
1. Background
Repeated work and code standards: During the development process of B-end front-end code, developers will always face the pain point of repeated development. The element modules of many CRUD pages are basically similar, but they still need to be developed manually. Time is spent on simple element construction, which reduces the cost of development. The development efficiency of business requirements , and because the coding styles of different developers are inconsistent , make it more expensive for others to get started during agile iterations.
AI replaces simple brain power: With the continuous development of large AI models, it has simple understanding capabilities and can convert language into instructions . General instructions for building basic pages can meet the needs of daily basic page building and improve the efficiency of business development in general scenarios.
2. List of generated links
B-side page lists, forms, and details can all be generated, and the links can be roughly divided into the following steps.
-
Enter natural language
-
Combined with the large model, the corresponding construction information is extracted according to the specified rules.
-
Build information combined with code template and AST output front-end code
3. Express needs
Graphical configuration
The first step in auxiliary code generation is to tell it what kind of interface to develop. When it comes to this, the first thing we think of is page configuration , which is the current mainstream low-code product form. Users build the page through a series of graphical configurations, as follows picture:
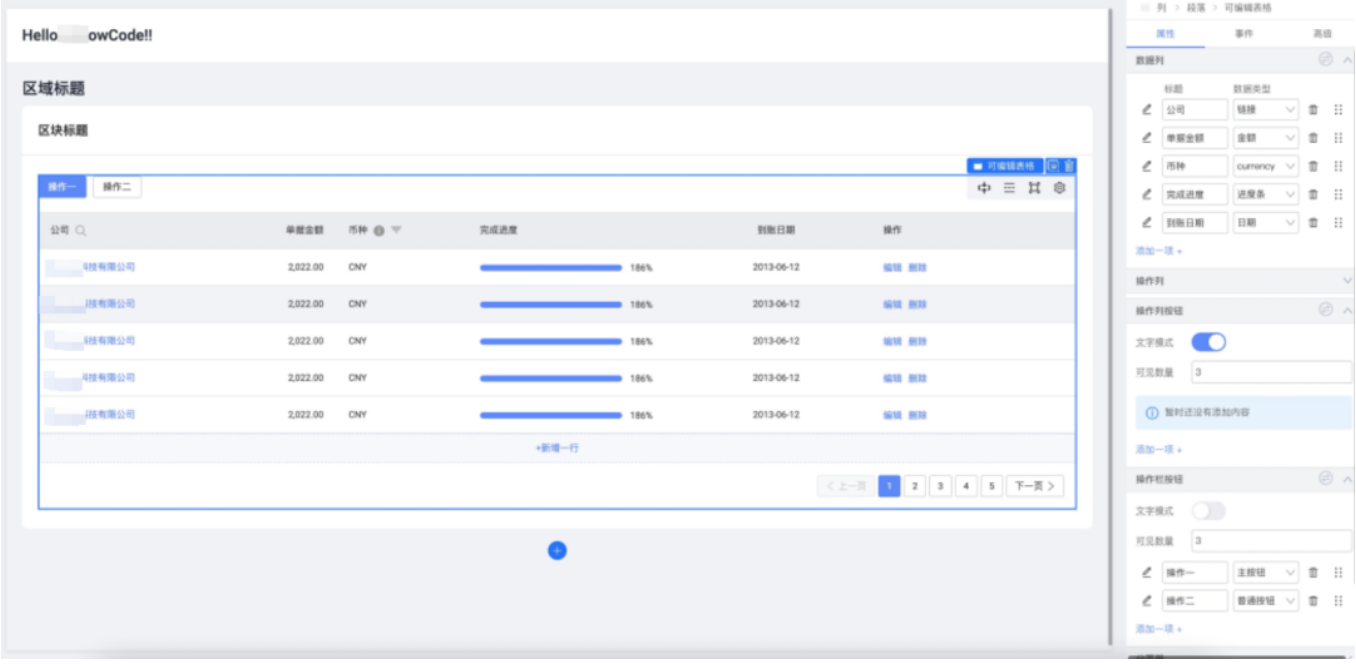
The above configuration method has a better effect on improving efficiency for general scenarios (such as CURD pages with relatively simple background logic) or specific business scenarios (such as venue construction). For relatively complex requirements that require continuous iteration of logic, since configuration is done through graphical operations, the requirements for interactive design are higher and there is a certain cost of getting started. As the complexity of the requirements becomes higher and higher, Configuration form interactions are becoming more and more complex and maintenance costs are getting higher and higher. Therefore, the use of front-end fields in page configuration is relatively restrained .
AI directly generates code
AI-generated code is mostly used in tool function scenarios, but for the needs of specific business scenarios within the company, the following points may need to be considered:
-
Generate customization: The company team has its own technology stack and heavy-duty general components, and this knowledge needs to be pre-trained. Currently, pre-training content for long texts only supports single-session injection, and the token consumption is high;
-
Accuracy: The accuracy challenge of AI-generated code is relatively large. In addition, pre-training contains a large section of prompts. Because the content of the code output is too detailed, coupled with model illusion, the failure rate of business code is currently relatively high. , and accuracy is the core indicator for considering auxiliary encoding. If this cannot be solved, the effect of auxiliary encoding will be greatly reduced;
-
Incomplete generated content: Due to the limitations of a single GPT session, for complex requirements, code generation may be truncated, affecting the generation success rate.
Natural language to instructions
In fact, GPT also has a very important ability, which is to convert natural language into instructions , and instructions are actions. For example: we assume that a function method is implemented, and the input is natural language. Combining GPT with the built-in prompt allows it to stably output a certain A few words, can we take further actions by outputting these words? This has the following advantages over graphical configuration :
-
Low learning threshold: Because natural language itself is the native language of human beings, you only need to describe the page according to your ideas. Of course, the content of the description needs to follow some standards, but compared with graphical configuration, the efficiency is significantly improved. of;
-
Complexity black box: The complexity of graphical configuration will increase with the complexity of the configuration page, and this complexity will be displayed in front of the user at a glance. The user may get lost in the complex configuration page interaction. Configuration Costs gradually rise;
-
Agile iteration: If you want to add a page configuration function on the user side, the interaction method based on the large model may only require the addition of a few prompts, but graphical configuration requires the development of complex forms to facilitate quick input.
You may have a question here:
Wouldn’t the generated instruction information also suffer from the illusion of a large model? How to ensure that the command information generated each time is stable and consistent?
Natural language conversion to instructions is feasible for the following reasons:
-
Converting long text to key information belongs to summary content, and the accuracy of large models in summary scenarios is much higher than that in diffusion scenarios;
-
Since the instruction information only extracts the key information in the requirements and does not require pre-training on the code technology stack, there is a lot of room for optimization of prompts. By optimizing and improving prompt content, the output accuracy can be effectively improved;
-
The accuracy can be verified. For each scenario with different expression requirements input, the accuracy can be verified through the single test prediction output. When a badCase occurs, we will access the single test for the badCase after optimization. Ensure accuracy continues to improve.
Let's take a look at the final information conversion results:
For code assistance, based on the user's demand description, such information can be obtained through PROMPT processing. Provide basic information for code generation.
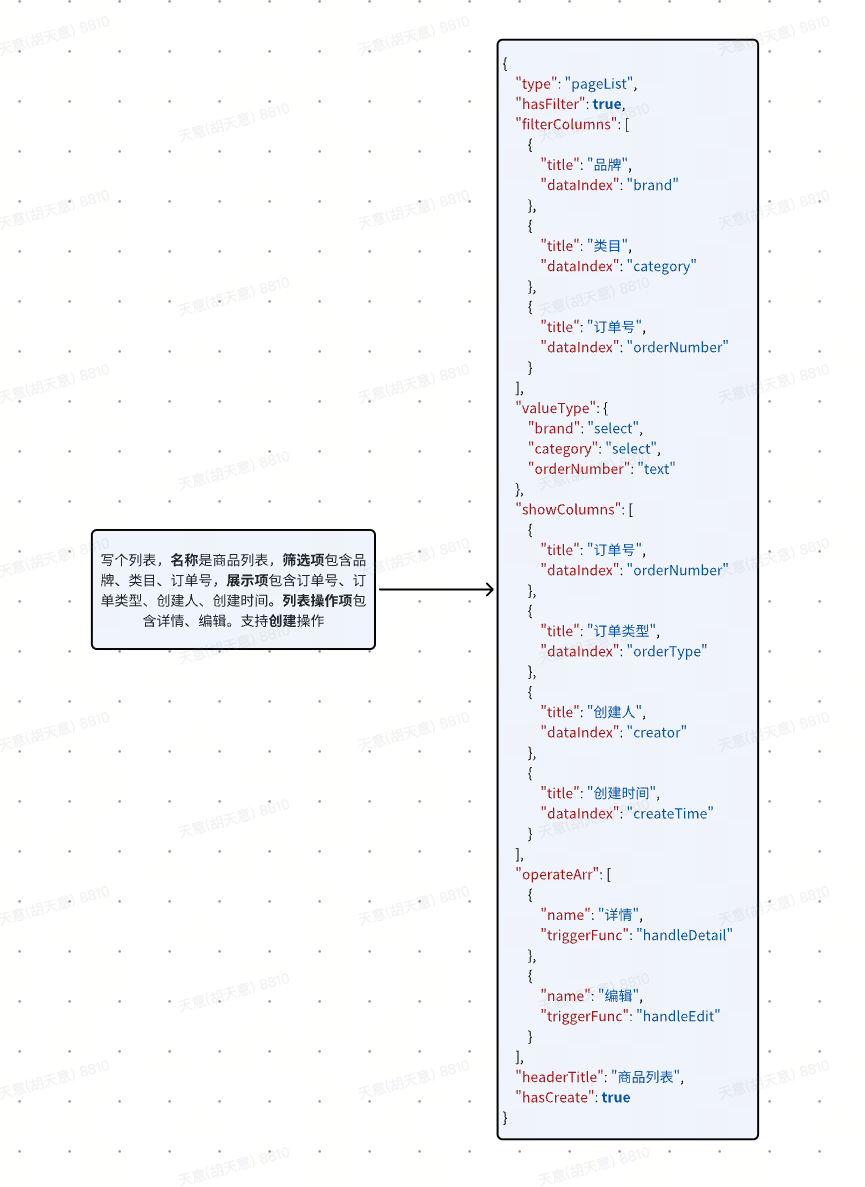
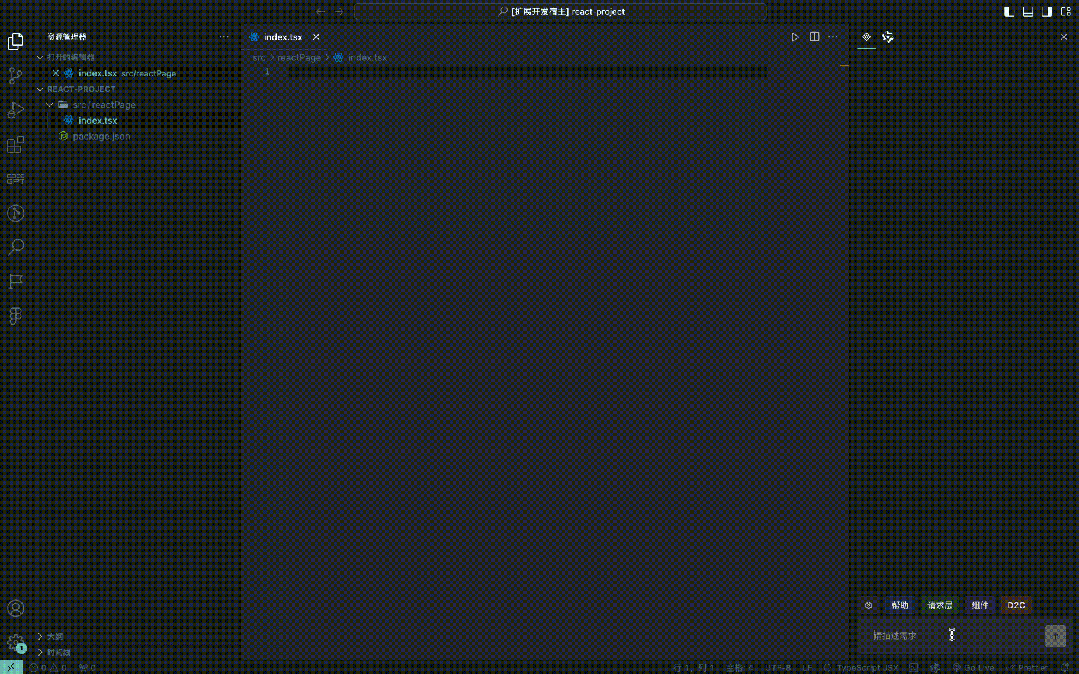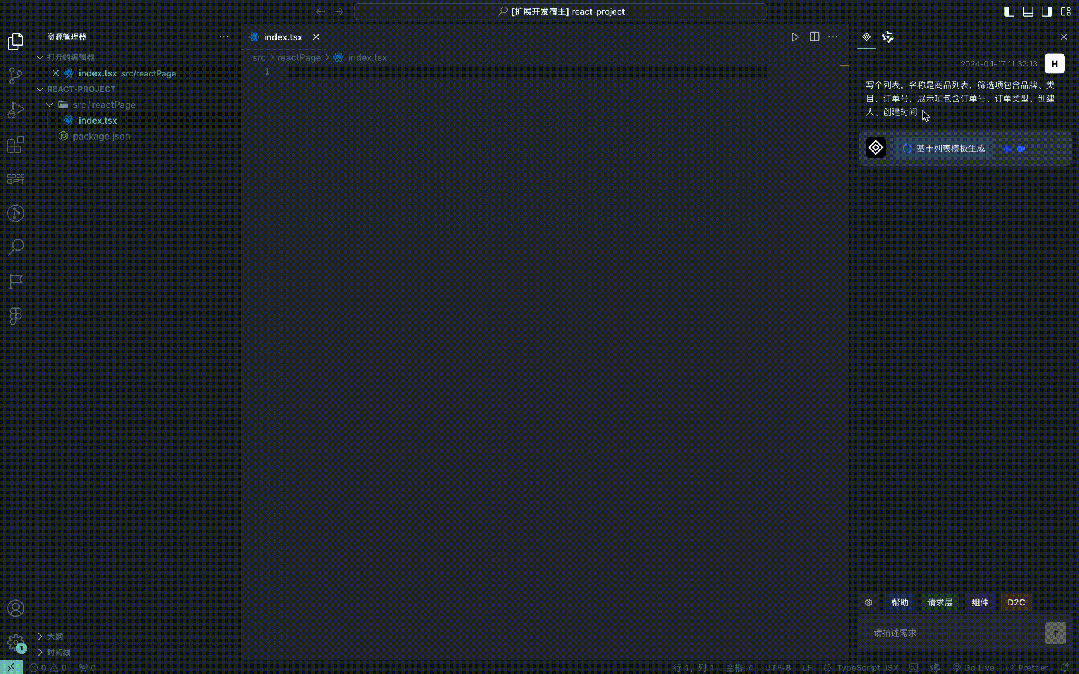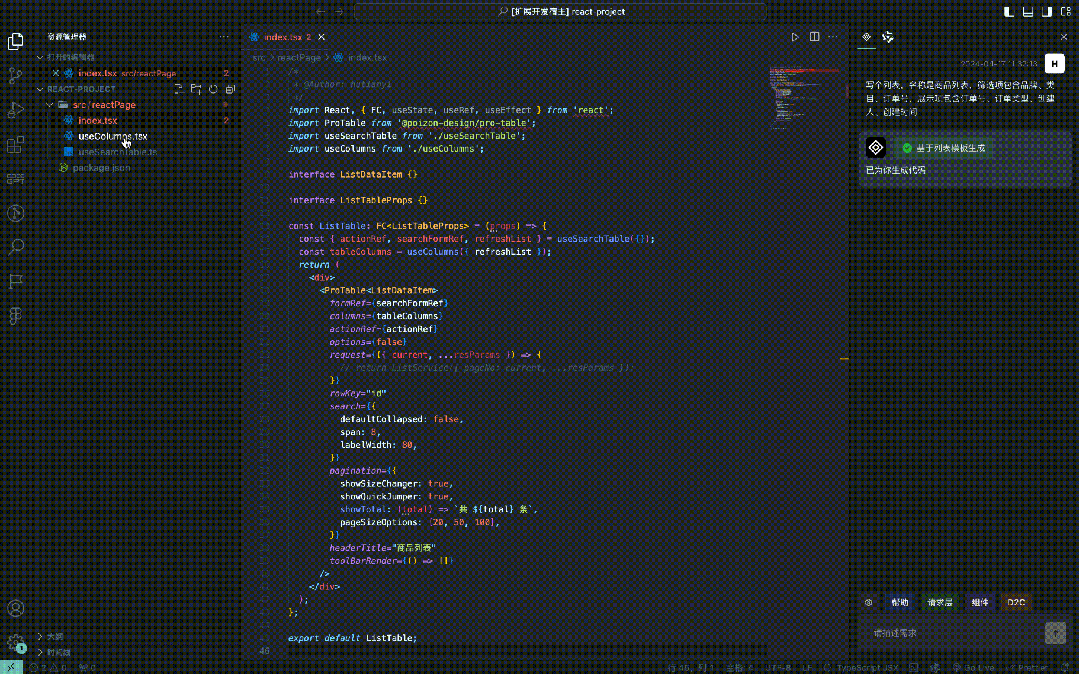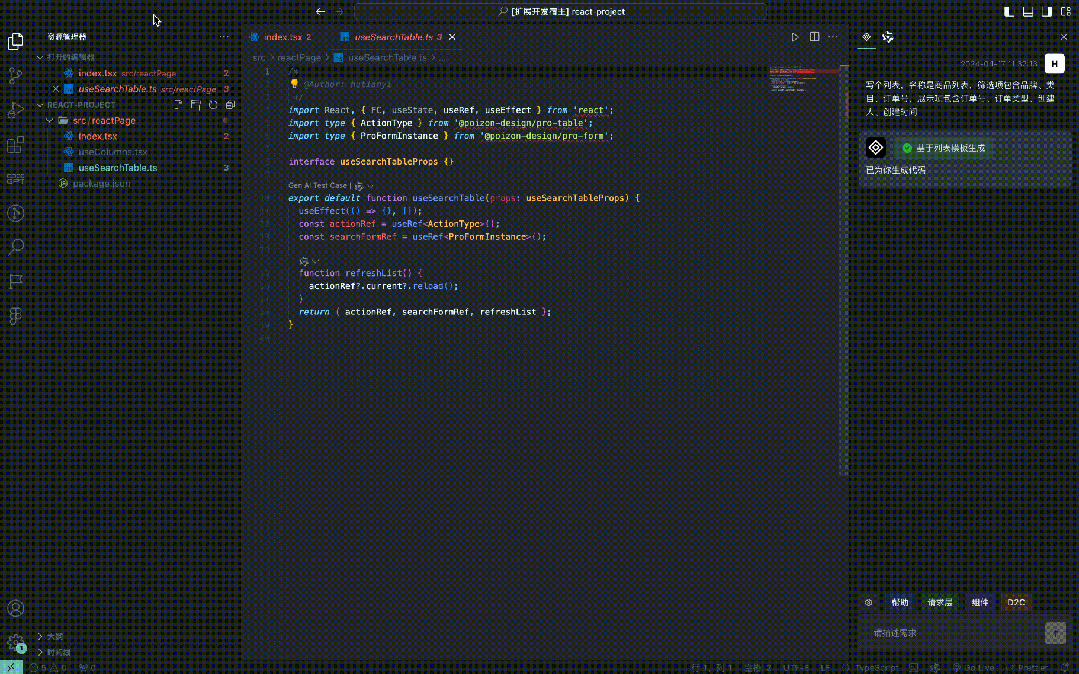
4. Convert information into code
After obtaining the codifiable information corresponding to natural language through the large model (that is, JSON in the above example), we can convert the code based on this information. For a page with a clear scenario, it can generally be divided into main code template (list, form, description frame) + business components.
conversion process

How did we develop the code?
In fact, this step is very similar to developing the code ourselves. After we get the requirements, our brain will extract the key information, that is, the natural language conversion instructions mentioned above . Then we will create a file in vscode, and then perform the following operations :
First, you must create a code template, and then introduce corresponding heavy-duty components according to the scenario. For example, ProTable is introduced for lists, and ProForm is introduced for forms.
Based on heavy-duty components such as ProTable and adding some properties to it, such as headerTitle, pageSize and other list-related information.
Introduce components according to the demand description. For example, if it is recognized that there is a category selection in the filter item, a new business component will be added in useColumns. If it is recognized that there is an import and export component in the demand description, a new import and export business component will be added at the specified position on the page.
Get the mock link, add a request layer, and introduce it at the specified location on the page.
The above common code insertion scenarios can be encapsulated into JSON, and then the corresponding code is generated through code templates combined with AST insertion or string template replacement.
5. Source code generation
position
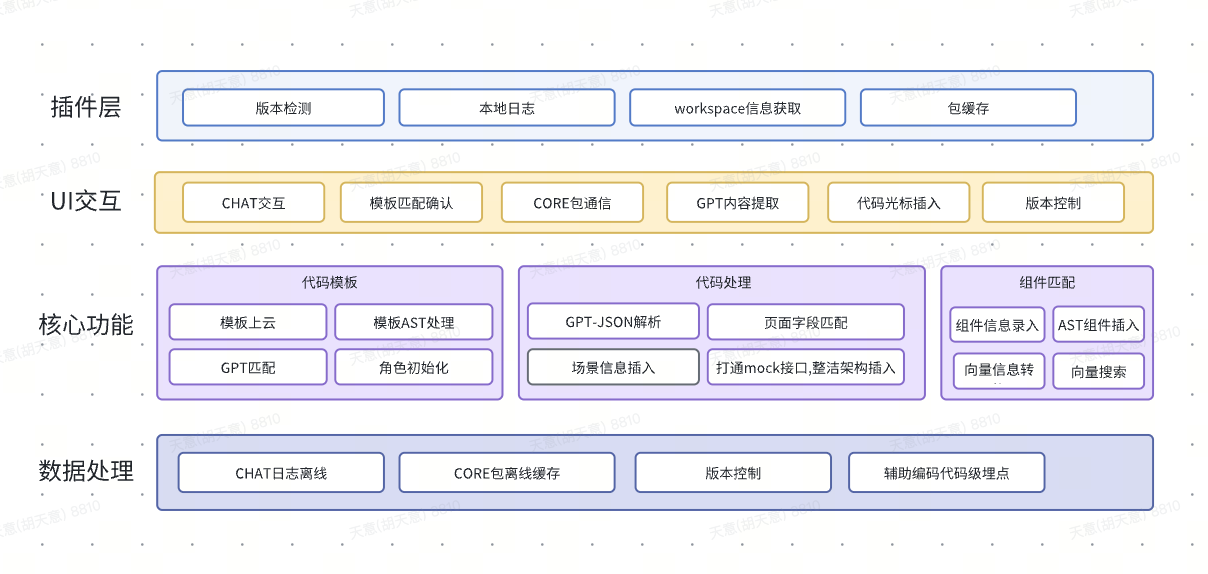
Source code assistance mainly helps developers reduce repetitive work and improve coding efficiency. It is a completely different track from low-code page building. Low-code focuses on building complete pages in specific scenarios, and the number of page functions is enumerable. In the industry Low-code construction also has excellent practices. The source code auxiliary tool is designed to help users initialize as much business requirement code as possible, and subsequent modification and maintenance is handed over to users at the code level, improving the development efficiency of new pages.
The specific functional architecture is shown below:
6. Component vector search and embedding
For front-end development, the essence of improving efficiency is to develop less code. On the one hand, faster page generation, and good component extraction is a very important part. We combined vectors to optimize the introduction links of components. Quickly search and locate components in initialization templates and stock codes.
Component vector introduction link
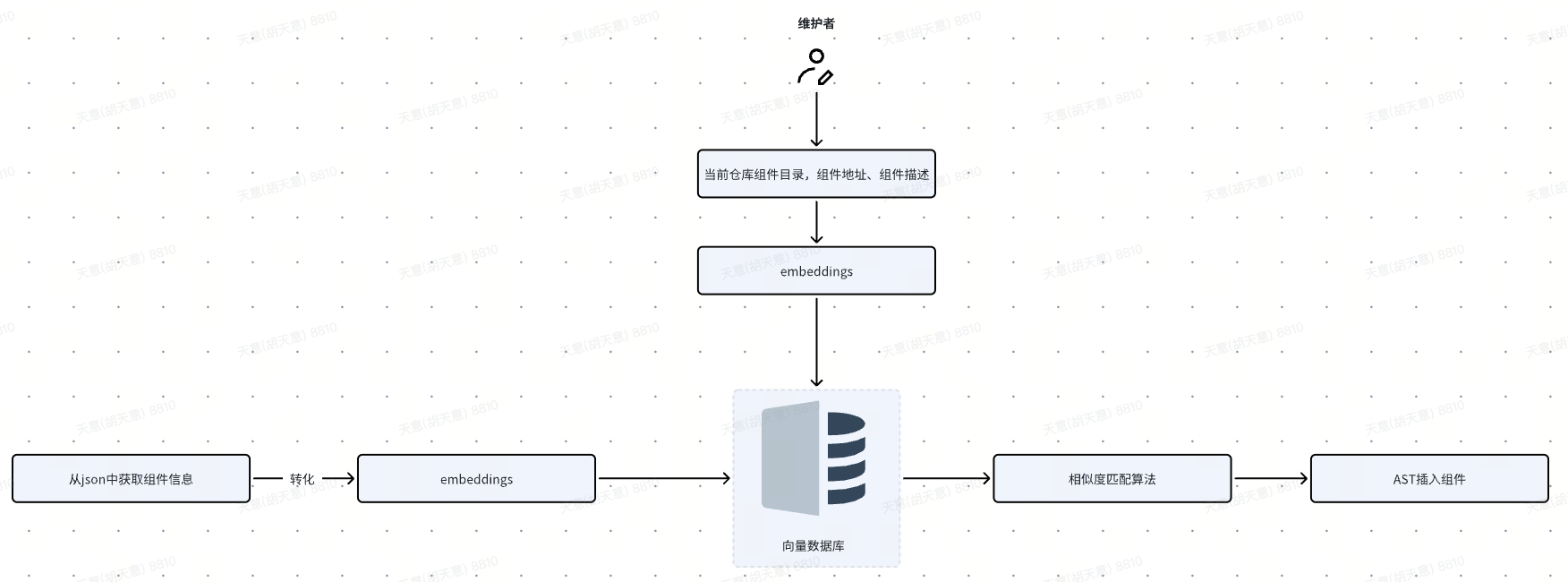
Component information entry
Supports quick acquisition of component description content and component introduction paradigm. Enter components with one click, and the component description will be converted into vector data and stored in the vector database.

Component vector search
After the user inputs the description, the description will be converted into a vector and compared with the component list based on cosine similarity to find the TOP N components with the highest similarity.
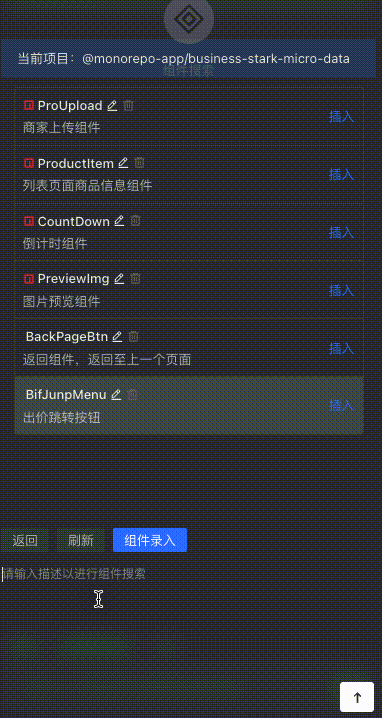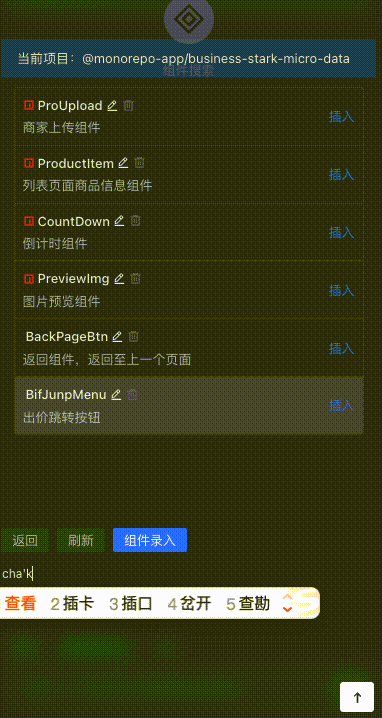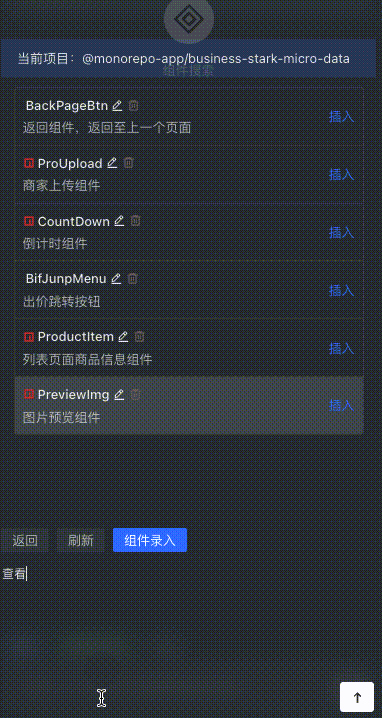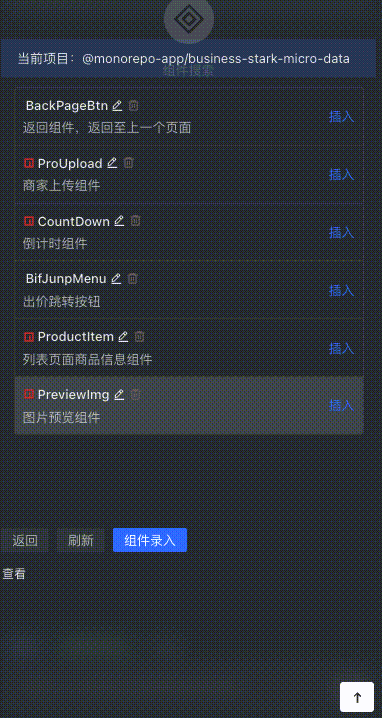
Quick component insertion
Users can quickly search for the component with the highest matching degree in the stock code by describing it, and press Enter to insert it.
7. Future Outlook
-
Component embedding template: Currently, components already support vector search, which is generated by combining source code pages and supports dynamic matching of components and embedding into templates;
-
Editing and generation of existing code: Currently only source code generation for new pages is supported, and local code addition for existing pages will be supported in the future;
-
Code template pipeline: AST's code operation tooling further connects natural language and code writing, improving the efficiency of scene expansion.
*Text/ God’s will
This article is original to Dewu Technology. For more exciting articles, please see: Dewu Technology official website
Reprinting without the permission of Dewu Technology is strictly prohibited, otherwise legal liability will be pursued according to law!
I decided to give up on open source Hongmeng. Wang Chenglu, the father of open source Hongmeng: Open source Hongmeng is the only architectural innovation industrial software event in the field of basic software in China - OGG 1.0 is released, Huawei contributes all source code Google Reader is killed by the "code shit mountain" Fedora Linux 40 is officially released Former Microsoft developer: Windows 11 performance is "ridiculously bad" Ma Huateng and Zhou Hongyi shake hands to "eliminate grudges" Well-known game companies have issued new regulations: employee wedding gifts must not exceed 100,000 yuan Ubuntu 24.04 LTS officially released Pinduoduo was sentenced for unfair competition Compensation of 5 million yuan