Let’s talk about AOP?
Aspect-oriented programming is a technology that achieves unified maintenance of program functions through pre-compilation and run-time dynamic agents. It can reduce the writing of the same code in the program, simplify development, and make the interface more focused on business.
Related concepts
Aspect(Aspect): Aspect declaration is similar to class declaration in Java. Aspect will contain some Pointcuts and corresponding Advice.
Joint point(Joint point): Represents a clearly defined point in the program, typically including method invocation, access to class members, execution of exception handling blocks, etc. It can also nest other joint points in itself.
Pointcut(Pointcut): Represents a set of joint points, which are either combined through logical relationships or concentrated through wildcards, regular expressions, etc. It defines where the corresponding advice will occur.
Advice(Enhancement): Advice definesPointcutthe specific operations to be performed at the program points defined in it. It uses before, after and around to distinguish whether the code is executed before, after or instead of each joint point.
How to achieve
1. AspectJ
AspectJ is mainly used for compile-time enhancement, also known as static proxy. When we finish writing an independent business method saveData(), we can use aspectJ to weave the aspect logic into saveData(). For example, logging.
After using aspectJ to compile the code, there will be an extra piece of code in our class file. This code is the aop code added by aspectJ during compilation. This approach of AspectJ can be called a static proxy
At compile time , Aspect weaves the aspect logic we defined in the aspect into the proxy method by adding bytecode (forcibly adding code)
2. JDK dynamic proxy
jdk dynamic proxy uses the reflection mechanism that comes with jdk to complete the dynamic proxy of aop. Using the dynamic proxy that comes with jdk has the following requirements:
1. The proxy class (our business class) needs to implement a unified interface
2. The proxy class must implement the interface in the reflect packageInvocationHandler
3. Dynamically create proxy classes through Proxythe static methods provided by jdknewProxyInstance(xxx)
The proxy class and the proxied class use the same object reference, so we can use our real business class undetected without paying attention to the aspect logic ( independence ) around it,
Tell me about IOC?
loC - Inversion of Control, which is "inversion of control", is a design idea. In Java development, loc means giving the object you designed to the container for control, rather than the traditional internal control of the object. loc is usually implemented by DI. Let's introduce DI below.
DI------Dependency Injection, that is, dependency injection, the dependency between components is determined by the container during runtime, that is, the container dynamically injects a certain dependency into the component. The purpose of dependency injection is to increase the frequency of component reuse and build a flexible and scalable platform for the system.
Core points:
1. The object depends on the IOC/DI container, because the object needs the IOC/DI container to provide the external resources the object needs.
2. When the IOC/DI container injects objects, it injects something that is needed, that is, the resources needed to inject the object.
3. IOC/DI container control objects, mainly control the creation of object instances
Case: Under normal circumstances, if an application wants to use C in A, it will directly create the object of C. In other words, it will actively obtain the required external resource C in class A. This situation is called is positive. The reverse is that class A no longer actively obtains C, but passively waits for the IoC/DI container to obtain an instance of C, and then injects it into class A in reverse.
Tell me about the garbage collection mechanism?
GC's scope of action:
Frequently collected in the new area, rarely collected in the retirement area, and almost never collected in the method area (permanent area/metaspace). Among them, the Java heap is the focus of the garbage collector's work.
Methods to determine survival:
1. Reference counting method
1. The reference counting algorithm (Reference Counting) is relatively simple. It saves an integer reference counter attribute for each object. Used to record when an object is referenced.
2. For an object A, as long as any object references A, the reference counter of A will be incremented by 1; when the reference becomes invalid, the reference counter will be decremented by 1. As long as the value of the reference counter of object A is 0, it means that object A can no longer be used and can be recycled.
There is a serious problem: the inability to handle circular references
2. Reachability analysis algorithm
The basic idea of this algorithm is to use some objects called reference chains (GC Roots) as the starting point, and search downward from these nodes. The path traveled by the search is called (Reference Chain). When an object has no GC Roots, When any reference chain is connected (that is, the node is unreachable from the GC Roots node), it proves that the object is unavailable.
Compared with the reference counting algorithm, the reachability analysis algorithm not only has the characteristics of simple implementation and efficient execution, but more importantly, the algorithm can effectively solve the problem of circular references in the reference counting algorithm and prevent the occurrence of memory leaks.
Garbage removal algorithm
1. Mark-Sweep algorithm (Mark-Sweep)
The marking phase is the phase in which all active objects (reachable objects, reachable) are marked. The cleanup phase is the phase in which unmarked objects, that is, inactive objects, are recycled.
2. Mark copying algorithm (Copying)
Divide the living memory space into two blocks, and only use one of them at a time. During garbage collection, copy the living objects in the memory being used to the unused memory block, and then clear all objects in the memory block being used. Object, swap the roles of two memories, and finally complete garbage collection.
3. Mark compression algorithm (Mark-Compact)
The first phase is the same as the mark-and-sweep algorithm, marking all referenced objects starting from the root node.
The second phase compresses all surviving objects to one end of the memory and arranges them in order. After that, clear all the space outside the boundaries.
Generational strategy
1. Young Gen
1. Characteristics of the young generation: The area is smaller than the old generation, the object life cycle is short, the survival rate is low, and recycling is frequent.
2. In this case, the recycling and sorting speed of the replication algorithm is the fastest. The efficiency of the copy algorithm is only related to the size of the current living object, so it is very suitable for young generation recycling. The problem of low memory utilization of the replication algorithm is alleviated through the design of two survivors in hotspot.
2. Tenured Gen
Characteristics of the old generation: larger area, long object life cycle, high survival rate, and less frequent recycling than the young generation.
In this case, there are a large number of objects with high survival rates, and the replication algorithm obviously becomes inappropriate. It is generally implemented by mark-clear or a mixture of mark-clear and mark-clear-sort.
garbage collector
Collectors used by the new generation collector: Serial, PraNew, Parallel Scavenge
Collectors used by the old generation collector: Serial Old, Parallel Old, CMS
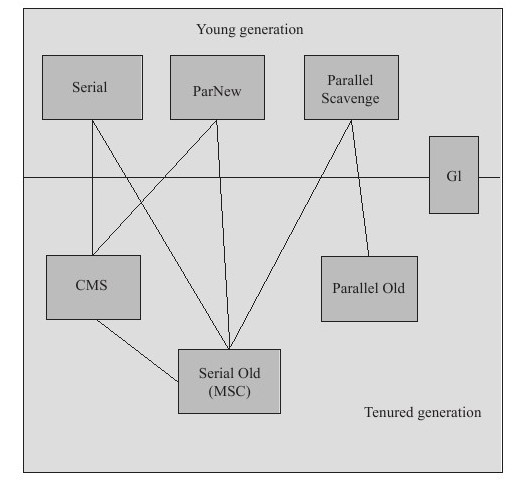
Serial collector (copy algorithm)
The new generation single-threaded collector, marking and cleaning are both single-threaded, and has the advantage of being simple and efficient.
Serial Old Collector (Mark-Collation Algorithm)
The old generation single-threaded collector is the old generation version of the Serial collector.
ParNew Collector (stop-copy algorithm)
The new generation collector can be considered a multi-threaded version of the Serial collector and has better performance than Serial in a multi-core CPU environment.
Parallel Scavenge Collector (stop-copy algorithm)
Parallel multi-threaded collector pursues high throughput and efficiently utilizes the CPU. The throughput is generally 99%, throughput = user thread time/(user thread time + GC thread time). It is suitable for scenarios such as background applications that do not require high interaction response.
Parallel Old Collector (stop-copy algorithm)
The old generation version of the Parallel Scavenge collector, a parallel collector that prioritizes throughput and uses multi-threading.
CMS (Concurrent Mark Sweep) collector (mark-sweep algorithm)
High concurrency, low pauses, pursuing the shortest GC recycling pause time, relatively high CPU usage, fast response time, short pause time, multi-core CPU is the choice to pursue high response time.
Floating garbage cannot be cleaned and debris is easily generated.
The cleaning process is divided into 4 steps, including:
- Initial mark (CMS initial mark)
- Concurrent mark (CMS concurrent mark)
- Remark (CMS remark)
- CMS concurrent sweep
G1 Collector
Parallel and concurrent execution, generational collection, space integration, divided into different regin areas for garbage collection
The operation of the G1 collector can be roughly divided into the following steps:
- Initial Marking
- Concurrent Marking
- Final Marking
- Screening and recycling (Live Data Counting and Evacuation)
Minor GC (new generation GC):
Refers to the garbage collection action that occurs in the new generation. Most Java objects do not survive long, so Minor GC occurs more frequently and the recycling speed is faster. Trigger condition: Triggered when the Eedn area of the new generation is full.
Full GC/Major GC (old generation GC):
Refers to the GC that occurs in the old age. The occurrence of Full GC is often accompanied by at least one Minor GC (not necessarily). The speed of Major GC is generally more than 10 times slower than Minor GC.
Triggering conditions:
System.gc() method call, this method will suggest the JVM to perform Full GC, but the JVM may not accept this suggestion, so it may not be executed.
The old generation space is insufficient, and the memory of the large object created is larger than the old generation space. As a result, the old generation space is insufficient, and Full GC will occur.
The permanent generation space of JDK1.7 and before is full. Before JDK1.7, the method area of the HotSpot virtual machine is required for the permanent generation implementation. Some Class information, constants, static variables and other data will be stored in the permanent generation. Full GC will be triggered when the permanent generation is full and CMS GC is not configured. The removal of the permanent generation in JDK1.8 is also to reduce the frequency of Full GC.
The space allocation guarantee fails. After passing the Minor GC, the average size of the old generation is greater than the available space in the old generation, which triggers the Full GC.
Memory recycling mechanism
Objects are first allocated in the Eden area. When the Eden area does not have enough space to allocate, the virtual machine initiates a Minor GC and places the surviving objects in the From Survivor area (the object age is 1).
When Minor GC occurs again, the Eden area and the From Survivor area will be cleaned together, and the surviving objects will be moved to the To Survivor area (age plus 1).
At this time, the From Survivor area will be exchanged with the To Survivor area, and then the first step will be repeated, but this time the From Survivor area in the first step is actually the To Survivor area in the previous round.
Each time the object is moved, the age of the object will be increased by 1. When the age reaches 15 (the default is 15, the age threshold for the object to be promoted to the old generation can be set through the parameter -XX: MaxTenuringThreshold), it will enter the old generation from the new generation.
Summarize:
1. Objects are allocated in the Eden area first.
2. Large objects directly enter the old generation (large objects refer to Java objects that require a large amount of continuous memory space).
3. Long-term surviving objects enter the old age.
Let’s talk about Bloom filters?
It's actually a long binary vector and a series of random mapping functions. Bloom filters can be used to retrieve whether an element is in a collection.
Bloom filters can tell us "something must not exist or may exist"
Business scene:
Solve the Redis cache penetration problem (interview focus)
Email filtering, using Bloom filter for email blacklist filtering
Filter the crawler URLs, and those that have been crawled will no longer be crawled.
Solve the problem of no longer recommending items that have been recommended by the news (similar to those that have been viewed on Douyin and are no longer available when swiping down)
How to solve cache penetration problem?
Solution 1: Scheduled tasks actively refresh the cache design
First store all the possible queried data in redis, and update the database in redis regularly to ensure that redis will always have data. To request to query only redis
Option 2: Use redis distributed locks
Specific steps:
1. If the cache hits, return the data set directly
2. If there is no cache, try to obtain the distributed lock (with timeout setting). If the lock is not obtained, block the current thread and try to obtain the distributed lock again after n seconds.
3. After getting the lock, check whether the data has been placed in the redis cache by other threads. If the redis cache already exists, directly return the data in redis and release the distributed lock; if the cache has not been refreshed, check the database and query the database. Save the results to the redis cache and return the query results
Option 3: Normally add jvm lock query cache
If the cache hits, return the data set directly.
If the cache does not exist, a JVM lock is attempted,
After other threads block and get the lock, check whether redis has data to prevent other threads from flushing the cache.
If redis already has data, return directly, release the lock, and return to the database to end
If there is no data in redis, query the database, save it in the redis cache, return the data, and release the lock.
for example:
There are s servers and the number of user requests is n; then for requests with the same parameters at the same time, only s queries will be hit to the database at most. The constant s here is equivalent to an O(n) operation time reduction for the database. Arrived O(s)
It can be seen here that the time taken to query the database operation has nothing to do with the growth of n, but is only related to s.
Solution 4, multi-level cache of jvm cache + redis cache
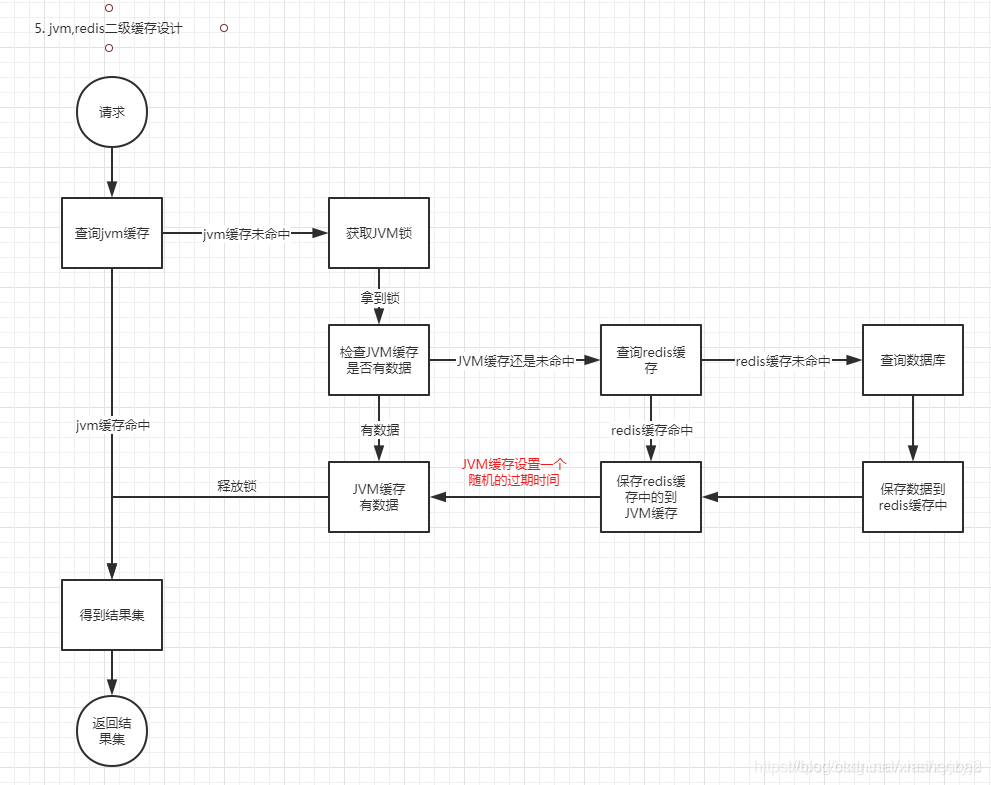
With this design, the server will only query the database when the jvm cache fails and the redis cache also fails. The jvm cache failure time of multiple servers is a random value, so it is largely avoided to check the database when the jvm cache fails at the same time. In this case, since the possibility that all server jvm caches will fail at the same time and the redis cache will also fail is extremely low, there will be very few repeated queries on the database.
How to optimize sql query speed
1. Add index
Columns that are frequently searched can speed up searches;
Create indexes on columns frequently used in WHERE clauses to speed up the judgment of conditions.
Create indexes on columns that often need to be sorted, because the index is already sorted, so that queries can take advantage of the sorting of the index to speed up sorting query time;
Indexes are very effective for medium to large tables, but the maintenance cost of extra-large tables will be very high, so they are not suitable for building indexes.
On columns that are often used in connections, these columns are mainly foreign keys, which can speed up the connection;
Avoid applying functions to segments in the where clause, which will cause the index to fail to be hit.
2. Implementation details
1. The value contained in IN in the SQL statement should not be too many;
2. The SELECT statement must specify the field name without using *;
3. When querying only one piece of data, use limit 1;
4. Avoid performing expression operations on fields in the where clause, as this may cause index failure;
5. For joint indexes, the leftmost prefix rule must be followed to prevent its failure;
6. Try to use inner join so that MySQL will automatically select a small table as the driving table if there are no other filtering conditions;
7. For joint indexes, if there is a range query, such as between, >, < and other conditions, the subsequent index fields will be invalid.
Solution: If the business permits, use >= or <= so that it does not affect the use of the index.;
8. Use or in the where clause to connect conditions. If one of the conditions of the or connection does not have an index, the engine will give up using the index and perform a full table scan.
Solution: Index both sides of the OR connection and you can use it.
9.count optimization speed: count(*)>count(1)>count(field)
10.Specify the index of the query
use index: It is recommended to use the specified index (in the end, mysql needs to decide whether to use this index)
ignore index: ignore this index
force index (index): Force the use of this index