
Open-Sora has been quietly updated in the open source community! A single lens now supports video generation up to 16 seconds in resolutions up to 720p and can handle any aspect ratio text-to-image, text-to-video, image-to-video, video-to-video and unlimited length video generation needs. Let's try the effect.
Generate a horizontal screen Christmas snow scene and post it to the B site

Create a vertical screen again and make Douyin

It can also generate long videos with a single shot of 16 seconds, now everyone can become addicted to screenwriting.

How to play? Directions to GitHub: github.com/hpcaitech/Open-Sora
What’s even cooler is that the latest version of Open-Sora is still open source and full of sincerity. The warehouse contains the latest model architecture, the latest model weights, multi-time/resolution/aspect ratio/frame rate training processes, data collection and The complete process of preprocessing, all training details, demo examples and detailed getting started tutorials .
1. Comprehensive interpretation of technical reports
Recently, the author team of Open-Sora officially released the latest version of the technical report [1] on GitHub. Below, we will use the technical report to interpret the functions, architecture, training methods, data collection, pre-processing and other aspects one by one.
1.1 Overview of the latest features
This update of Open-Sora mainly includes the following key features:
- Support long video generation;
- Video generation resolution can reach up to 720p;
- A single model supports any aspect ratio, different resolutions and duration text-to-image, text-to-video, image-to-video, video-to-video and unlimited video generation needs;
- Proposed a more stable model architecture design that supports multi-time/resolution/aspect ratio/frame rate training;
- The latest automatic data processing process is open sourced;
1.2 Space-time diffusion model
This upgrade of Open-Sora has made key improvements to the STDiT architecture in version 1.0, aiming to improve the training stability and overall performance of the model. For the current sequence prediction task, the team adopted the best practices of large language models (LLM) and replaced the sinusoidal positional encoding in temporal attention with the more efficient rotational positional encoding (RoPE embedding).
In addition, in order to enhance the stability of training, they referred to the SD3 model architecture and further introduced QK normalization technology to enhance the stability of half-precision training. In order to support the training requirements of multiple resolutions, different aspect ratios and frame rates, the ST-DiT-2 architecture proposed by the author's team can automatically scale position encoding and handle inputs of different sizes.
1.3 Multi-stage training
The technical report states that Open-Sora uses a multi-stage training method, where each stage continues training based on the weights of the previous stage. Compared with single-stage training, this multi-stage training achieves the goal of high-quality video generation more efficiently by introducing data step by step.
- Initial stage: Most videos use 144p resolution, and are mixed with pictures and 240p and 480p videos for training. The training lasts about 1 week and the total step size is 81k.
- The second stage: increase the resolution of most video data to 240p and 480p, with a training time of 1 day and a step size of 22k.
- The third stage: further enhanced to 480p and 720p, the training duration is 1 day, and the training of 4k steps is completed. The entire multi-stage training process was completed in approximately 9 days.
Compared with 1.0, the latest version improves the quality of video generation in multiple dimensions.
1.4 Unified picture-generating video/video-generating video framework
The author team stated that based on the characteristics of Transformer, the DiT architecture can be easily extended to support image-to-image and video-to-video tasks. They proposed a masking strategy to support conditional processing of images and videos. By setting different masks, various generation tasks can be supported, including: graphic video, loop video, video extension, video autoregressive generation, video connection, video editing, frame insertion, etc.
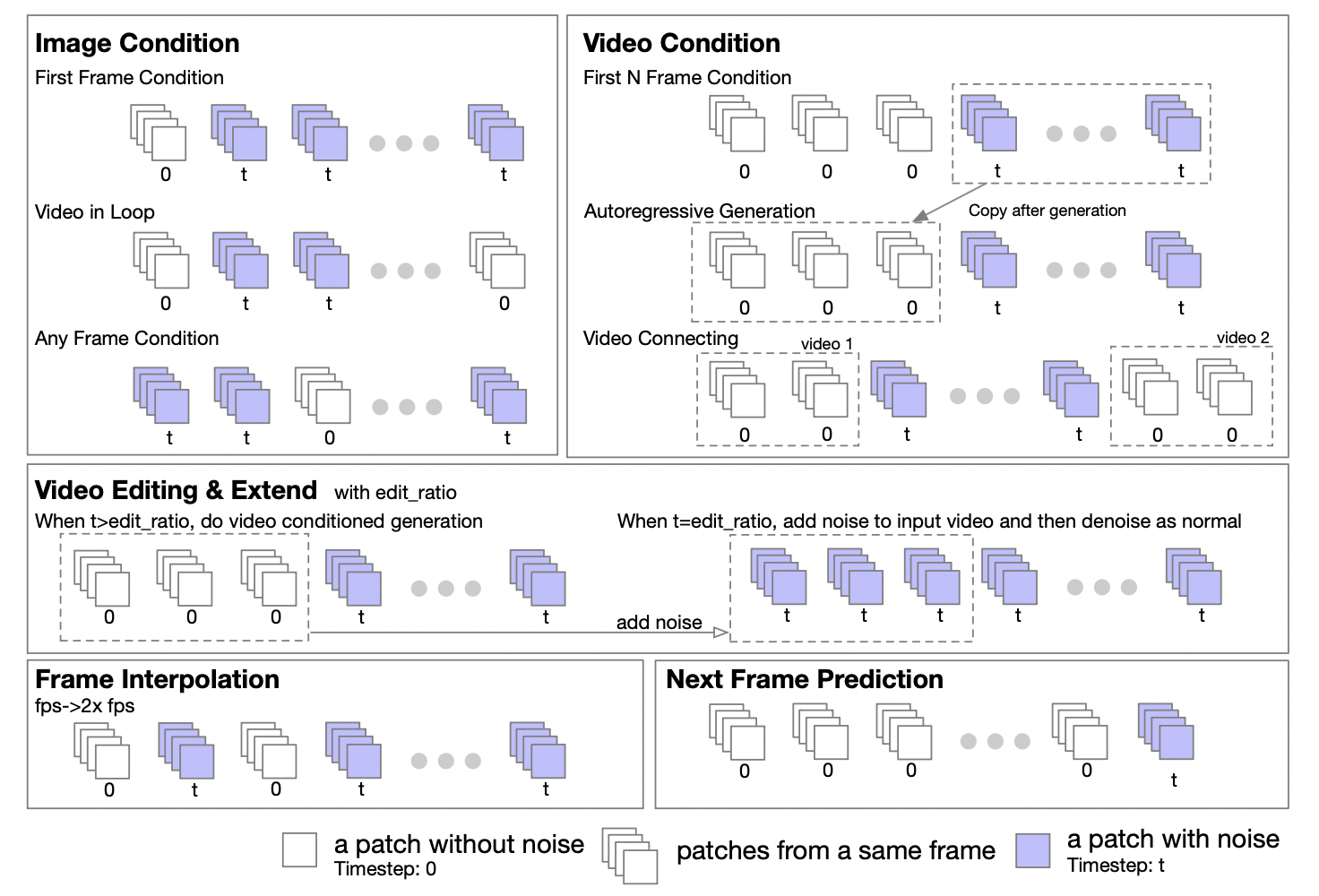
Inspired by the UL2[2] method, they introduced a random masking strategy in the model training stage. Specifically, it is to randomly select and unmask frames during the training process, including but not limited to unmasking the first frame, the first k frames, the next k frames, any k frames, etc. The report also revealed that based on experiments on Open-Sora 1.0, when applying the masking strategy with 50% probability, the model can better learn to handle image conditioning with only a few steps. In the latest version of Open-Sora, they adopted a method of pre-training from scratch using a masking strategy.
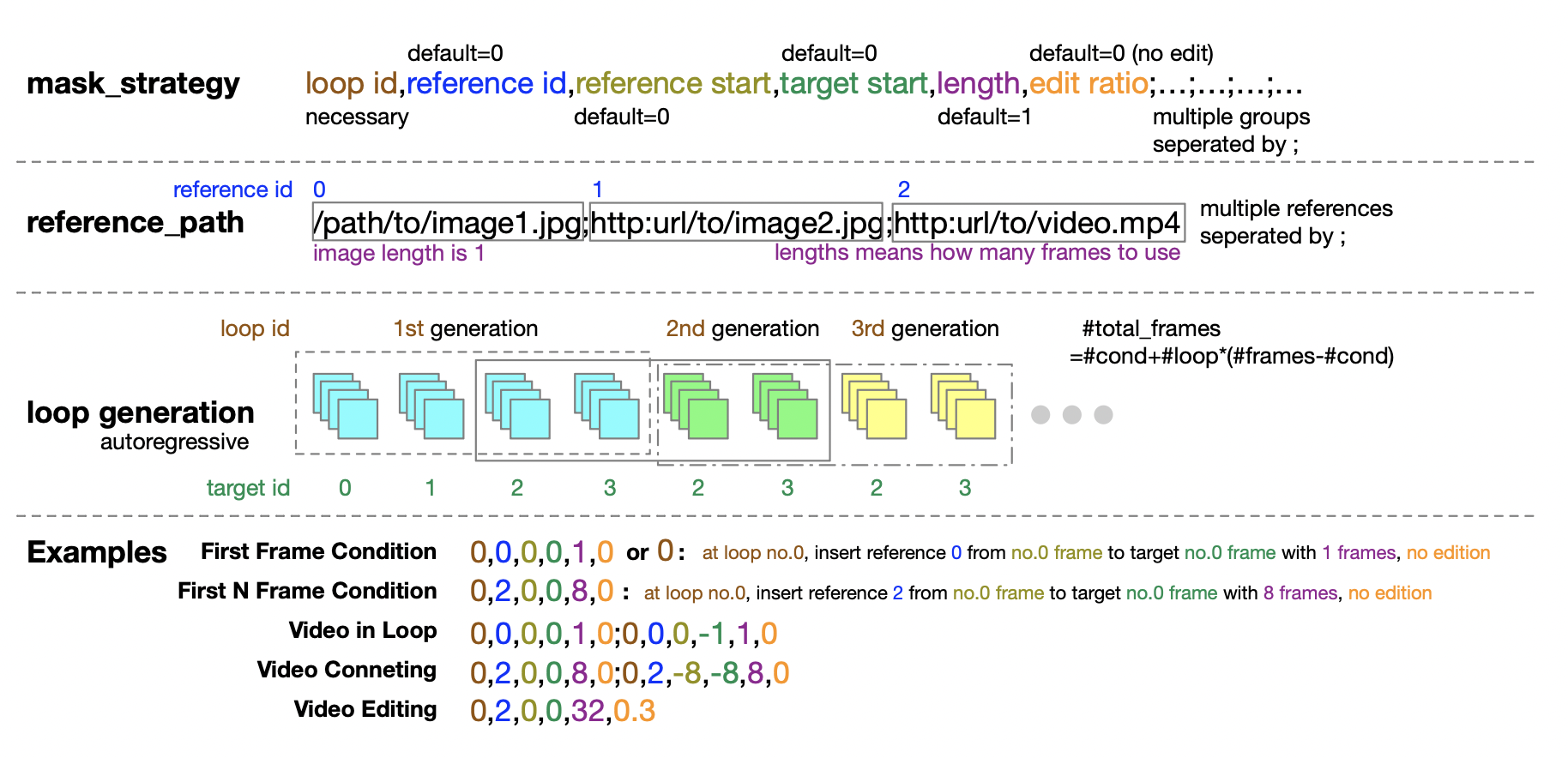
In addition, the author team also thoughtfully provides detailed guidance for masking policy configuration for the inference stage. The tuple form of five numbers provides great flexibility and control when defining the masking policy.
1.5 Supports multi-time/resolution/aspect ratio/frame rate training
OpenAI Sora's technical report [3] points out that training using the resolution, aspect ratio, and length of the original video can increase sampling flexibility and improve frames and composition. In this regard, the author team proposed a bucketing strategy.
How to implement it specifically? Through in-depth reading of the technical report released by the author, we learned that the so-called bucket is a triplet of (resolution, number of frames, aspect ratio). They predefine a range of aspect ratios for videos at different resolutions to cover most common video aspect ratio types. Before each training cycle epochbegins, they reshuffle the dataset and assign samples to corresponding buckets based on their characteristics. Specifically, they put each sample into a bucket whose resolution and frame length are less than or equal to that video feature.
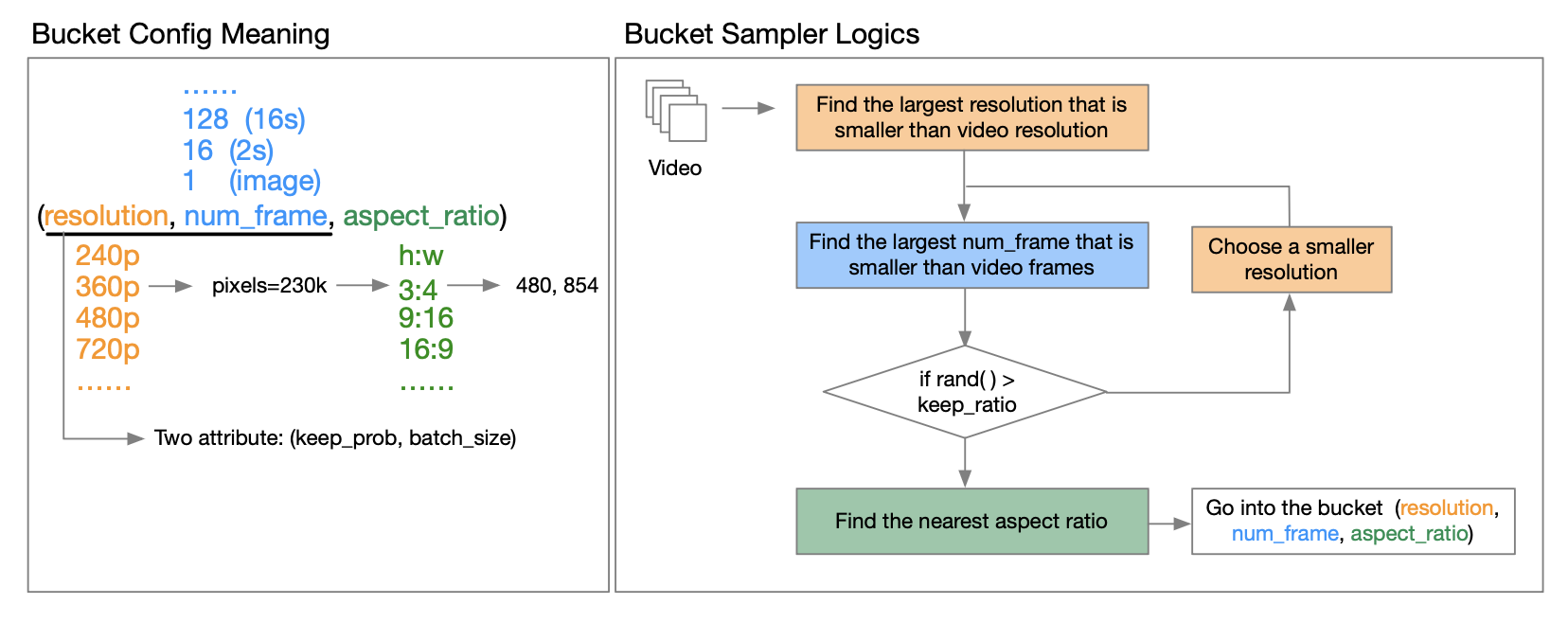
To reduce computational resource requirements, they introduce two attributes (resolution, number of frames) for each keep_proband to reduce computational costs and enable multi-stage training. batch_sizeThis allows you to control the number of samples in different buckets and balance the GPU load by searching for a good batch size for each bucket. This is explained in detail in the technical report. Interested friends can read the technical report on GitHub to get more information.
GitHub address: github.com/hpcaitech/Open-Sora
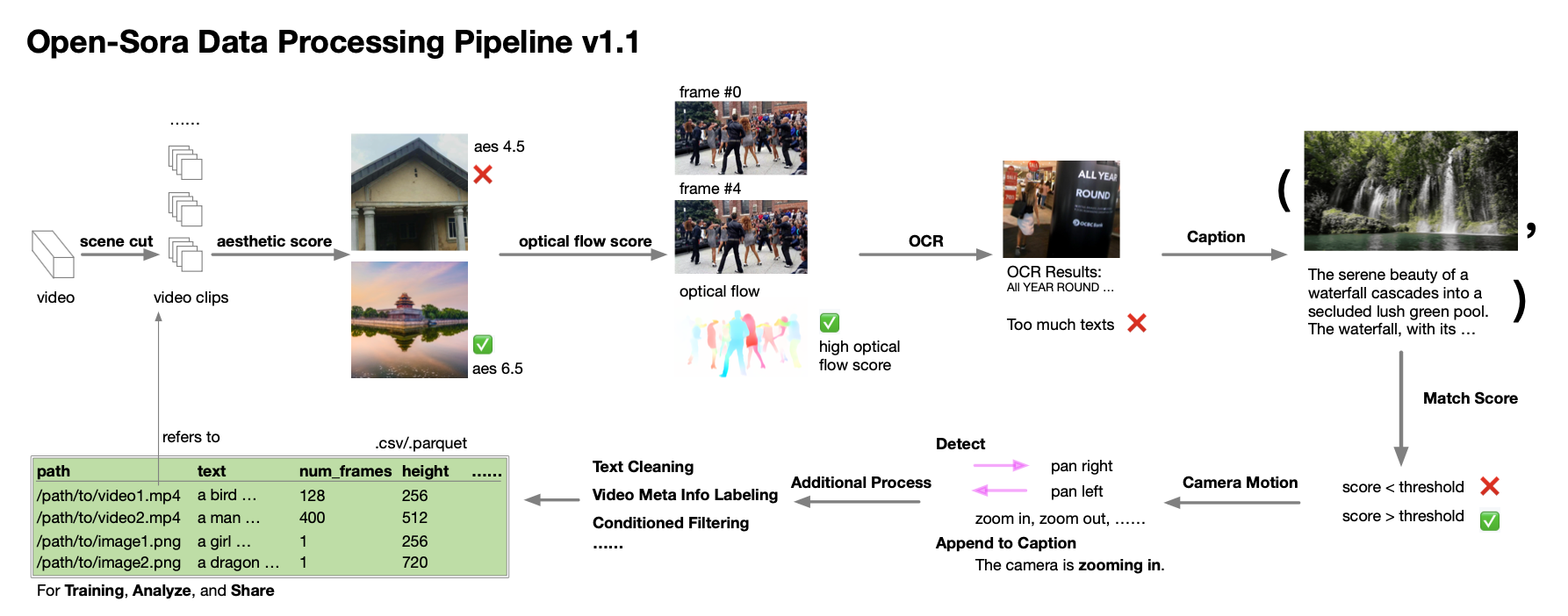
1.6 Data collection and preprocessing process
The author team even provides detailed guidance on data collection and processing. According to the technical report, during the development process of Open-Sora 1.0, they realized that the quantity and quality of data are extremely critical to cultivating a high-performance model, so they worked to expand and optimize the data set. They established an automated data processing process that follows the singular value decomposition (SVD) principle and covers scene segmentation, subtitle processing, diversity scoring and filtering, as well as the management system and specification of the data set.
Likewise, they selflessly share data processing related scripts to the open source community. Interested developers can now use these resources, combined with technical reports and code, to efficiently process and optimize their own data sets.
2. Comprehensive performance evaluation
Having said so many technical details, let us enjoy the latest video generation effects of Open-Sora and relax.
The most eye-catching highlight of this update of Open-Sora is that it can capture and transform the scene in your mind into a moving video through text description. The images and imaginations that flash through your mind can now be permanently recorded and shared with others. Here, the author tried several different prompts as a starting point.
2.1 Landscape
For example, the author tried to generate a video of a tour in a winter forest. Not long after the snow fell, the pine trees were covered with white snow. Dark pine needles and white snowflakes were scattered in clear layers.

Or, in a quiet night, you are in a dark forest like that described in countless fairy tales, with the deep lake sparkling under the bright stars all over the sky.

The night view overlooking the bustling island from the air is even more beautiful. The warm yellow lights and the ribbon-like blue water make people instantly drawn into the leisurely time of vacation.

The city is bustling with traffic, and the high-rise buildings and street shops with lights still on late at night have a different flavor.

2.2 Natural organisms
In addition to landscapes, Open-Sora can also restore various natural creatures. Whether it is a small red flower,

Whether it’s a chameleon slowly turning its head, Open-Sora can generate more realistic videos.

2.3 Different resolutions/aspect ratios/durations
The author also tried a variety of prompt tests and provided many generated videos for your reference, including different content, different resolutions, different aspect ratios, and different durations.



The author also found that with just one simple command, Open-Sora can generate multi-resolution video clips, completely breaking creative limitations.



2.4 Tusheng Video
We can also feed Open-Sora a static image and have it generate a short video.

Open-Sora can also cleverly connect two still images. Click on the video below and it will take you to experience the changes of light and shadow from afternoon to dusk. Each frame is a poem of time.

2.5 Video editing
For another example, we want to edit the original video. With just a simple command, the originally bright forest ushered in a heavy snowfall.


2.6 Generate high-definition pictures
We can also enable Open-Sora to generate high-definition images:

It is worth noting that Open-Sora’s model weights have been made publicly available on their open source community for free. Since they also support the video splicing function, this means you have the opportunity to create a short short story with a story for free to bring your creativity into reality.
Weight download address: github.com/hpcaitech/Open-Sora
3. Current limitations and future plans
Although Open-Sora has made good progress in reproducing Sora-like Vincent video models, the author team also humbly pointed out that the currently generated videos still need to be improved in many aspects, including noise issues during the generation process, time A lack of consistency, poor character generation quality, and low aesthetic scores.
Regarding these challenges, the author team stated that they will give priority to solving them in the development of the next version in order to achieve higher video generation standards. Interested friends may wish to continue to pay attention. We look forward to the next surprise that the Open-Sora community brings to us.
GitHub address: github.com/hpcaitech/Open-Sora
references:
[1] https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_02.md
[2] Tay, Yi, et al. "Ul2: Unifying language learning paradigms." arXiv preprint arXiv:2205.05131 (2022).
[3] https://openai.com/research/video-generation-models-as-world-simulators
I decided to give up on open source Hongmeng. Wang Chenglu, the father of open source Hongmeng: Open source Hongmeng is the only architectural innovation industrial software event in the field of basic software in China - OGG 1.0 is released, Huawei contributes all source code Google Reader is killed by the "code shit mountain" Fedora Linux 40 is officially released Former Microsoft developer: Windows 11 performance is "ridiculously bad" Ma Huateng and Zhou Hongyi shake hands to "eliminate grudges" Well-known game companies have issued new regulations: employee wedding gifts must not exceed 100,000 yuan Ubuntu 24.04 LTS officially released Pinduoduo was sentenced for unfair competition Compensation of 5 million yuan