1. Install onnxruntime-gpu
The new version of onnxruntime-gpu supports both gpu reasoning and cpu reasoning.
Uninstall the old 1.7.1 cpu version and install the new gpu version:
pip uninstall onnxruntime
pip install onnxruntime-gpuCheck if the installation was successful:
>>> import onnxruntime
>>> onnxruntime.__version__
'1.10.0'
>>> onnxruntime.get_device()
'GPU'
>>> onnxruntime.get_available_providers()
['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider']
2. Modify the reasoning code
Add the providers parameter to the reasoning code to select the reasoning framework. It depends on which one you support, just choose the one you support.
session = onnxruntime.InferenceSession('yolov5s.onnx', None)
# 改为:
session = onnxruntime.InferenceSession('yolov5s.onnx',
providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider'])If Tensorrt and CUDA cannot be inferred when running the reasoning code, as shown below, it means that your own version of ONNX Runtime, TensorRT and CUDA is not corresponding correctly.
2022-08-09 15:38:31.386436528 [W:onnxruntime:Default, onnxruntime_pybind_state.cc:509 CreateExecutionProviderInstance] Failed to create TensorrtExecutionProvider. Please reference https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html#requirements to ensure all dependencies are met.
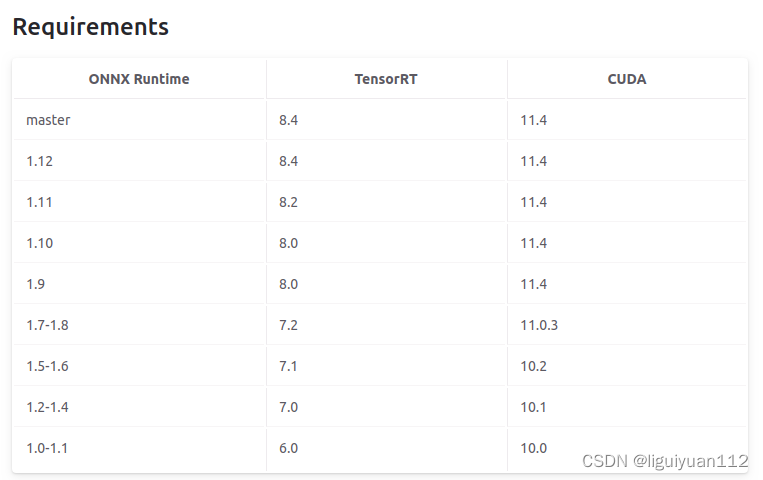
The corresponding versions are as follows: