The current status of Apache Spark in iQiyi
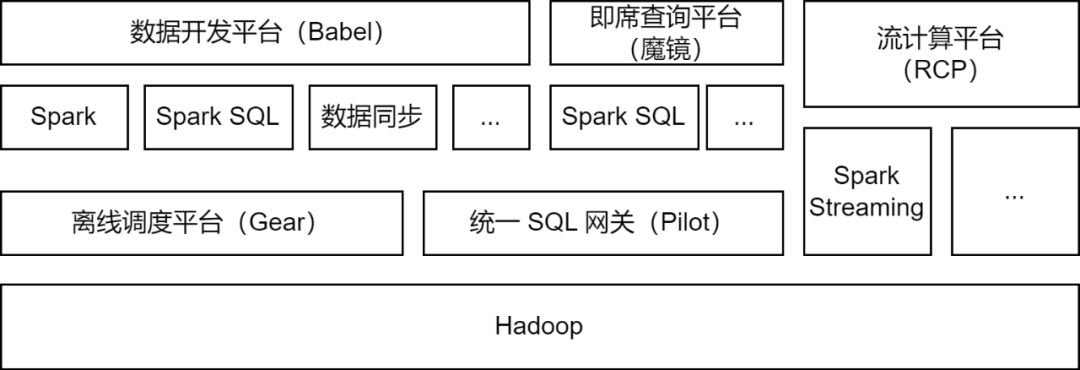
Apache Spark is the offline computing framework mainly used by iQiyi big data platform, and supports some stream computing tasks for data processing, data synchronization, data query analysis and other scenarios:
-
Data processing : The data development platform supports developers to submit Spark Jar package tasks or Spark SQL tasks for ETL processing of data.
-
Data synchronization
: iQIYI's self-developed BabelX data synchronization tool is developed based on the Spark computing framework. It supports data exchange between 15 data sources such as Hive, MySQL, and MongoDB. It supports data synchronization between multiple clusters and multiple clouds, and supports configured Fully managed data sync tasks.
-
Data analysis : Data analysts and operations students submit SQL or configure data indicator queries on the Magic Mirror ad hoc query platform, and call the Spark SQL service through the Pilot unified SQL gateway for query analysis.
Currently, the iQiyi Spark service runs more than 200,000 Spark tasks every day, occupying more than half of the overall big data computing resources.
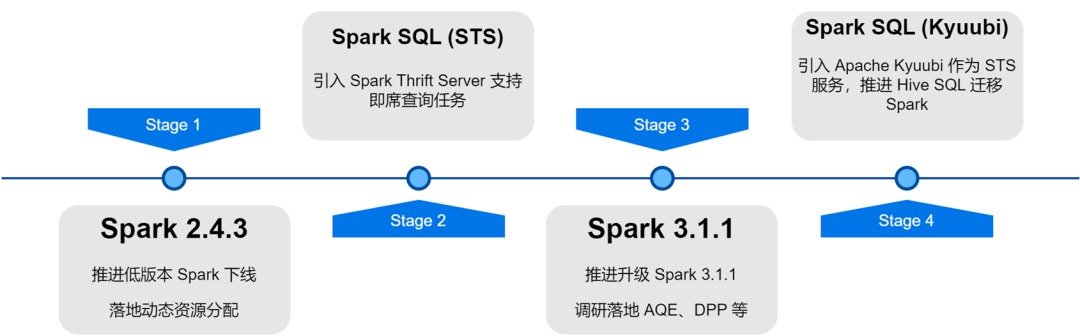
In the process of upgrading and optimizing the iQiyi big data platform architecture, the Spark service has undergone version iteration, service optimization, task SQLization and resource cost management, etc., which has greatly improved the computing efficiency and resource saving of offline tasks.
Spark computing framework application optimization
With the iterative upgrade of the internal Spark version, we have investigated and implemented some excellent features of the new Spark version: dynamic resource allocation, adaptive query optimization, dynamic partition pruning, etc.
-
Dynamic Resource Allocation (DRA)
: There is blindness in user application for resources, and the resource requirements of each stage of Spark tasks are also different. Unreasonable resource allocation leads to a waste of task resources or slow execution. We launched the External Shuffle Service in Spark 2.4.3 and enabled dynamic resource allocation (DRA). After being enabled, Spark will dynamically start or release the Executor based on the resource requirements of the current running stage. After DRA went online, the resource consumption of Spark tasks was reduced by 20%.
-
Adaptive Query Optimization (AQE)
: Adaptive Query Optimization (AQE) is an excellent feature introduced in Spark 3.0. Based on the statistical indicators during the runtime of the pre-stage, it dynamically optimizes the execution plan of the subsequent stages and automatically selects the appropriate Join strategy. Optimize skewed Join, merge small partitions, split large partitions, etc. After upgrading Spark 3.1.1, AQE was turned on by default, which effectively solved problems such as small files and data skew, and greatly improved the computing performance of Spark. The overall performance increased by about 10%.
-
Dynamic partition pruning (DPP)
: In SQL computing engines, predicate pushdown is usually used to reduce the amount of data read from the data source, thereby improving computing efficiency. A new pushdown method is introduced in Spark3: dynamic partition pruning and Runtime Filter. By first calculating the small table of the Join, the large table of the Join is filtered based on the calculation results, thereby reducing the amount of data read by the large table. We conducted research and testing on these two features and turned on DPP by default. In some business scenarios, the performance increased by 33 times. However, we found that in Spark 3.1.1, turning on DPP will cause SQL parsing with many subqueries to be particularly slow. Therefore, we implemented an optimization rule: calculate the number of subqueries, and when it exceeds 5
, turn off DPP
optimization.
In the process of using Spark, we also encountered some problems. By following the latest progress of the community, we discovered and put in some patches to solve them. In addition, we have also made some improvements to Spark ourselves to make it suitable for various application scenarios and enhance the stability of the computing framework.
-
Support concurrent writing
Since Spark 3.1.1 converts Hive Parquet format tables into Spark's built-in Parquet Writer by default, use the InsertIntoHadoopFsRelationCommand operator to write data (spark.sql.hive.convertMetastoreParquet=true). When writing a static partition, the temporary directory will be built directly under the table path. When multiple static partition writing tasks write to different partitions of the same table at the same time, there is a risk of task writing failure or data loss (when a task is committed, the entire temporary directory will be cleaned up, resulting in data loss for other tasks).
We add a forceUseStagingDir parameter to the InsertIntoHadoopFsRelationCommand operator and use the task-specific Staging directory as the temporary directory. In this way, different tasks use different temporary directories, thus solving the problem of concurrent writing. We have submitted the relevant Issue [SPARK-37210] to the community.
-
Support querying subdirectories
After Hive is upgraded to 3.x, the Tez engine is used by default. When the Union statement is executed, the HIVE_UNION_SUBDIR subdirectory will be generated. Because Spark ignores data in subdirectories, no data can be read.
This problem can be solved by falling back Parquet/Orc Reader to Hive Reader, adding the following parameters:

However, using Spark's built-in Parquet Reader will have better performance, so we gave up the plan of falling back to Hive Reader and instead transformed Spark. Since Spark already supports reading subdirectories of non-partitioned tables through the recursiveFileLookup parameter, we have extended this to support reading subdirectories of partitioned tables. For details, see: [SPARK-40600]
-
JDBC data source enhancements
There are a large number of JDBC data source tasks in data synchronization applications. In order to improve operating efficiency and adapt to various application scenarios, we have made the following modifications to Spark's built-in JDBC data source:
Push down of sharding conditions
:
After Spark fragments the JDBC data source, it inserts sharding conditions through subqueries. We found that in MySQL 5.x, the subquery conditions cannot be pushed down, so we added a The placeholder represents the position of the condition, and when inserting the sharding condition in Spark, it is pushed down to the inside of the subquery, thereby realizing the ability to push down the sharding condition.
Multiple writing modes
:
We have implemented multiple writing modes for JDBC data sources in Spark.
-
Normal: Normal mode, use the default INSERT INTO to write
-
Upsert: Update when the primary key exists, written in INSERT INTO...ON DUPLICATE KEY UPDATE mode
-
Ignore: Ignore when the primary key exists, write in INSERT IGNORE INTO mode
Silent mode:
When an exception occurs during JDBC writing, only the exception log is printed and the task is not terminated.
Support Map type
: We use JDBC data source to read and write ClickHouse data. The Map type in ClickHouse is not supported in the JDBC data source, so we added support for the Map type.
-
Local disk write size limit
Operations such as Shuffle, Cache, and Spill in Spark will generate some local files. When too many local files are written, the disk of the computing node may be filled up, thus affecting the stability of the cluster.
In this regard, we added an indicator of disk write volume in Spark, throw an exception when the disk write volume reaches the threshold, and judge the task failure exception in TaskScheduler, and call DagScheduler when the disk write limit exception is captured. The cancelJob method stops tasks with excessive disk usage.
At the same time, we also added the Executor Disk Usage indicator in ExecutorMetric to expose the current disk usage of Spark Executor, making it easier to observe trends and data analysis.
The Spark service takes up a lot of computing resources. We developed an exception management platform to audit and manage computing resources for Spark batch processing tasks and stream computing tasks respectively.
In daily operation and maintenance, we found that a large number of Spark tasks have problems such as memory waste and low CPU utilization. In order to find tasks with these problems, we deliver resource indicators when Spark tasks are running to Prometheus to analyze task resource utilization, and obtain resource configuration and calculation details by parsing Spark EventLog.
By optimizing the resource parameters of tasks and enabling dynamic resource allocation, the computing resource utilization of Spark tasks is effectively improved. The Spark version upgrade also brings a lot of resource savings.
The optimization of resource parameters is divided into memory and CPU optimization. The exception management platform recommends reasonable resource parameter settings based on the peak resource usage of the task in the past seven days, thereby improving the resource utilization of Spark tasks.
Taking memory optimization as an example, users often solve the problem of memory overflow (OOM) by increasing memory, but ignore the in-depth investigation of the causes of OOM. This causes the memory parameters of a large number of Spark tasks to be set too high and the ratio of queue resource memory to CPU to be unbalanced. We obtain Spark Executor memory indicators and send exception work orders to notify users and guide them to properly configure memory parameters and the number of partitions.
After nearly a year of resource audit management, the exception management platform has issued more than 1,600 work orders, saving a total of about 27% of computing resources.
Implementation and optimization of Spark SQL service
The iQiyi Spark SQL service has gone through multiple stages, from Spark's native Thrift Server service to Kyuubi 0.7 to Apache Kyuubi 1.4 version, which has brought great improvements to the service architecture and stability.
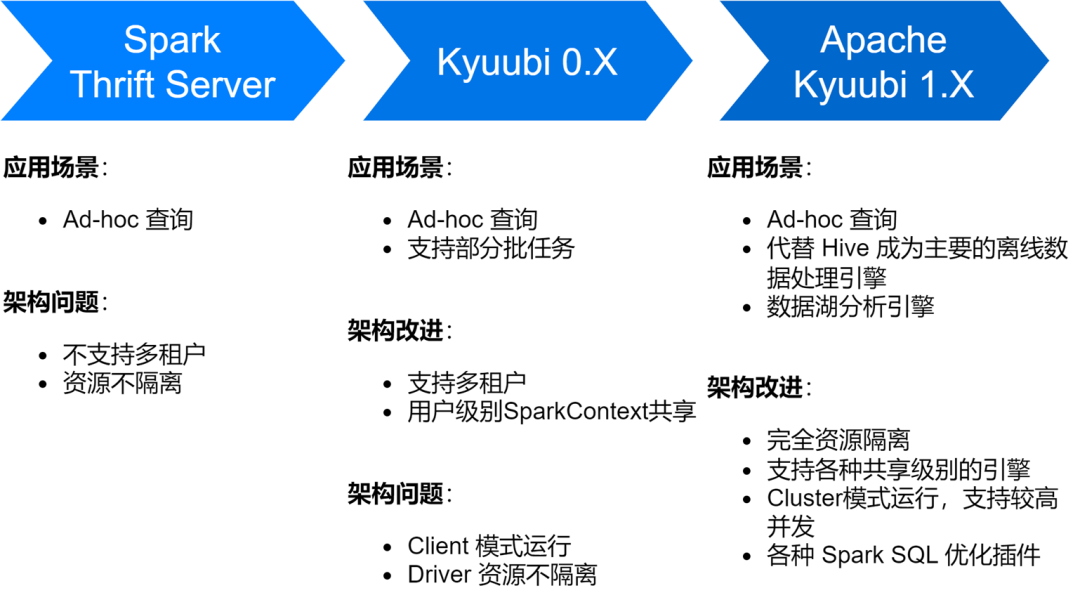
At present, the Spark SQL service has replaced Hive as iQiyi's main offline data processing engine, running an average of about 150,000 SQL tasks every day.
-
Optimize storage and computing efficiency
We also encountered some problems during the exploration of Spark SQL service, mainly including the generation of a large number of small files, larger storage, and slower calculations. For this reason, we have also carried out a series of storage and computing efficiency optimizations.
Enable ZStandard compression to improve compression ratio
Zstd is Meta's open source compression algorithm. Compared with other compression formats, it has a greater compression rate and decompression efficiency. Our actual measurement results show that the compression rate of Zstd is equivalent to Gzip, and the decompression speed is better than Snappy. Therefore, we used Zstd compression format as the default data compression format during the Spark upgrade process, and also set Shuffle data to Zstd compression, which brought great savings to cluster storage. When applied in advertising data scenarios, the compression rate Improved by 3.3 times, saving 76% of storage costs.
Add the Rebalance phase to avoid generating small files
The small file problem is an important issue in Spark SQL: too many small files will put great pressure on the Hadoop NameNode and affect the stability of the cluster. The native Spark computing framework does not have a good automated solution to solve the small file problem. In this regard, we also investigated some industry solutions and finally used the small file optimization solution that comes with the Kyuubi service.
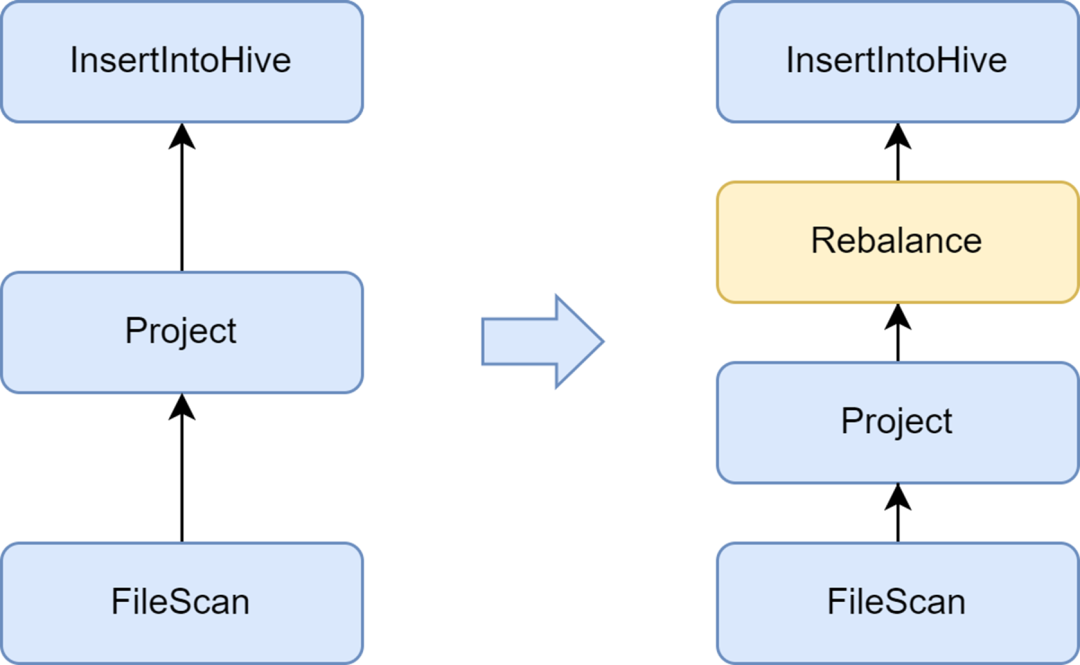
The insertRepartitionBeforeWrite optimizer provided by Kyuubi can insert the Rebalance operator before the Insert operator. Combined with the logic of AQE to automatically merge small partitions and split large partitions, it realizes the control of the output file size and effectively solves the problem of small files.
After enabling it, the average output file size of Spark SQL is optimized from 10 MB to 262 MB, avoiding the generation of a large number of small files.
Enable Repartition sorting inference to further improve compression rate
After turning on small file optimization, we found that the data storage of some tasks became much larger. This is because the Rebalance operation inserted in small file optimization uses partition fields or random partitions for partitioning, and the data is randomly scattered, resulting in a reduction in the encoding efficiency of the file in the Parquet format, which in turn leads to a reduction in the file compression rate.
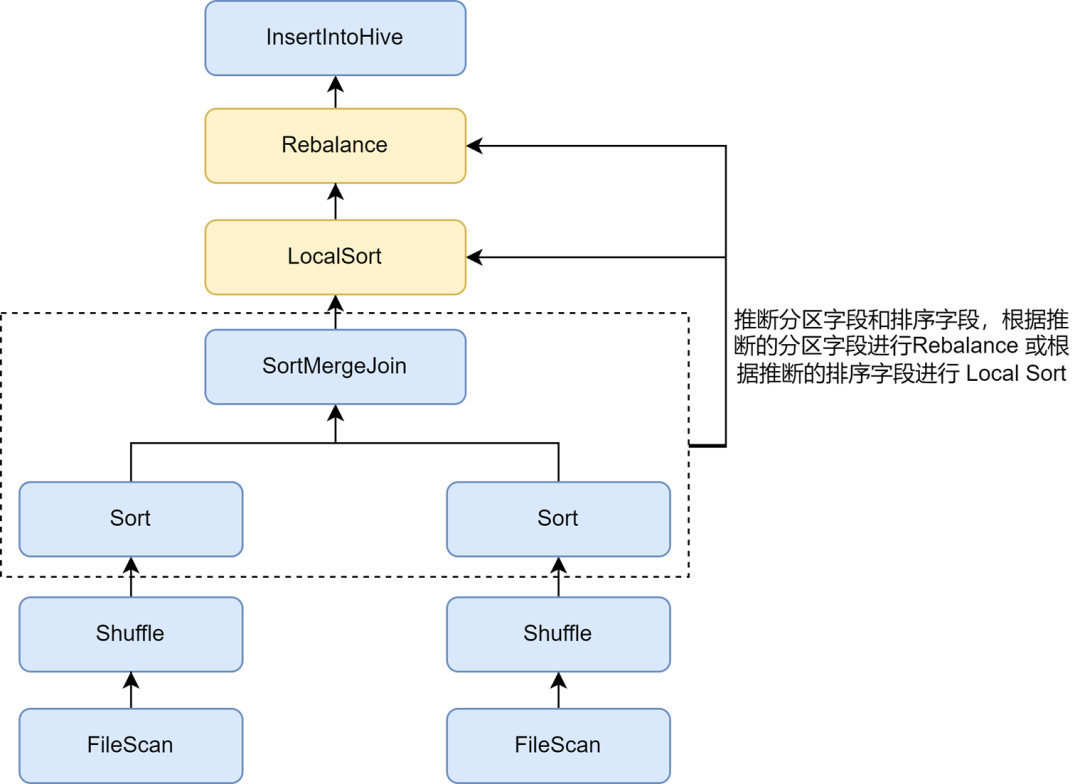
In the rules of Kyuubi small file optimization, automatic inference of partitions and sort fields can be enabled through the spark.sql.optimizer.inferRebalanceAndSortOrders.enabled parameter. For non-dynamic partition writing, operators such as Join, Aggregate, and Sort in the pre-execution plan are used. The partitioning and sorting fields are inferred from the Keys, and the inferred partition fields are used for Rebalance, or the inferred sorting fields are used for Local Sort before Rebalance, so that the data distribution of the finally inserted Rebalance operator is as consistent as possible with the pre-plan and avoids writing The incoming data is randomly scattered, thereby effectively improving the compression rate.
Enable Zorder optimization to improve compression rate and query efficiency
Zorder sorting is a multi-dimensional sorting algorithm. For columnar storage formats such as Parquet, effective sorting algorithms can make the data more compact, thereby improving the data compression rate. In addition, since similar data is gathered in the same storage unit, for example, the statistical range of min/max is smaller, the amount of data skipping during the query process can be increased, effectively improving query efficiency.
Zorder clustering sorting optimization is implemented in Kyuubi. Zorder fields can be configured for tables, and Zorder sorting will be automatically added when writing. For existing tasks, the Optimize command is also supported for Zorder optimization of existing data. We have added Zorder optimization internally to some key businesses, reducing data storage space by 13% and improving data query performance by 15%.
Introduce independent AQE configuration in the final stage to increase computing parallelism
During the process of migrating some Hive tasks to Spark, we found that the execution speed of some tasks actually slowed down. Analysis found that because the Rebalance operator was inserted before writing and combined with Spark AQE to control small files, we changed AQE's spark.sql. The adaptive.advisoryPartitionSizeInBytes configuration is set to 1024M, which causes the parallelism of the intermediate Shuffle phase to become smaller, which in turn makes task execution slower.
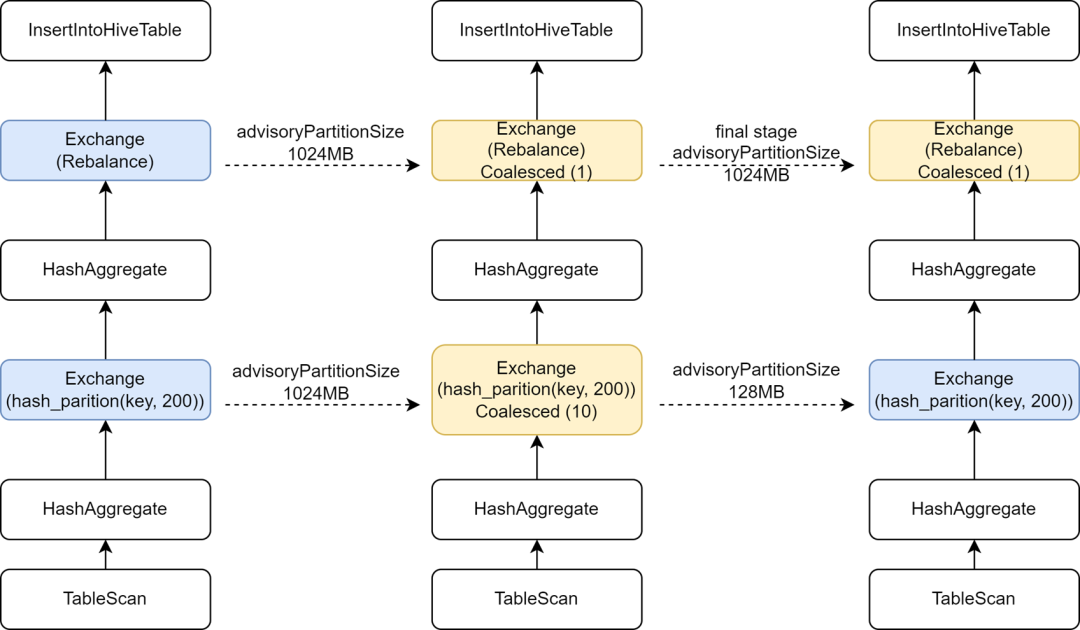
Kyuubi provides optimization of the final stage configuration, allowing to add some configurations separately for the final stage, so that we can add a larger advisoryPartitionSizeInBytes for the final stage of controlling small files, and use a smaller advisoryPartitionSizeInBytes for the previous stages to increase the parallelism of calculations. degree, and reduces disk overflow during the Shuffle stage, effectively improving computing efficiency. After adding this configuration, the overall execution time of Spark SQL tasks is shortened by 25%, and resources are saved by approximately 9%.
Infer dynamic writing of single-partition tasks to avoid excessively large Shuffle partitions
For dynamic partition writing, Kyuubi small file optimization will use the dynamic partition field for rebalance. For tasks that use dynamic partitioning to write to a single partition, all Shuffle data will be written to the same Shuffle partition. iQIYI internally uses Apache Uniffle as the Remote Shuffle Service. Large partitions will cause a single point of pressure on the Shuffle Server, and even trigger current limiting and cause write speed reduction. For this purpose, we developed an optimization rule to capture the written partition filter conditions and infer whether the data of a single partition is written in a dynamic partitioning manner; for such tasks, we no longer use dynamic partition fields for Rebalance, but use random Rebalance , this avoids generating a larger Shuffle partition. For details, see: [KYUUBI-5079].
-
Abnormal SQL detection and interception
When there are problems with data quality or users are unfamiliar with data distribution, it is easy to submit some abnormal SQL, which may lead to serious waste of resources and low computing efficiency. We have added some monitoring indicators to the Spark SQL service, and detected and intercepted some abnormal computing scenarios.
At iQiyi, data analysts submit SQL for Ad-hoc query analysis through the Magic Mirror ad-hoc query platform, which provides users with second-level query capabilities. We use Kyuubi's shared engine as the back-end processing engine to avoid starting a new engine for each query, which wastes startup time and computing resources. The shared engine's permanent presence in the background can bring users a faster interactive experience.
For the shared engine, multiple requests will seize resources from each other. Even if we enable dynamic resource allocation, there are still situations where the resources are occupied by some large queries, causing other queries to be blocked. In this regard, we have implemented the function of intercepting large queries in Kyuubi's Spark plug-in. By parsing operations such as Table Scan in the SQL execution plan, we can count the number of partitions queried and the amount of data scanned. If it exceeds the specified threshold, it will be determined for large queries and intercept execution.
Based on the determination results, the Magic Mirror platform switches large queries to an independent engine for execution. In addition, Magic Mirror defines a minute-level timeout. Tasks that use the shared engine to execute overtime will be canceled and automatically converted to independent engine execution. The entire process is insensitive to users, effectively preventing ordinary queries from being blocked and allowing large queries to continue running using independent resources.
Some operations such as Explode, Join, and Count Distinct in Spark SQL will cause data expansion. If the data expansion is very large, it may cause disk overflow, Full GC or even OOM, and also make the calculation efficiency worse. We can easily see whether data expansion has occurred based on the number of output rows indicators of the preceding and following nodes in the SQL execution plan diagram of the SQL Tab page of the Spark UI.

The indicators in the Spark SQL execution plan graph are reported to the Driver through Task execution events and Executor Heartbeat events, and are aggregated in the Driver.
In order to collect runtime indicators in a more timely manner, we extended the SQLOperationListener in Kyuubi, listened to the SparkListenerSQLExecutionStart event to maintain sparkPlanInfo, and at the same time listened to the SparkListenerExecutorMetricsUpdate event, captured the changes in SQL statistical indicators of the running node, and compared the number of output rows indicators of the current running node. and the number of output rows indicator of the preceding child nodes, calculate the data expansion rate to determine whether serious data expansion occurs, and collect abnormal events or intercept abnormal tasks when data expansion occurs.
The data skew problem is a common problem in Spark SQL and affects performance. Although there are some rules for automatically optimizing data skew in Spark AQE, they are not always effective. In addition, the data skew problem is likely to be caused by the user's misunderstanding of the data. The wrong analysis logic is written because the understanding is not deep enough, or the data itself has data quality problems, so it is necessary for us to analyze the task of data skew and locate the skewed Key value.

We can easily determine whether data skew has occurred in the task through the Stage Tasks statistics in the Spark UI. As shown in the figure above, the Max value of Task's Duration and Shuffle Read exceeds the 75th percentile value, so it is obvious that data skew has occurred.
However, to calculate the Key values that cause skew in the skew task, it is usually necessary to manually split the SQL, and then calculate the distribution of Keys at each stage using Count Group By Keys to determine the skewed Key value. This is usually a relatively time-consuming task. the process of.
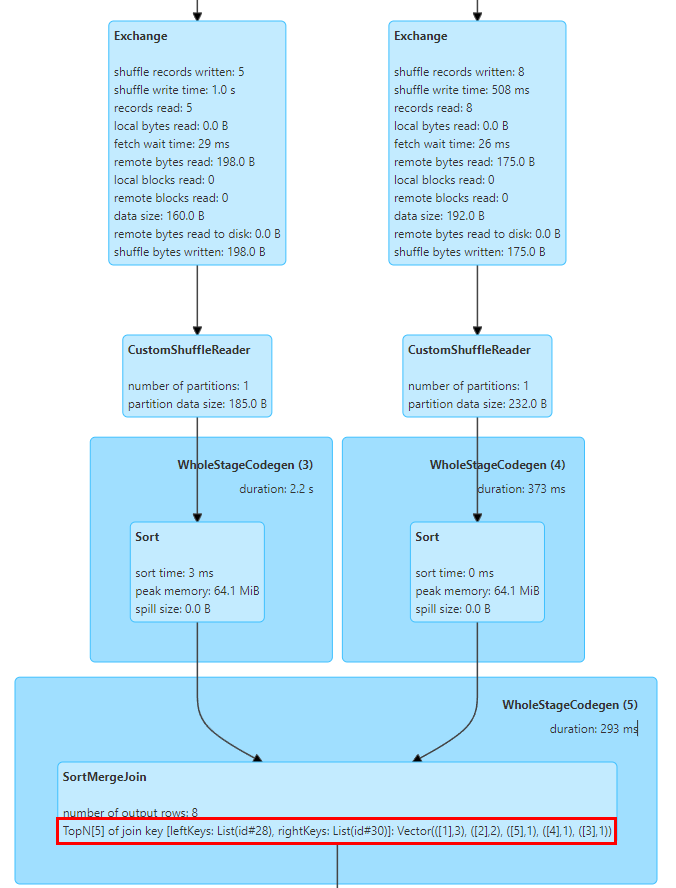
In this regard, we implemented TopN Keys statistics in SortMergeJoinExec.
The implementation of SortMergeJoin is to sort the Key first and then perform the Join operation, so that we can easily count the TopN values of the Key through accumulation.
We implemented a TopNAccumulator accumulator, which internally maintains a Map[String, Long] type object. It uses the Join's Key value as the Map's Key and maintains the Count value of the Key in the Map's Value. In SortMergeJoinExec, for each row of data For cumulative calculation, since the data is in order, we only need to accumulate the inserted Keys, and when inserting new Keys, determine whether the N value is reached and eliminate the smallest Key.
In addition, Spark only supports displaying Long type statistical indicators. We also modified the display logic of SQL statistical indicators to adapt to Map type values.
The above figure shows the Top 5 Join Key values of the two tables for Join, where the key is the id field, and there are 3 rows with id=1.
我们经过一系列的调研测试,发现Spark SQL相较于Hive,在性能和资源使用方面均有显著提升。然而,在将Hive SQL迁移到Spark的过程中,我们也遇到了许多问题。通过对Spark SQL服务进行一些兼容性改造和适配,我们成功地将大部分的Hive SQL任务迁移到Spark。
Spark SQL's support for Hive UDF has some problems in actual use. For example, businesses often use the reflect function to call Java static methods to process data. When an exception occurs in the reflection call, Hive will return a NULL value, and Spark SQL will throw an exception and cause the task to fail. To this end, we modified Spark's reflect function to capture reflection call exceptions and return NULL values, consistent with Hive.
Another problem is that Spark SQL does not support the private constructor of Hive UDAF, which will cause the UDAF of some businesses to fail to be initialized. We have transformed Spark's function registration logic to support Hive UDAF private constructors.
-
Built-in function compatibility
There are differences in the calculation logic of the built-in GROUPING_ID function between Spark SQL and Hive version 1.2, resulting in data inconsistency during the dual-run phase. In Hive 3.1 version, the calculation logic of this function has been changed to be consistent with Spark's logic, so we encourage users to update the SQL logic and adapt the logic of this function in Spark to ensure the correctness of the calculation logic.
In addition, Spark SQL's hash function uses the Murmur3 Hash algorithm, which is different from Hive's implementation logic. We recommend that users manually register Hive's built-in hash function to ensure data consistency before and after migration.
-
Type conversion compatibility
Spark SQL has introduced the ANSI SQL specification since version 3.0. Compared with Hive SQL, it has stricter requirements on type consistency. For example, automatic conversion between String and numeric types is prohibited. In order to avoid automatic conversion anomalies caused by non-standard data type definitions in the business, we recommend that users add CAST to SQL for explicit conversion. For large-scale transformations, the configuration spark.sql.storeAssignmentPolicy=LEGACY can be temporarily added to reduce the type checking of Spark SQL. level to avoid migration exceptions.
The str_to_map function in Hive will automatically retain the last value for repeated Keys, while in Spark, an exception will be thrown and the task will fail. In this regard, we recommend that users audit the quality of upstream data, or add the spark.sql.mapKeyDedupPolicy=LAST_WIN configuration to retain the last duplicate value, consistent with Hive.
-
Other syntax compatibility
The Hint syntax of Spark SQL and Hive SQL are incompatible, and users need to manually delete relevant configurations during migration. Common Hive Hints include broadcasting small tables. Since the Spark AQE function is more intelligent for broadcasting small tables and optimizing task tilting, no additional configuration is usually required by the user.
There are also some compatibility issues between Spark SQL and Hive's DDL statements. We usually recommend that users use the platform to perform DDL operations on Hive tables. For some partition operation commands, such as: deleting non-existing partitions [KYUUBI-1583], unequal Alter Partition statements and other compatibility issues, we have also extended the Spark plug-in for compatibility.
Summary and Outlook
At present, we have migrated most of the Hive tasks in the company to Spark, so Spark has become iQiyi's main offline processing engine. We completed preliminary resource audit and performance optimization work on the Spark engine, which brought considerable savings to the company. In the future, we will continue to optimize the performance and stability of Spark services and computing frameworks. We will also further promote the migration of the very few remaining Hive tasks.
With the implementation of the company's data lake, more and more businesses are migrating to the Iceberg data lake. As Iceberg continues to improve the functions of Spark DataSourceV2, Spark 3.1 can no longer meet some new data lake analysis needs, so we are about to upgrade to Spark 3.4. At the same time, we also conducted research on some new features, such as Runtime Filter, Storage Partitioned Join, etc., hoping to further improve the performance of the Spark computing framework based on business needs.
In addition, in order to promote the process of cloud-native big data computing, we introduced Apache Uniffle, a remote shuffle service (RSS). During use, we found that there are performance problems when combined with Spark AQE, such as BroadcastHashJoin skew optimization [SPARK-44065], the large partition problem mentioned earlier, and how to better perform AQE partition planning. We will continue to work on it in the future. This will lead to more in-depth research and optimization.
Maybe you also want to see

