backgroundintroduce
GPUs are currently widely used in the iQiyi deep learning platform. GPU has hundreds or thousands of processing cores and can execute a large number of instructions in parallel, making it very suitable for deep learning-related calculations. GPUs have been widely used in CV (computer vision) and NLP (natural language processing) models. Compared with CPUs, they can usually complete model training and inference faster and more economically.
The CTR (Click Trough Rate) model is widely used in recommendation, advertising, search and other scenarios to estimate the probability of a user clicking on an advertisement or video. GPUs have been extensively used in the training scenario of the CTR model, which improves the training speed and reduces the required server costs.
But in the inference scenario, when we directly deploy the trained model on the GPU through Tensorflow-serving, we find that the inference effect is not ideal. appears in:
-
Inference latency is high. CTR-type models are usually end-user oriented and are very sensitive to inference latency.
-
The GPU utilization is low and the computing power is not fully utilized.
Cause Analysis
analyzing tool
-
Tensorflow Board, a tool officially provided by tensorflow, can visually view the time consuming at each stage in the calculation flow graph and summarize the total time consuming of the operators.
-
Nsight is a development tool suite provided by NVIDIA for CUDA developers. It can perform relatively low-level tracking, debugging and performance analysis of CUDA programs.
Analysis conclusion
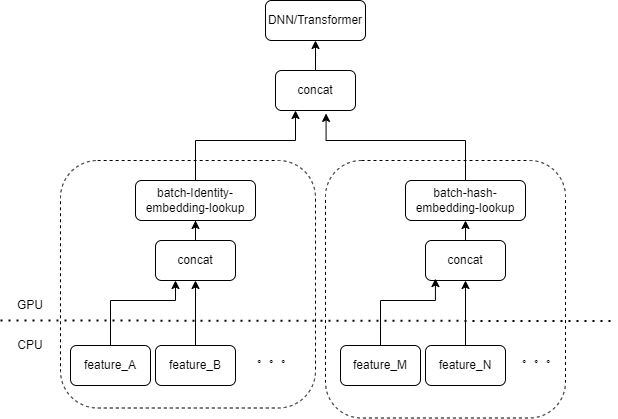
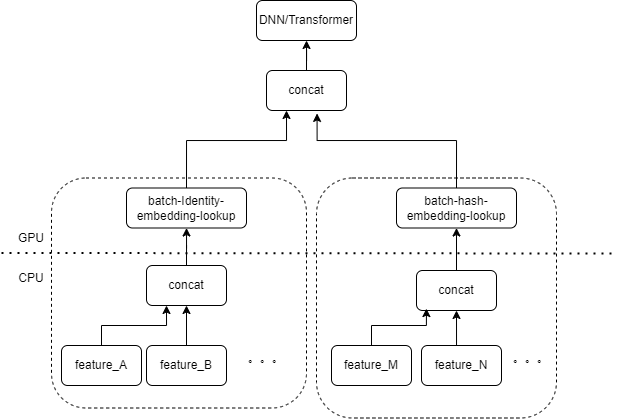
Typical CTR model input contains a large number of sparse features (such as device ID, recently viewed video ID, etc.). Tensorflow's FeatureColumn will process these features. First, identity/hash operations are performed to obtain the index of the embedding table. After embedding lookup and averaging operations, the corresponding embedding tensor is obtained. After splicing the embedding tensors corresponding to multiple features, a new tensor is obtained, and then enters the subsequent DNN/Transformer and other structures.
Therefore, each sparse feature will activate several operators in the input layer of the model. Each operator will correspond to one or several GPU calculations, that is, cuda kernel. Each cuda kernel includes two stages, launch cuda kernel (the overhead necessary to start the kernel) and kernel execution (actually performing matrix calculations on the cuda core). The operator corresponding to the sparse feature identity/hash/embedding lookup has a small amount of calculation, and the launch kernel often takes more time than the kernel execution time. Generally speaking, the CTR model contains dozens to hundreds of sparse features, and theoretically there will be hundreds of launch kernels, which is the current main performance bottleneck.
This problem was not encountered when using GPU to train the CTR model. Because the training itself is an offline task and does not pay attention to delay, the batch size during training can be very large. Although the launch kernel will still be performed multiple times, as long as the number of samples calculated when executing the kernel is large enough, the average time spent on each sample of the launch kernel will be very small. For online inference scenarios, if Tensorflow Serving is required to receive enough inference requests and merge batches before performing calculations, the inference latency will be very high.
Optimization
Our goal is to optimize performance without basically changing the training code or the service framework. We naturally think of two methods, reducing the number of kernels started and improving the speed of kernel startup.
Operator fusion
The basic operation is to merge multiple consecutive operations or operators into a single operator. On the one hand, it can reduce the number of cuda kernel startups. On the other hand, some intermediate results during the calculation process can be stored in registers or shared memory, and only in the calculation At the end of the subsection, the calculation results are written into the global cuda memory.
There are two main methods
-
Automatic fusion based on deep learning compiler
-
Manual operator fusion for business
automatic fusion
We have tried a variety of deep learning compilers, such as TVM/TensorRT/XLA, and actual tests can achieve the fusion of a small number of operators in DNN, such as continuous MatrixMat/ADD/Relu. Since TVM/TensorRT needs to export intermediate formats such as onnx, the online process of the original model needs to be modified. So we use tf.ConfigProto() to enable tensorflow's built-in XLA for fusion.
However, automatic fusion does not have a good fusion effect on operators related to sparse features.
Manual operator fusion
We naturally think that if there are multiple features processed by the same type of FeatureColumn combination in the input layer, then we can implement an operator to splice the input of multiple features into an array as the input of the operator. The output of the operator is a tensor, and the shape of this tensor is consistent with the shape of the tensor obtained by calculating the original features separately and then concatenating them.
Taking the original IdentityCategoricalColumn + EmbeddingColumn combination as an example, we implemented the BatchIdentiyEmbeddingLookup operator to achieve the same calculation logic.
In order to facilitate the use of algorithm students, we have encapsulated a new FusedFeatureLayer to replace the native FeatureLayer; in addition to including the fusion operator, the following logic is also implemented:
-
The fused logic takes effect during inference, and the original logic is used during training.
-
Features need to be sorted to ensure that features of the same type can be arranged together.
-
Since the input of each feature is of variable length, here we generate an additional index array to mark which feature each element of the input array belongs to.
For business, only the original FeatureLayer needs to be replaced to achieve the integration effect.
The launch kernel that was originally tested hundreds of times was reduced to less than 10 times after manual fusion. The overhead of starting the kernel is greatly reduced.
MultiStream improves launch efficiency
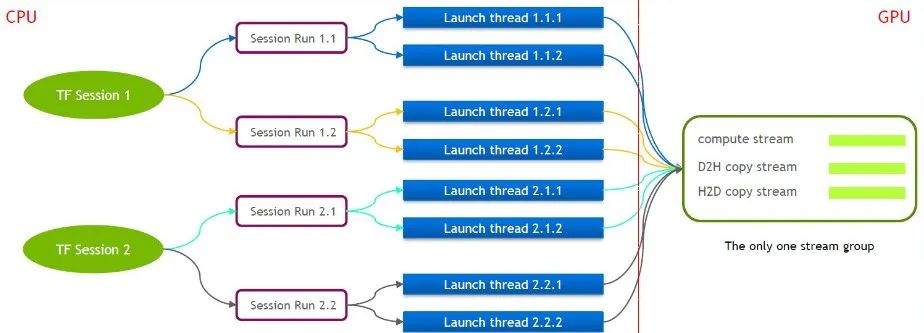
TensorFlow itself is a single-stream model, containing only one Cuda Stream Group (composed of Compute Stream, H2D Stream, D2H Stream and D2D Stream). Multiple kernels can only execute serially on the same Compute Stream, which is inefficient. Even if the cuda kernel is launched through multiple tensorflow sessions, queuing is still required on the GPU side.
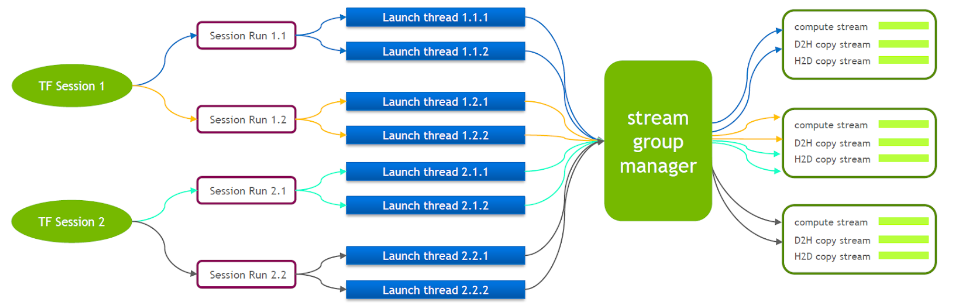
For this reason, NVIDIA's technical team maintains its own branch of Tensorflow to support the simultaneous execution of multiple Stream Groups. This is used to improve the efficiency of launch cuda kernel. We have ported this feature into our Tensorflow Serving.
When Tensorflow Serving is running, Nvidia MPS needs to be turned on to reduce mutual interference between multiple CUDA Contexts.
Small data copy optimization
Based on the previous optimization, we have further optimized the small data copy. After Tensorflow Serving deserializes the values of each feature from the request, it calls cudamemcpy multiple times to copy the data from the host to the device. The number of calls depends on the number of features.
For most CTR services, it is actually measured that when the batchsize is small, it will be more efficient to splice the data on the host side first, and then call cudamemcpy all at once.
Merge batches
In the GPU scenario, batch merging needs to be enabled. By default, Tensorflow Serving does not merge requests. In order to better utilize the parallel computing capabilities of the GPU, more samples can be included in one forward calculation. We turned on the enable_batching option of Tensorflow Serving at runtime to batch merge multiple requests. At the same time, you need to provide a batch config file, focusing on configuring the following parameters. The following are some of our experiences.
-
max_batch_size: The maximum number of requests allowed in a batch, which can be slightly larger.
-
batch_timeout_micros: The maximum time to wait for merging a batch. Even if the number of the batch does not reach max_batch_size, it will be calculated immediately (unit is microseconds). Theoretically, the higher the delay requirement, the smaller the setting here is. It is best to set Under 5 milliseconds.
-
num_batch_threads: Maximum concurrent inference threads. After turning on MPS, it can be set to 1 to 4. Any more will increase the delay.
It should be noted here that most of the sparse features input to the CTR class model are variable-length features. If the client does not make a special agreement, the length of a certain feature may be inconsistent in multiple requests. Tensorflow Serving has a default padding logic, which pads the corresponding features with zeros for shorter requests. For variable-length features, -1 is used to represent null. The default padding of 0 will actually change the meaning of the original request.
For example, the id of the most recently watched video by user A is [3,5], and the id of the most recently watched video by user B is [7,9,10]. If completed by default, the request becomes [[3,5,0], [7,9,10]]. In subsequent processing, the model will think that A has recently watched 3 videos with IDs 3, 5, 0. .
Therefore, we modified the completion logic of Tensorflow Serving response. In this case, the completion logic will be [[3,5,-1], [7,9,10]]. The meaning of the first line is still that videos 3 and 5 were watched.
final effect
After various above-mentioned optimizations, the latency and throughput have met our needs, and it has been implemented in recommended personalized push and waterfall streaming services. The business results are as follows:
-
The throughput is increased by more than 6 times compared to the native Tensorflow GPU container.
-
Latency is basically the same as CPU, meeting business needs
-
When supporting the same QPS, the cost is reduced by more than 40%
Maybe you also want to see
This article is shared from the WeChat public account - iQIYI Technology Product Team (iQIYI-TP).
If there is any infringement, please contact [email protected] for deletion.
This article participates in the " OSC Source Creation Plan ". You who are reading are welcome to join and share together.