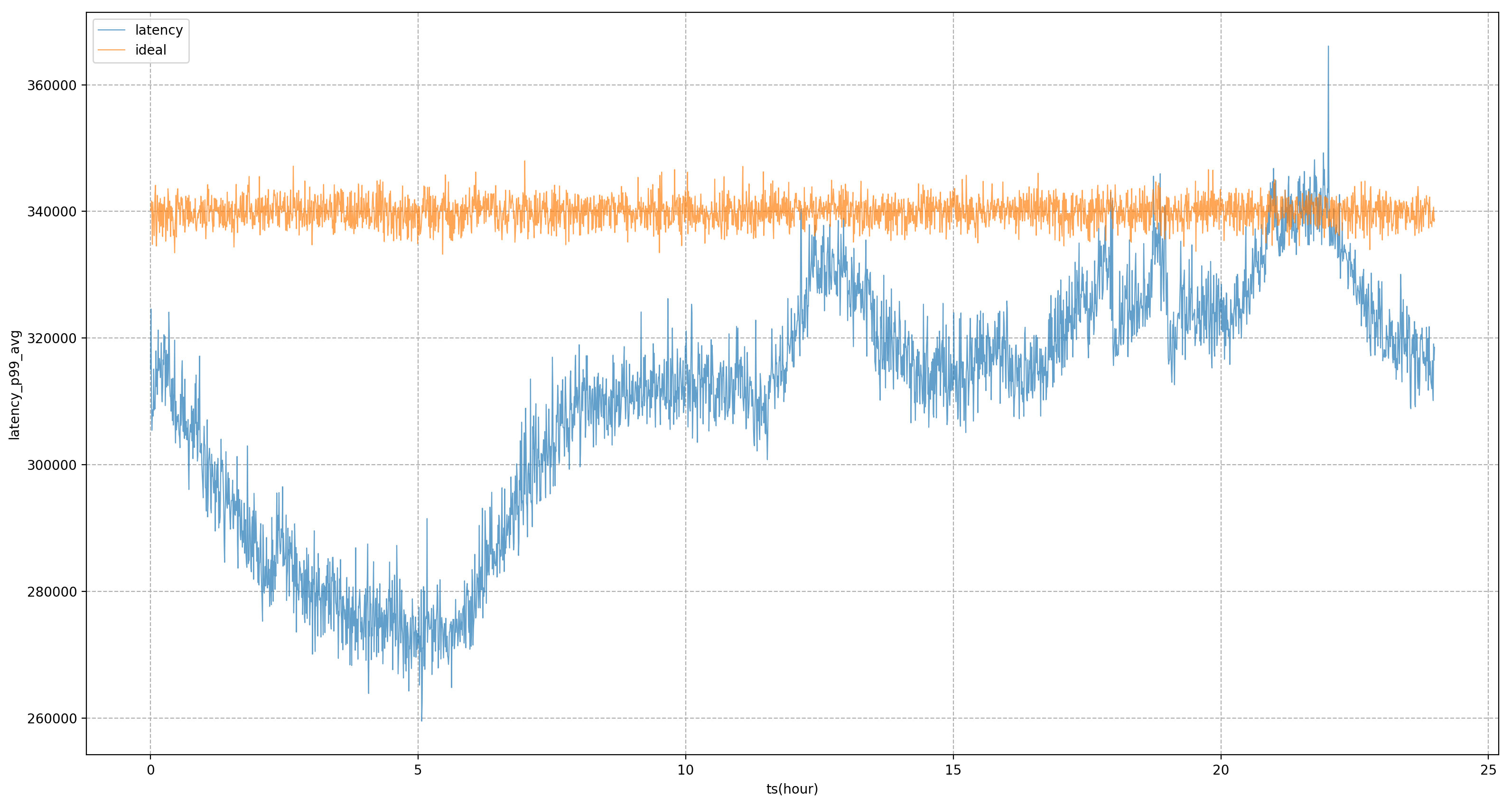
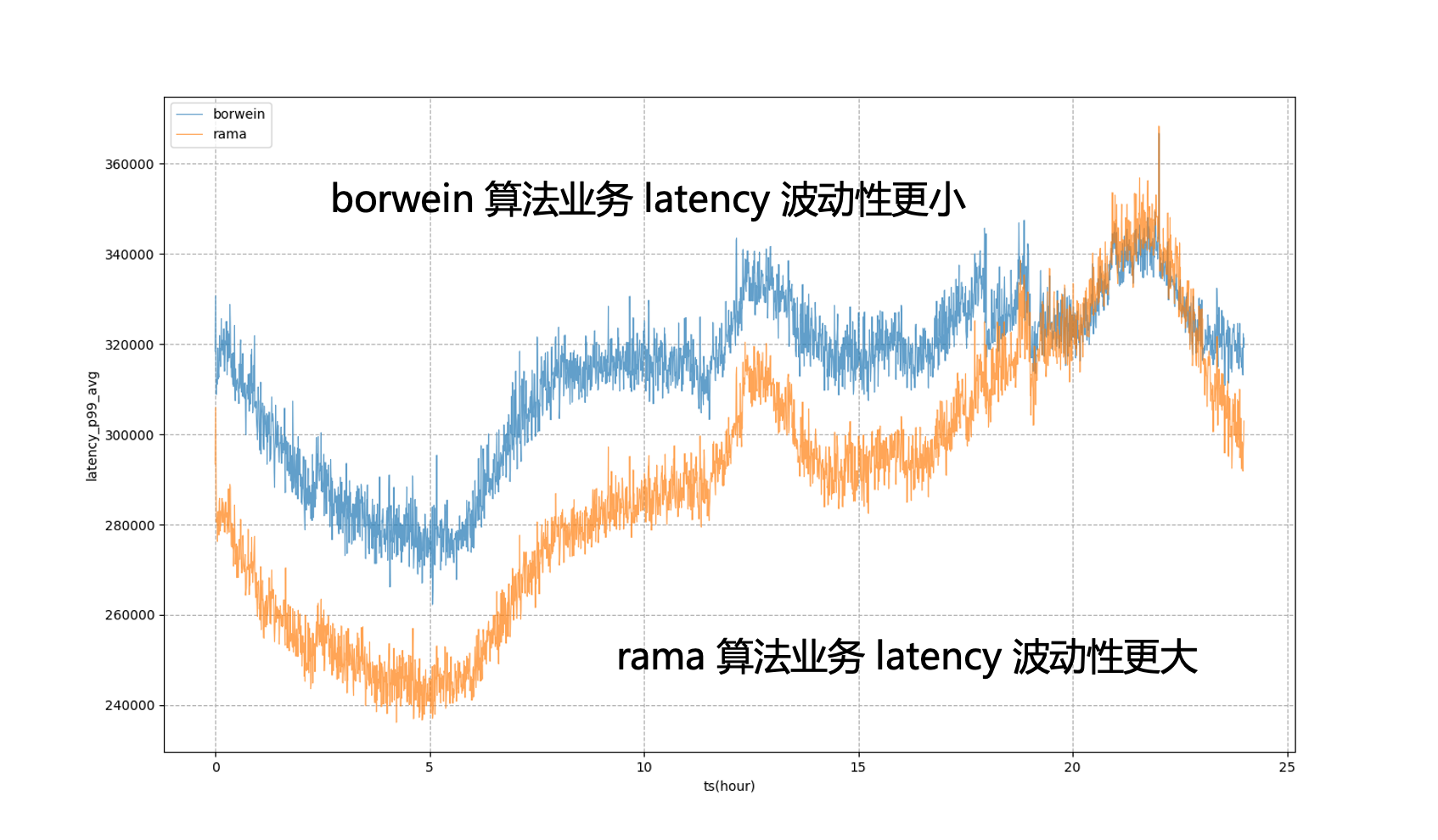
For example, in the figure below, if static system targets are completely used for regulation, the business P99 will be in a state of severe fluctuation, which means that during non-evening peak hours, we cannot squeeze the business resource usage to a more extreme state to make it closer to the business The amount that can be tolerated during the evening peak hours; after introducing the model, we can see that the business delay will be more stable, allowing us to level the business performance to a relatively stable level throughout the day and obtain resource benefits.
4.5 Practice: Solve single-machine problems
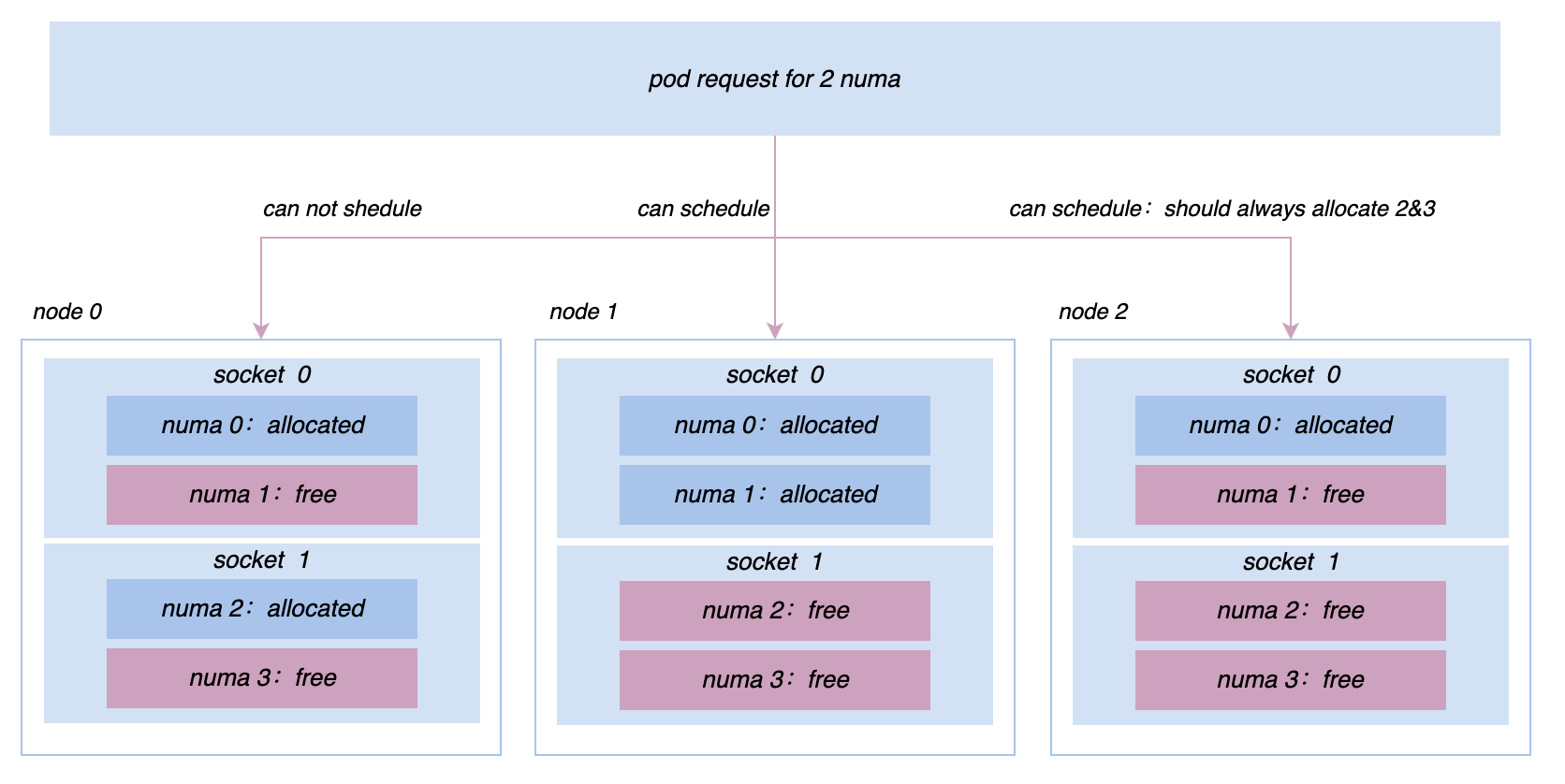
In the process of promoting co-location, we will continue to encounter various online and offline performance issues and demands for micro-topology management. For example, initially all machines were managed and controlled based on cgroup V1. However, due to the structure of V1, the system needs to traverse a very deep directory tree and consume a lot of kernel-mode CPU. In order to solve this problem, we are switching the nodes in the entire cluster to cgroup V1. The cgroup V2 architecture allows us to isolate and monitor resources more efficiently; for services such as promotion search, in order to pursue more extreme performance, we need to implement more complex affinity and anti-affinity strategies at the Socket/NUMA level, etc. Etc., these more advanced resource management requirements can be better realized in Katalyst.
5 Summary and Outlook
Katalyst has been officially open sourced and released version v0.3.0, and will continue to invest more energy in iteration; the community will build capabilities and system enhancements in resource isolation, traffic profiling, scheduling strategies, elastic strategies, heterogeneous device management, etc. , everyone is welcome to pay attention to, participate in this project and provide feedback.
Fellow chicken "open sourced" deepin-IDE and finally achieved bootstrapping! Good guy, Tencent has really turned Switch into a "thinking learning machine" Tencent Cloud's April 8 failure review and situation explanation RustDesk remote desktop startup reconstruction Web client WeChat's open source terminal database based on SQLite WCDB ushered in a major upgrade TIOBE April list: PHP fell to an all-time low, Fabrice Bellard, the father of FFmpeg, released the audio compression tool TSAC , Google released a large code model, CodeGemma , is it going to kill you? It’s so good that it’s open source - open source picture & poster editor toolConference speech video: Katalyst: Bytedance Cloud Native Cost Optimization Practice | QCon Guangzhou 2023