Building and maintaining a billion-level search engine is not easy, and there is no once-and-for-all optimal management method. This article is the result of continuous learning and summary in practice. It introduces how to build a search system that can support products ranging from tens of millions to hundreds of millions, and realize the increase of total query QPS from hundreds to thousands, and write the total QPS The process of increasing from level 100 to level 10,000. Among them, ES resource expansion is essential, but in addition, this article will also focus on some ES performance issues that cannot be solved by expansion. I hope that through this article, you can have more data and usage reference for ES usage scenarios. Due to limited space, the part about stability governance will be introduced in the next article.
Business introduction
The platform investment management system serves the multi-entity investment scenario of Douyin e-commerce platform activities. It will collect and select products through the investment platform, and then distribute the products to various C-side systems. The entities that attract investment are also very diverse, including live broadcast rooms, product investment, coupon investment, etc. Among them, product investment is our largest investment entity.
Investment platform service structure
data center
The data center is an ES-based search service that provides configurable, scalable, and universal data acquisition and orchestration services. It is a universal service that supports data query on the investment platform.
Key concepts to understand:
-
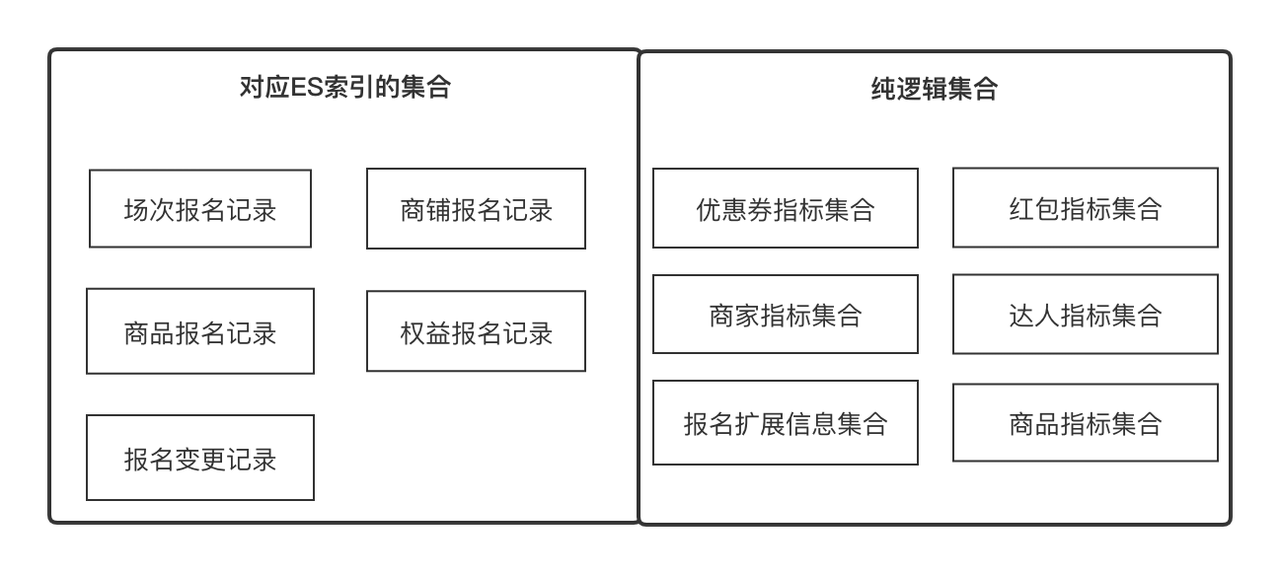
Indicators
: Indicators are metadata that we use to describe an attribute of an entity or object, such as product name, store experience score, expert level, registration record ID. At the same time, it can also be the minimum update and acquisition of an object. Unit, such as product price comparison information. We can define all fields with clear semantics as indicators
.
-
Set
: represents a set that can be converged by some commonality, such as product attribute set and store attribute set, which can be obtained by product ID and store ID respectively. It can also be a product registration record collection, which can be obtained by registration record ID. It is In business terms, it expresses a set of related indicators, and the indicators are in a one-to-many relationship.
-
Solution
: Data acquisition solution. We abstract the two concepts of indicators and collections so that data can be obtained in the smallest unit and can be continuously expanded horizontally. Solution helps us abstract how to obtain indicators under different collections.
-
Custom header
: Custom header refers to the Title to be displayed in any two-dimensional row data list. It has a one-to-many relationship with the indicator;
-
Filter item
: The filter item refers to the filter item that needs to be used in any two-dimensional row data list. It can indicate a 1-to-1 relationship;
-
Audit view
: The audit view refers to an audit page that can be dynamically rendered from a set of custom headers and a set of filter items in an audit business scenario.
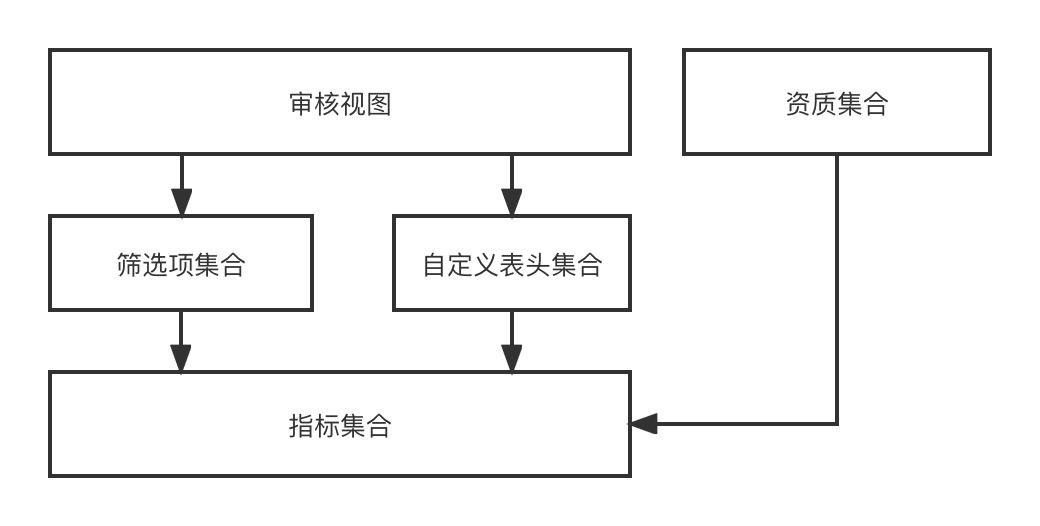
In the functional design, through the indicator-->[Filter items, custom header]-->Audit view-->the process of finally dynamically rendering an audit page. Since we are recruiting investment with multiple entities and multiple scenarios, different entities have different scenarios. Different audit views are required, so this series of capabilities we designed can dynamically combine any required audit view effects.
The data center provides general data acquisition capabilities for upper-layer businesses, including data synchronization and data query. There are currently two data sources, the external RPC interface and the registration record ES. The data center integrates two sets of data acquisition solutions, which are completely unaware of the outside world, that is, it only needs to obtain which data indicators under which collection.
The purpose of building ES is to support the screening and statistical capabilities of investment registration records and output the data content it wants for the upper-level business.
Build an ES cluster from 0 to 1
To build a system from 0 to 1, on the basis of meeting basic business needs, the stability needs to support the following two points;
-
The basic disaster recovery mechanism means that when the performance of the system is affected due to changes in basic components and read and write traffic, the business can adjust itself in time.
-
The final consistency of data means that the registration record DB --> ES multi-machine room data is complete.
Program research
ES cluster capacity assessment
The ES cluster capacity evaluation is to ensure that the cluster can provide stable services for a period of time after it is built. It mainly needs to be able to solve the following problems:
-
How many shards should be set for each index, how much subsequent data increment is expected, and read and write traffic estimates;
-
How many data instances should be set up in a single cluster, and what specifications should be used for a single data instance;
-
Understand the difference between vertical expansion and horizontal expansion, what is our response strategy when the data volume surges unexpectedly, or the traffic surges unexpectedly, and how should ES cluster disaster recovery be designed.
Key solutions:
-
Once the number of ES index shards is set, it cannot be modified, so it is important to determine the number of shards. Usually the number of shards is an integer multiple of the ES instance to ensure load balancing;
-
The size of a single shard is relatively reasonable between 10 and 30G. Excessive indexing will affect query performance;
-
The surge in traffic can be solved by capacity expansion, and the surge in data can be solved by deleting old data or increasing the number of shards; and it must be deployed with a multi-machine room disaster recovery deployment plan, so that each other is a disaster-tolerant machine room.
Data synchronization link selection
It mainly solves how to synchronize DB registration records to ES, how to write other related indicators to ES, and how to update and ensure data consistency.
-
DB -> ES needs to be a quasi-real-time data stream, and changes in registration records and other information must be searchable in quasi-real-time;
-
In addition to its own fields, the registration record also needs to supplement its attribute fields such as registered products, stores, and experts. It is also written to ES and
can support partial updates
, so the ES writing method can only be the Upsert method;
-
Updates to individual registration records must be in order and must not conflict.
ES index basic configuration survey
Understand essential ES fundamentals and configurations.
-
{"dynamic": false} avoids the automatic expansion of es mappings or the addition of unexpected index types;
-
index.translog.durability=async, refreshing translog asynchronously will help improve writing performance, but there is a risk of data loss;
-
The default refresh interval of ES is 1s, which means that the data can be found as soon as one second after successful writing.
Data synchronization solution
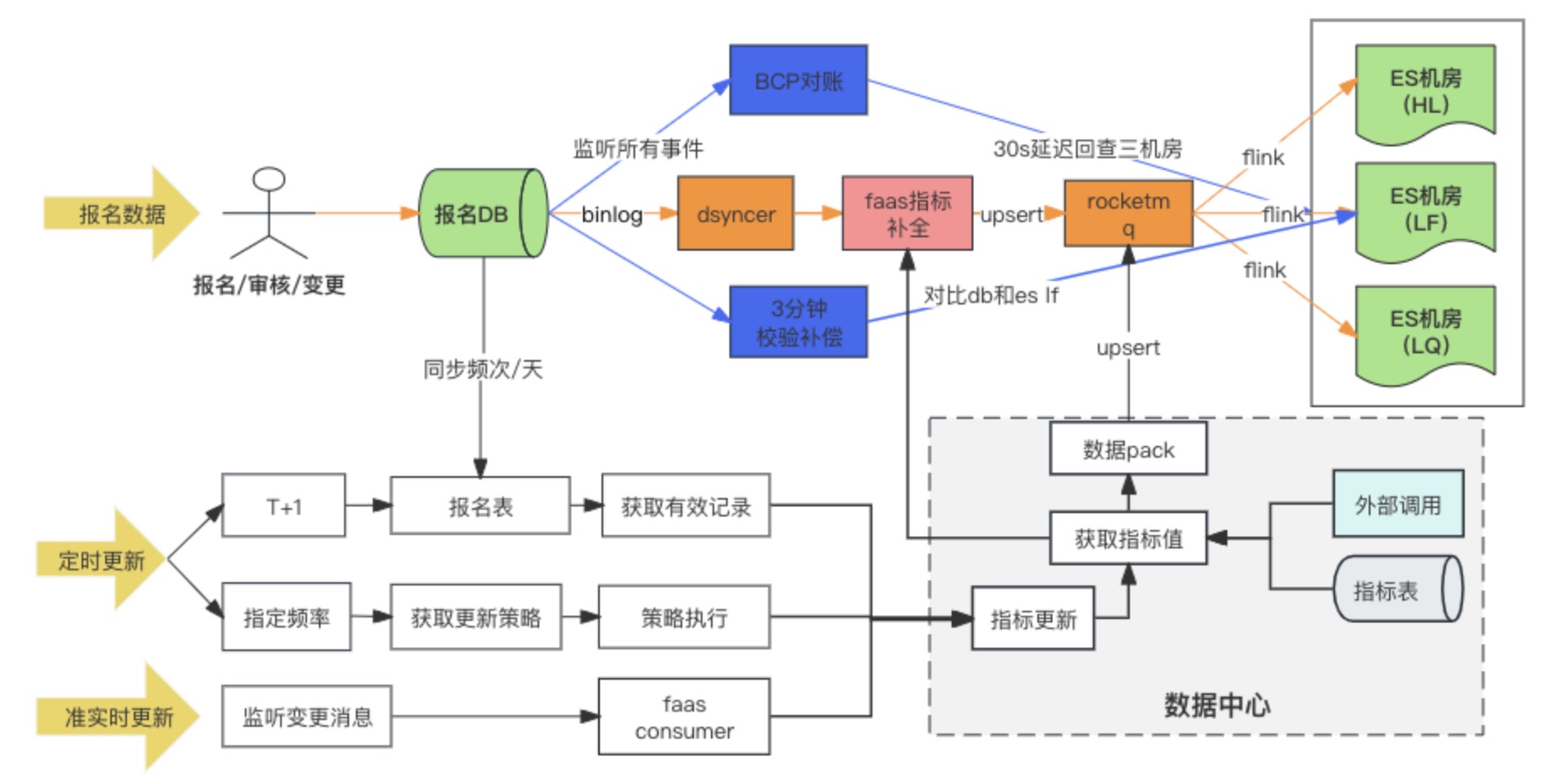
Data synchronization link diagram
DB --> ES data synchronization solution ultimately adopts the method of synchronous writing of heterogeneous data to RocketMQ + Flink for multi-machine room consumption. At the same time, when the registration record is written for the first time, the extended indicators are filled in through the Faas custom conversion script, and the update dependencies of the extended indicators are Change the two methods of message listening and scheduled tasks. During the research, there were actually three options for DB -> ES multi-computer room. In the end, we chose the third option. Here we compare the differences between the three options:
Solution 1: Directly write to ES multi-machine room through heterogeneous data synchronization (Dsyncer)
shortcoming:
-
Direct writing is at a disadvantage in meeting the requirements of ES to deploy multiple computer rooms simultaneously, because it cannot guarantee successful writing in multiple computer rooms at the same time. Is it okay to deploy multiple heterogeneous data and write them separately? Yes, that is, the workload is tripled to about a dozen indexes.
-
The write capability of direct write Bulk is relatively weak, and the write spikes will be more obvious as the traffic fluctuates, which is not friendly to the write performance of ES.
-
Direct writing cannot guarantee the orderly update of a single registration record when ES has multiple update entries. Can I increase the global version? Yes, but too heavy.
Advantages:
The shortest dependency path, low write latency, and minimal system risk. It is absolutely no problem for small-traffic businesses and businesses with simple synchronization scenarios.
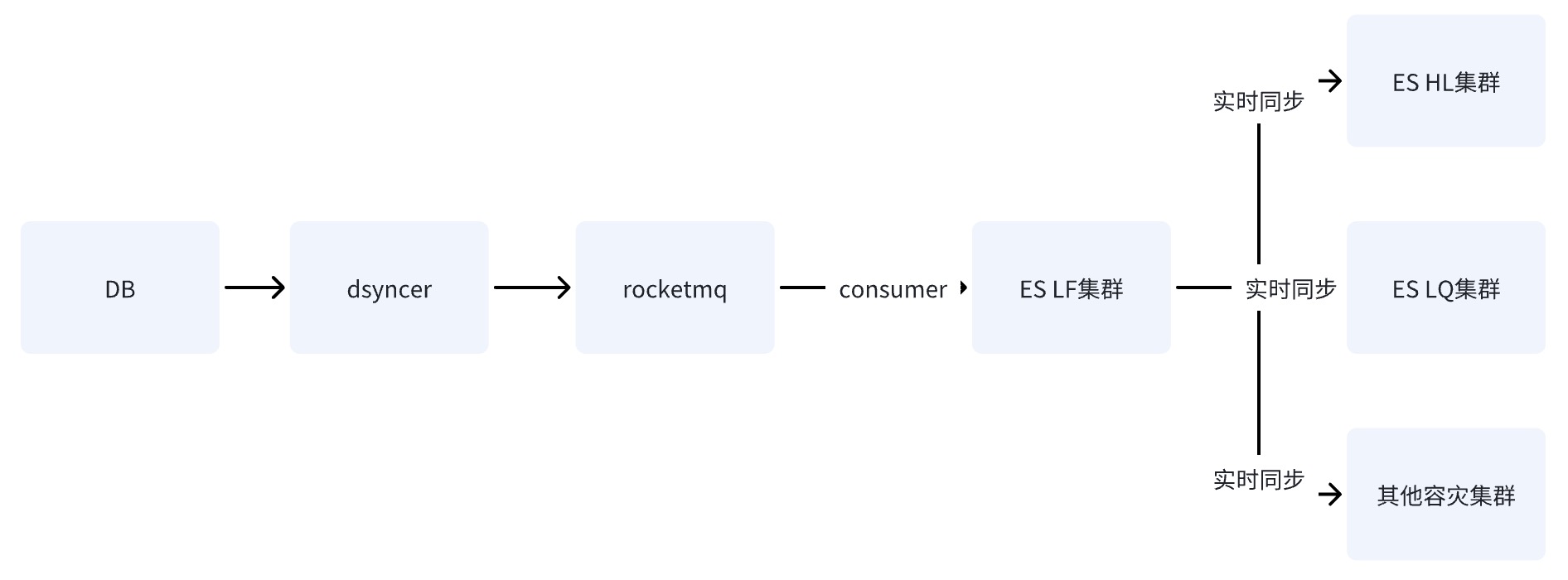
Option 2: Write ES single computer room through RocketMQ
After DB writes to the ES single computer room through RocketMQ, the data is synchronized to other computer rooms through the data cross-cluster replication capability provided by ES.
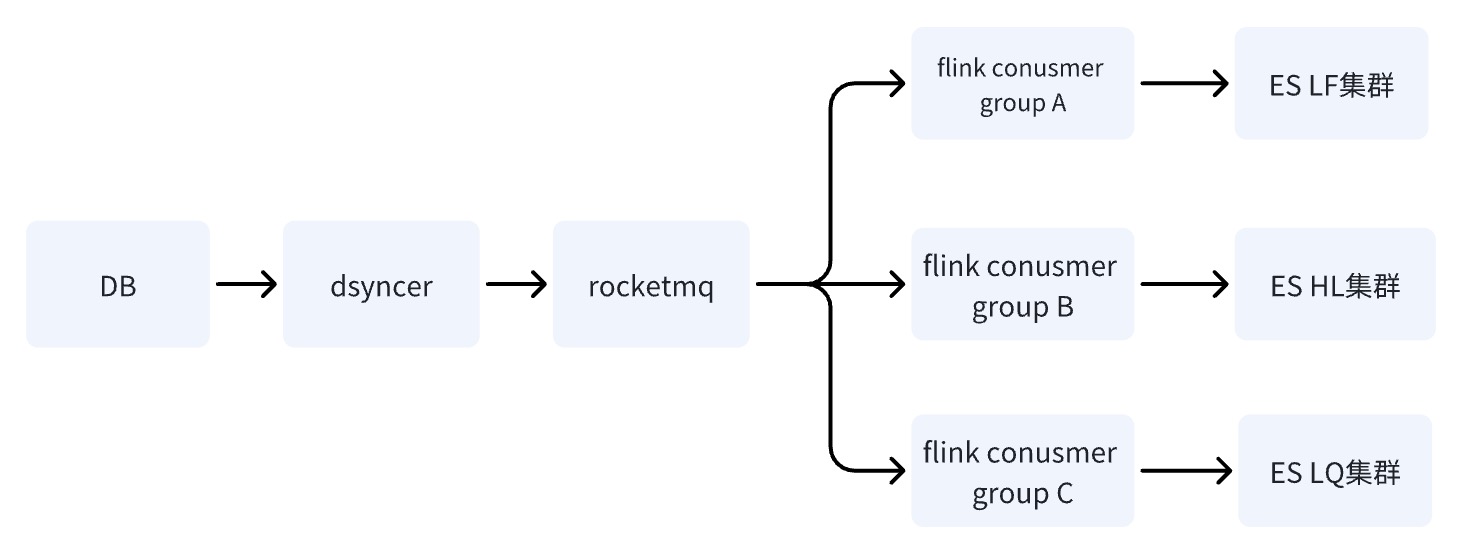
Option 3: Write ES multi-machine room through RocketMQ + Flink ✅
When DB writes to the ES cluster through RocketMQ, multiple independent Consumer Group tasks are started. The system can use the Flink distributed system to write data to multiple computer rooms.
There is only one difference between scheme two and scheme three: the way of writing to multiple computer rooms is different. Scheme two is to write to one computer room, and then synchronize the data to other computer rooms in quasi-real time, while scheme three is to write multiple independent consumers separately. engine room.
The disadvantages of options two and three are the same: the dependency path is the longest, and the write delay is easily affected by the jitter of basic components. However, the fatal disadvantage of option two is that there is a
single point of risk in the system
. Assuming that data is synchronized to HL and LQ through LF, Then the system will become unusable after LF hangs up.
The advantage of option three is that the writing links of multiple computer rooms are independent of each other. Compared with option two, if any link has problems, it will not cause risks to the business; RocketMQ can easily solve the single Key sequential update problem,
which is also undesirable for option one. reason
.
Why can writing through RocketMQ solve the problem of out-of-order and conflict?
-
First of all, ES writing is controlled by optimistic locking based on the Version number. If the same record is updated concurrently at the same time, then the Version we get at the same time is the same, assuming it is 1, then everyone will update the Version to 2 to write. , conflicts will occur, and conflicts will always cause the problem of lost updates;
-
General business scenarios require orderly consumption based on Key and Partition ordering. Ordered consumption requires two necessary conditions: when messages are stored, they must be consistent with the order in which they are sent; when messages are consumed, they must be consistent with the order in which they are stored. .
Therefore, if the business wants to consume messages in an orderly manner, it needs to ensure that the messages sent with the same Key are sent to the same Partition, and the consumed messages ensure that the messages with the same Key are always consumed by the same Consumer. But in fact, the two necessary conditions mentioned above are ideal. In some cases, they cannot be completely guaranteed, such as Consumer Rebalance. For example, writing a certain Broker instance keeps failing. The reasons and solutions will be analyzed below. .
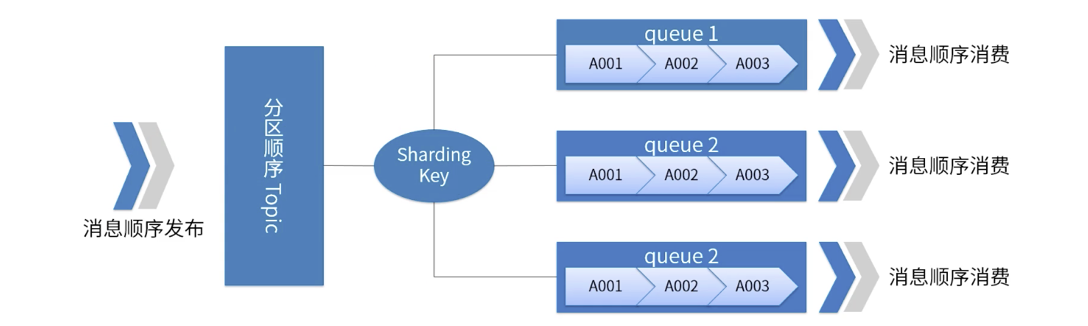
A picture illustrates RocketMQ partition order
-
For a specified Topic, all messages are divided into multiple (Queue) according to Sharding Key.
-
Messages in the same Queue are published and consumed in strict FIFO order.
-
Sharding Key is a key field used to distinguish different partitions in sequential messages. It is a completely different concept from the Key of ordinary messages.
-
Applicable scenarios: High performance requirements. Determine which Queue the message is sent to based on the Sharding Key in the message. Generally, orderly partitioning can meet our business requirements and has high performance.
What needs to be noted here is
that
RocketMQ may have helped the business solve 99% of the out-of-order problems, but it is not 100%. In extreme cases, messages may still have out-of-order consumption problems, such as the ABA phenomenon, such as when Partiton fails, the message is Repeatedly sent to other Partition queues, etc., so consistency reconciliation is essential.
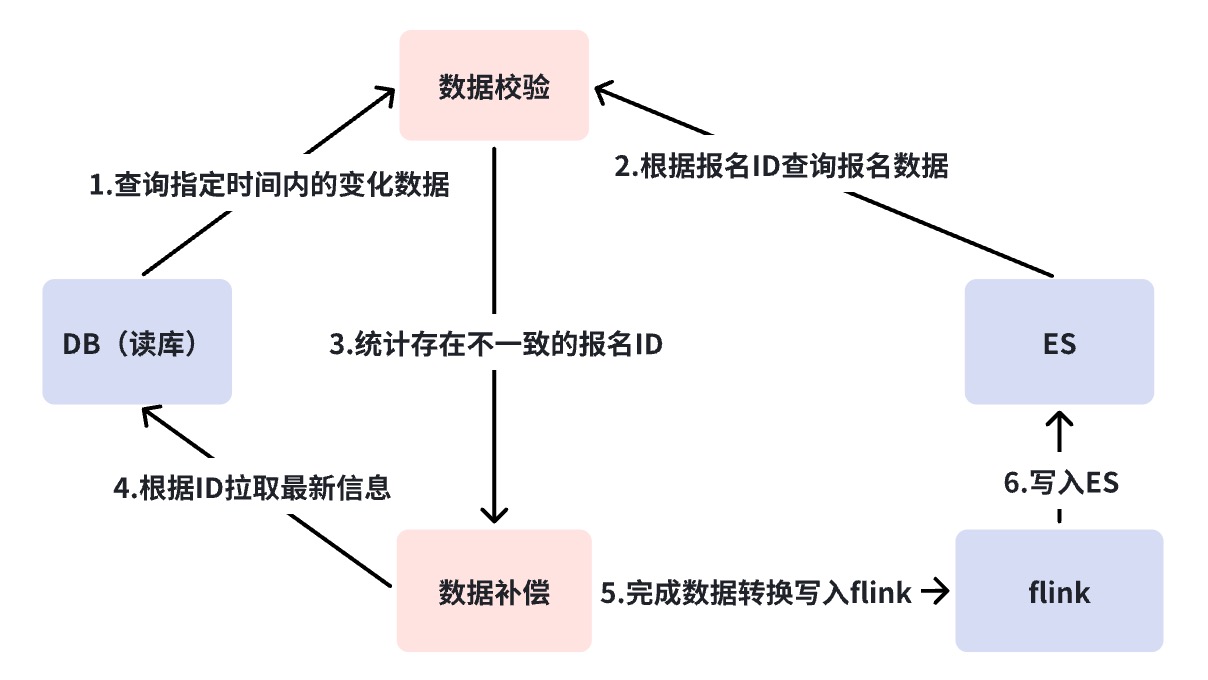
Multi-layer reconciliation mechanism
The reconciliation mechanism solves the data consistency problem of DB->ES. As mentioned earlier, DB --> ES is a quasi-real-time data flow, and the dependency link is relatively long. We need corresponding monitoring in different states. , reconciliation and compensation strategies to ensure eventual data consistency.
Here we have done a three-layer reconciliation. We use the reconciliation platform to achieve minute-level reconciliation and offline reconciliation. The reasons for the need for multi-layer reconciliation will be explained one by one below.
DB synchronization ES link failure analysis diagram
Business Verification Platform ( BCP ) second-level reconciliation
Referring to the above figure, you will find that DB --> ES synchronization depends on many dependent components. In this case, we need a
reconciliation from a global perspective
to discover synchronization link problems, that is, BCP real-time reconciliation.
BCP reconciliation is a single-stream reconciliation that monitors the Binlog and directly checks the ES multi-machine room reconciliation. It only relies on the Binlog stream. Data synchronization delays or blockages in the intermediate links can be quickly discovered through BCP reconciliation; careful students will find that if Binlog is cut off, and BCP reconciliation cannot be corrected. How to solve this situation will be discussed later, but at least it can be seen that except for DB->DBus, BCP reconciliation is enough to find most synchronization delay problems. Why single stream instead of multiple streams?
-
Avoid uncontrollable delay problems caused by long data flow links for multi-stream reconciliation, resulting in low verification accuracy.
-
The maintenance cost of BCP reconciliation will be greatly reduced, because if multi-stream is used, we need to maintain multiple BCP reconciliations for multi-machine room reconciliation, which relies on more basic components for maintenance.
BCP reconciliation DB writing always triggers ES Get requests, which consumes certain query resources on ES, but Get requests are query methods with very good performance. For example, we have no problem writing within 1000 QPS.
Get request needs to pay attention to a parameter Realtime, which needs to be set to False when requesting, otherwise it will trigger a Refresh operation every time it is requested, which will have an impact on the system writing performance.
mgetReq := EsClient.MultiGet().
Realtime(false)
Minute-level reconciliation
As mentioned in the previous section, the path that cannot be covered by the Business Verification Platform (BCP) reconciliation is DB->DBus, which is the situation where Binlog is cut off. Usually Binlog interruption may have meant a more serious accident, but what we have to do is to do everything possible.
Minute-level reconciliation directly queries DB and ES for reconciliation, without relying on any components. When inconsistencies occur, automatic compensation is performed. On the one hand, minute-level reconciliation makes up for the shortcomings of BCP reconciliation, and the second point is to add a compensation mechanism. The reason why BCP does not compensate is because BCP is mainly for discovering problems, so it needs to remain lightweight and fast. Also, it still relies on basic components such as RocketMQ and DBus. This kind of compensation still cannot cover all abnormal scenarios.
By default, we will consider that the component function is intact for reconciliation every three minutes, but a short delay in a node causes compensation. If compensation alarms occur frequently, we need to further analyze what is the problem with the link? At this time, in our scenario, I will split the link into two and confirm whether there is a problem with RocketMQ's previous link or a problem with RocketMQ and subsequent consumption links. Through the fault analysis diagram, if there is a problem with the link before RocketMQ, such as Binlog interruption, heterogeneous data synchronization platform component hanging, etc., the compensation data will be written directly to RocketMQ and consumed to multiple computer rooms. At this time, the read traffic does not need to be cut off. Stream, and can ensure the consistency of data in multiple computer rooms. But if RocketMQ hangs up, it will directly write to ES. Because at this time we cannot guarantee that multiple computer rooms can be written successfully at the same time, so our decision is to only write to a single computer room and switch all traffic to the single computer room.
RocketMQ hanging up is a very bad signal, and the situation here is more complicated. Because of direct writing to ES, if the write traffic is high, the system loses the current limiting protection at this time, and ES may not be able to withstand it; a single computer room may not be able to withstand all read traffic at the same time; if write conflicts occur frequently, the business write port needs to be downgraded . Therefore, if RocketMQ hangs up, it can be understood that the central system of the write link is paralyzed.
This is the last thing you want to see, so RocketMQ's SLA is the baseline of the business.
T+1 offline reconciliation
Offline reconciliation is to synchronize the data of DB and ES to Hive on a daily basis. The incremental data verifies the final consistency. If inconsistent, compensation is automatically initiated. Offline reconciliation is the bottom line for the data consistency of the synchronization link. The data must be T at the latest. +1 compensation successful.
Summarize
Above we have completed the first phase of construction, disaster recovery deployment, consistency reconciliation, and basic system exception response strategies. At this time, ES can support read and write requests for tens of millions of product indexes. The traffic of a single computer room fluctuates between 500 and 100 QPS, and the write traffic is basically maintained at around 500 QPS.
However, with the development of business, the ES cluster has experienced CPU surges many times, one or more computer rooms are full at the same time, and query delays suddenly increase. However, the read and write traffic does not fluctuate much, or is far less than the system peak. This risk It is attributed to the performance problems that occur in the ES cluster and the usage posture of the business. We will continue to introduce this part to you in the next article on the stability management of ES search engine.
Article Source | ByteDance Business Platform Wang Dan