Alibaba back-end internship
Record the interview questions, hope it can help everyone
Class loading process?
Class loading is divided into three parts: loading, connection, and initialization.
load
The main responsibility of class loading is to read the binary byte stream of the .class file into memory (JDK1.7 and before is JVM memory, JDK1.8 and after is local memory), and create a Class object for it in the heap memory. As the access entry for data after the .class enters the memory. Here we only read the binary byte stream. The subsequent verification stage is to use the binary byte stream to verify the .class file. If the verification is passed, the .class file will be converted into a runtime data structure.
connect
Class connection is divided into three stages: verification, preparation, and parsing.
verify:
This stage is mainly to ensure that the loaded byte stream complies with the JVM specifications and does not pose security issues to the JVM.
There are verification of metadata, such as checking whether a class inherits a class modified by final; there is also verification of symbol references, such as verifying whether the symbol reference can be found through the fully qualified name, or checking the permissions of the symbol reference (private , public) whether it meets the grammatical requirements, etc.
Prepare:
The main task in the preparation phase is to open up space for the class variables of the class and assign default values.
- Static variables are basic types (int, long, short, char, byte, boolean, float, double) with a default value of 0
- Static variables are reference types, and the default value is null
- The default value of a static constant is the value set when it is declared. For example: public static final int i = 3; In the preparation phase, the value of i is 3
Analysis:
The main responsibility of this stage is to convert the symbolic reference of Class in the constant pool into a direct reference. This is for static methods and properties and private methods and properties, because such methods and private methods cannot be overridden. Static attributes are not polymorphic at runtime, that is, the compiler can know that they are immutable at runtime, so they are suitable for analysis at this stage. For example, the class method main is replaced with a direct reference, which is a static connection, which is different from the dynamic at runtime. connect
initialization
At this stage, class variable values are initialized. There are two ways to initialize:
1. When declaring a class variable, directly assign a value to the variable.
2. Assign values to class variables in the static initialization block
Java's IO model?
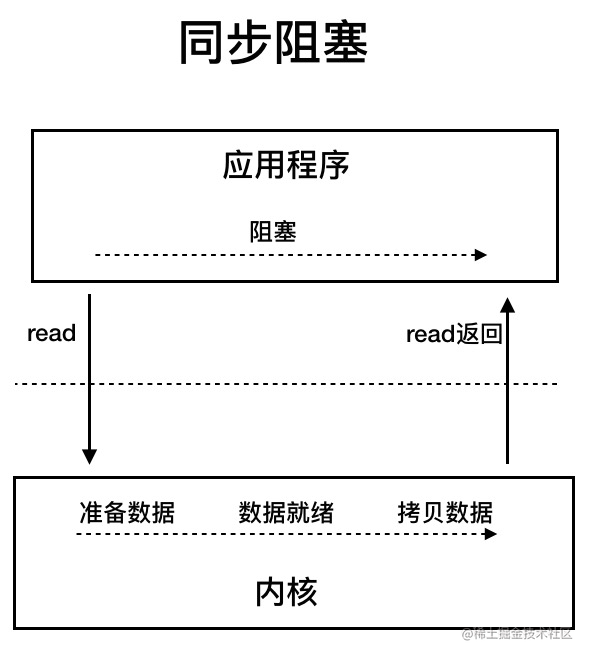
BIO (Blocking I/O)
BIO belongs to the synchronous blocking IO model .
In the synchronous blocking IO model, after the application initiates a read call, it will block until the kernel copies the data to user space.
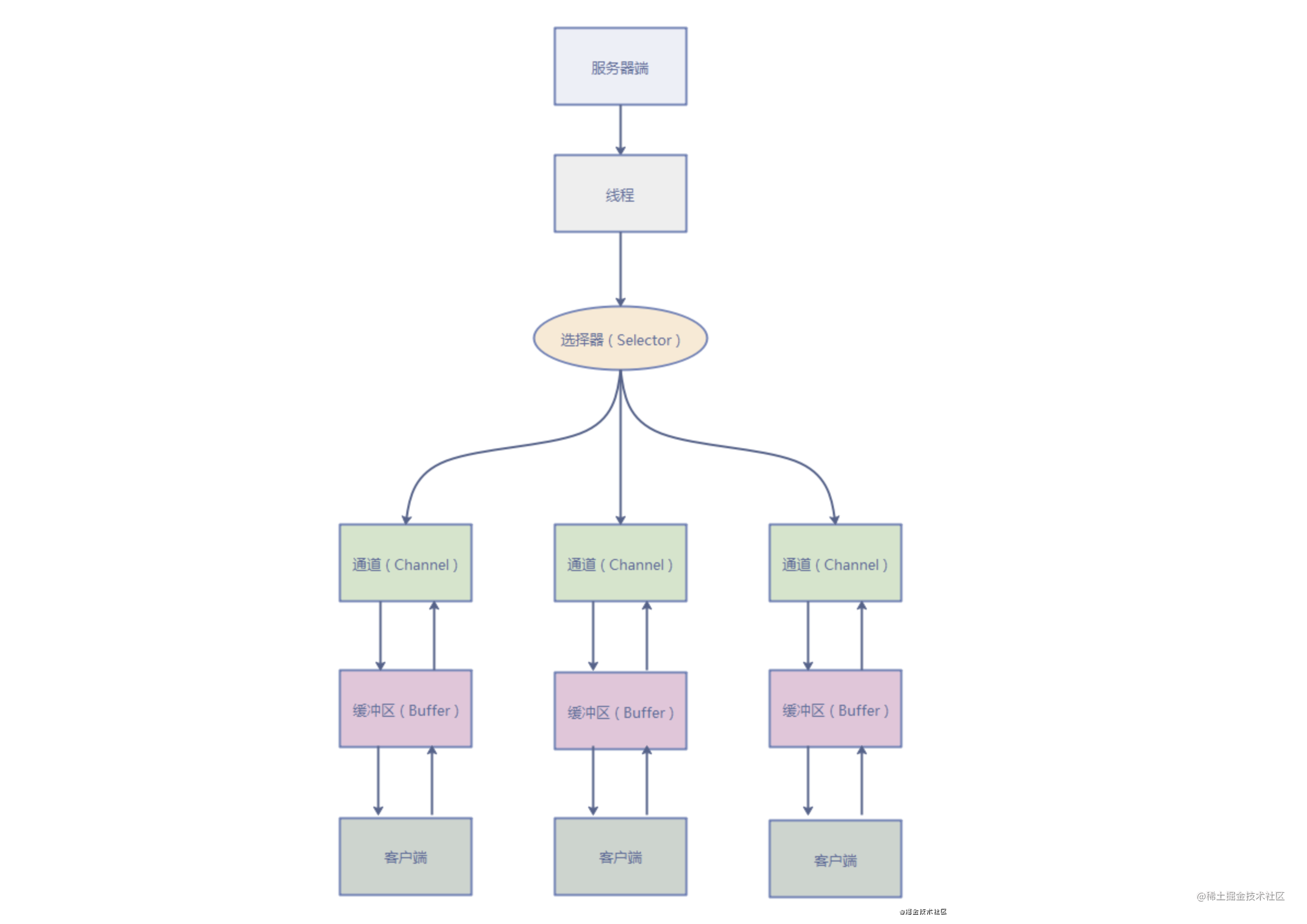
NIO (Non-blocking/New I/O)
NIO in Java was introduced in Java 1.4. It corresponds to java.niothe package and provides abstractions such as Channel, Selector, Bufferand so on. The N in NIO can be understood as Non-blocking, not simply New. It supports buffer-oriented, channel-based I/O operation methods. For high-load, high-concurrency (network) applications, NIO should be used.
The core of the Java NIO system lies in: Channel and Buffer. A channel represents an open connection to an IO device (eg file, socket). If you need to use the NIO system, you need to obtain the channel used to connect the IO device and the buffer used to accommodate the data. Then operate the buffer and process the data. In short, Channel is responsible for transmission and Buffer is responsible for storage.
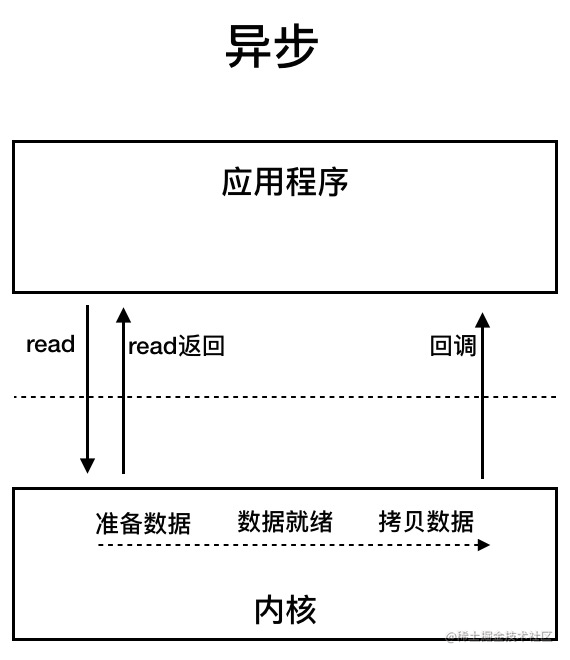
AIO (Asynchronous I/O)
AIO is NIO 2. Java 7 introduced an improved version of NIO, NIO 2, which is an asynchronous IO model.
Asynchronous IO adopts the "subscribe-publish" model: that is, the application registers the IO listener with the operating system and then continues to do its own thing. When an IO event occurs in the operating system and the data is ready, it actively notifies the application and triggers the corresponding function.
Design patterns, such as singleton pattern?
definition:
Singleton Pattern is one of the simplest design patterns in Java. This type of design pattern is a creational pattern, which provides an optimal way to create objects.
This pattern involves a single class that is responsible for creating its own objects while ensuring that only a single object is created. This class provides a way to access its unique objects directly, without the need to instantiate an object of the class.
- 1. A singleton class can only have one instance.
- 2. A singleton class must create its own unique instance.
- 3. The singleton class must provide this instance to all other objects
Case:
In computer systems, thread pools, caches, log objects, dialog boxes, printers, and graphics card driver objects are often designed as singletons. These applications all have more or less the functionality of resource managers. Each computer can have several printers, but there can only be one Printer Spooler to prevent two print jobs from being output to the printer at the same time.
Windows is multi-process and multi-threaded. When operating a file, it is inevitable that multiple processes or threads will operate a file at the same time. Therefore, all file processing must be performed through a unique instance.
Lazy style (thread unsafe):
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
Lazy style (thread safety):
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
Hungry Chinese style:
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}
Double check lock/double verification mode:
For thread-safe lazy style, the scope of our lock is the entire function block, but in fact we only need to create the object once in getSingleton, and we can reduce the granularity of the lock to achieve high availability.
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) { //Threads 1 and 2 arrive at the same time, both are judged by (instance == null).
// Thread 1 enters the following synchronization block, and thread 2 is blocked
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
If the volatile keyword is not used, the hidden danger comes from a line commented with erro in the code. This line of code roughly has the following three steps:
if (instance == null) {
instance = new Singleton();//erro
}
- Allocate the space required for the object in the heap and allocate the address
- Initialize according to the initialization sequence of class loading
- Return the memory address to the reference variable on the stack
Since the Java memory model allows "unordered writing", some compilers may reorder steps 2 and 3 in the above steps for performance reasons, and the order becomes
- Allocate the space required for the object in the heap and allocate the address
- Return the memory address to the reference variable on the stack (the variable is no longer null at this time, but the variable has not been initialized)
- Initialize according to the initialization sequence of class loading
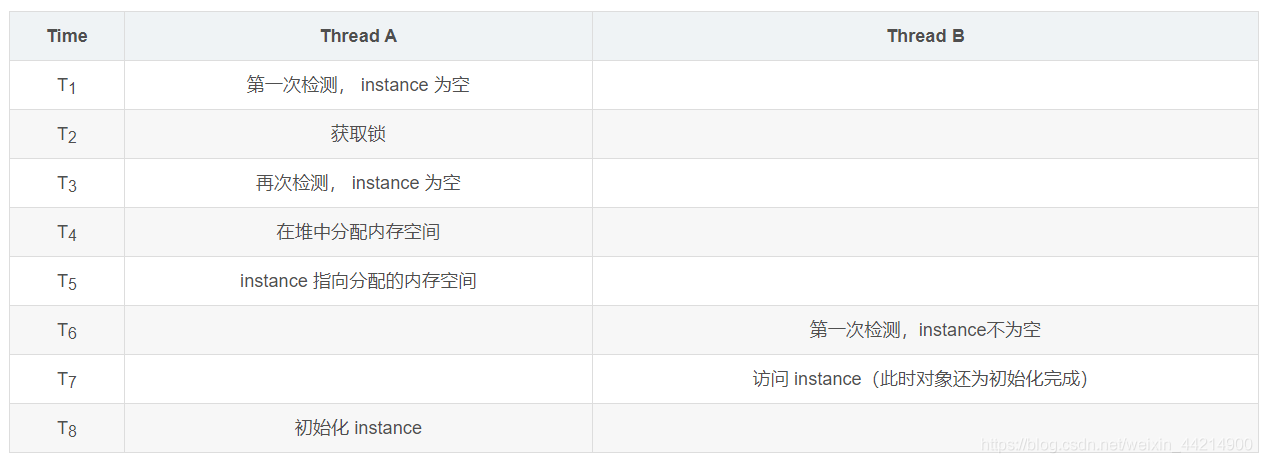
As can be seen from the above figure, thread B returned an uninitialized success case. Voltail is used to avoid this situation, which is equivalent to adding a memory barrier (meaning that subsequent instructions cannot be reordered during reordering). sorted to the position before the memory barrier).
What are the components of jvm?
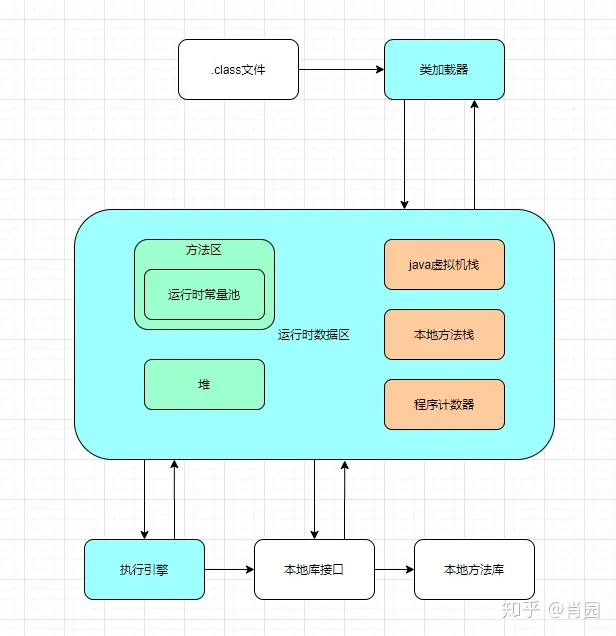
As shown in the blue fill in the figure, the JVM can be divided into 3 parts: class loader, runtime data area and execution engine.
The class loader is responsible for loading bytecode files, that is, java compiled .class files.
The runtime data area is responsible for storing .class files and allocating memory. The runtime data area is divided into 5 parts:
- Method area: Responsible for storing .class files. There is an area in the method area that is a runtime constant pool, which is used to store program constants.
- Heap: The memory space allocated to objects (instances).
The method area and heap are memory spaces shared by all threads.
- Java virtual machine stack: A memory space exclusive to each thread. When each method is executed, the Java virtual machine will synchronously create a stack frame to store local variable tables, operand stacks, dynamic connections, method exits and other information.
- Local method stack: The memory space exclusive to local native methods serves the local methods used by the virtual machine.
- Program counter: records the execution position of the thread to facilitate execution again after thread switching.
The Java virtual machine stack, local method stack, and program counter are exclusive to each thread.
What is the content of the Java heap?
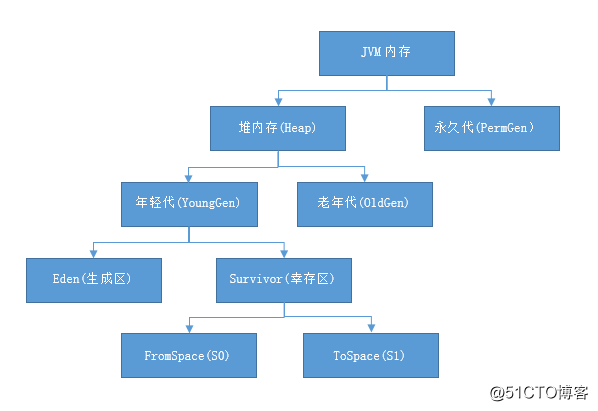
- JVM memory is divided into heap memory and non-heap memory. Heap memory is divided into Young Generation and Old Generation. Non-heap memory is a permanent generation (Permanent Generation).
- The young generation is divided into Eden and Survivor areas. The Survivor area consists of FromSpace and ToSpace. The Eden area occupies the large capacity, and the Survivor area occupies the small capacity. The default ratio is 8:1:1.
- Purpose of heap memory: It stores objects. The garbage collector collects these objects and then recycles them according to the GC algorithm.
- Non-heap memory usage: The permanent generation, also called the method area, stores long-term objects that survive when the program is running, such as class metadata, methods, constants, attributes, etc.
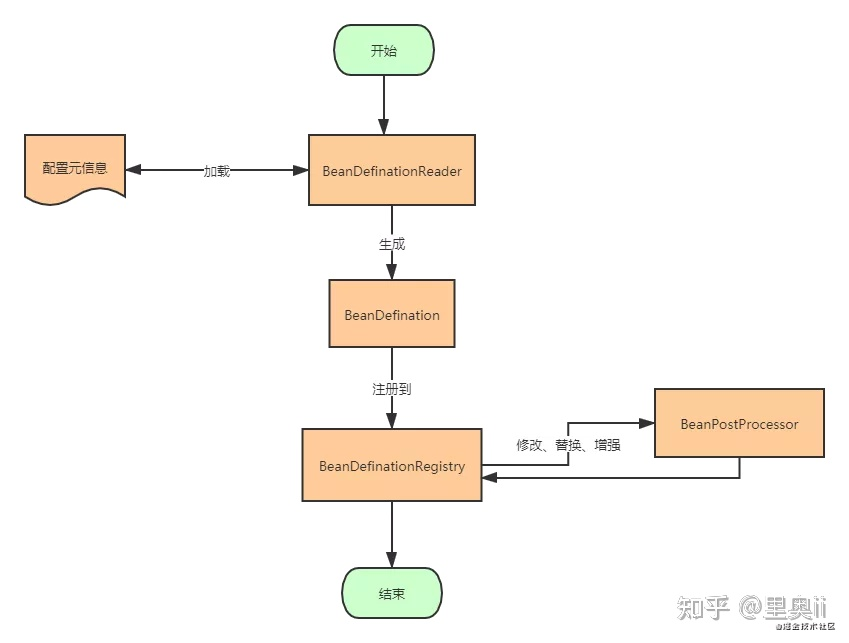
Bean creation process?
Container startup phase
Configuration metainformation, BeanDefinationReader loads the configuration metainformation and converts it into a BeanDefinition in the form of memory, and then registers it to
In BeanDefinationRegistry, BeanDefinationRegistry is a large basket that stores BeanDefination. It is also a form of key-value pairs that are mapped to the corresponding BeanDefination through the id of a specific Bean definition.
BeanFactoryPostProcessor is an extension point provided by Spring during the container startup phase. It is mainly responsible for modifying and replacing each BeanDefination registered in BeanDefinationRegistry to a certain extent.
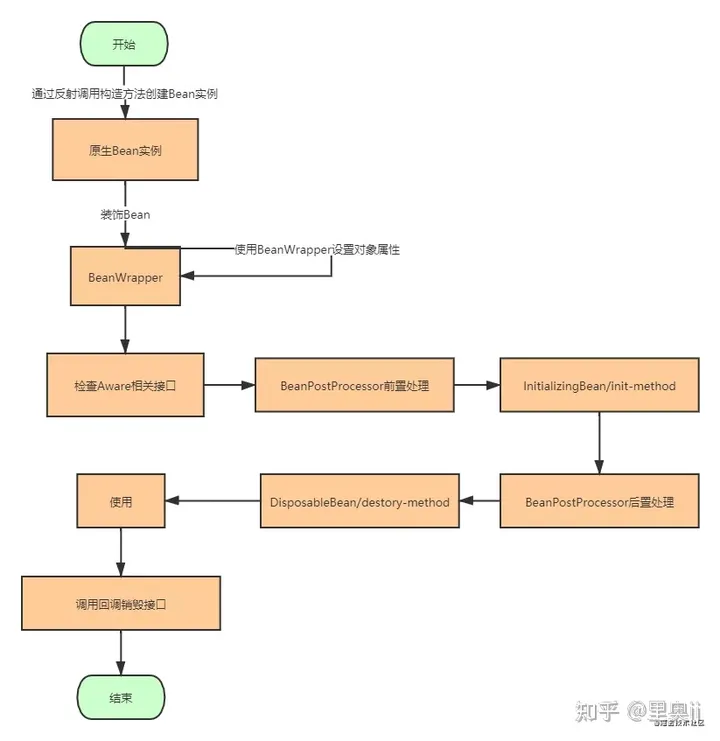
Bean instantiation phase
Use reflection to create objects, decorate beans and generate beanWrapper to encapsulate the reflection interface API
If you want to rely on related objects in Spring and use Spring's related APIs, you must implement the corresponding Aware interface. The Spring IOC container will automatically inject related dependent object instances for us, so we need to check the Aware related interfaces.
BeanPostProcessor pre-processing allows our programmers to modify and replace the Bean instance to a certain extent before placing it in the container.
Configure init-method parameters to customize initialization logic through InitializingBean
BeanPostProcess post-processing
This step corresponds to custom initialization logic, and there are two ways:
- Implement the DisposableBean interface
- Configure destroy-method parameters
use
Call the callback to destroy the interface
Let’s talk about the crawler process
1. Initiate a request:
Initiate a request to the target site through the HTTP library, that is, send a Request. The request can contain additional headers, data and other information, and then wait for the server to respond. The process of this request is like opening the browser, entering the URL: www.baidu.com in the browser address bar, and then clicking Enter. This process is actually equivalent to the browser acting as a browsing client and sending a request to the server.
2. Get the response content:
If the server can respond normally, we will get a Response. The content of the Response is the content to be obtained. The type may include HTML, Json string, binary data (pictures, videos, etc.) and other types. This process is that the server receives the client's request and parses the web page HTML file sent to the browser.
3. Parse the content:
The obtained content may be HTML, which can be parsed using regular expressions and web page parsing libraries. It may also be Json, which can be directly converted to Json object parsing. It may be binary data that can be saved or further processed. This step is equivalent to the browser getting the server-side file locally, interpreting it and displaying it.
4. Save data:
The saving method can be to save the data as text, save the data to a database, or save it as a specific jpg, mp4 and other format files. This is equivalent to downloading pictures or videos on the webpage when we browse the web.