1. Main questions:
The server recently crashed, which involved re-building the deep learning environment. The current pytorch version has been updated to 2.0 or above. I used to use 1.9. After the installation was completed, I encountered this problem and could not train the model.
Error message:
1.
Could not load library libcudnn_cnn_train.so.8. Error: /data/Anaconda3/envs/torch2.1/bin/…/lib/libcudnn_cnn_train.so.8: symbol _ZN5cudnn3cnn34layerNormFwd_execute_internal_implERKNS_7backend11VariantPackEP11CUstream_stRNS0_18 LayerNormFwdParamsERNS1_12OperationSetERP12cudnnContextmb, version libcudnn_cnn_infer.so.8 not defined in file libcudnn_cnn_infer.so.8 with link time reference
: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
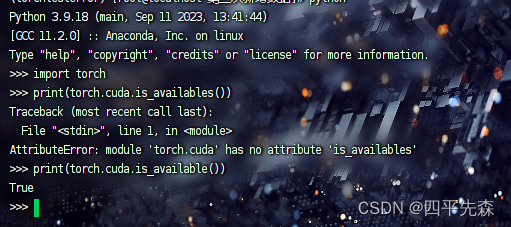
When encountering this problem, most of us use the nvidia-smi and nvcc -V commands. The results are correct at first glance. Then we go to the environment and enter python to print whether torch and gpu are available in torch.cuda. is_available(), it turned out that they were all correct, and the result was True, I was confused.
2. Version Notes
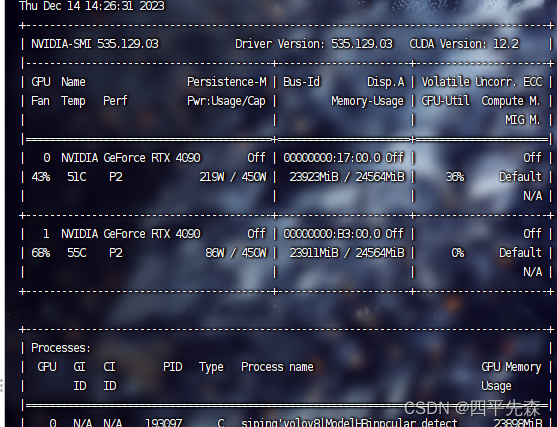
Graphics card model: RTX4090
cuda version: 11.8
cudnn version: 8.9.0
driver version: 535.129.03
For different graphics cards and specific installation configurations, refer to the nvidia official website. Note that the version corresponds.
3. Cause of the problem
After installing anaconda, create a virtual environment and use pip install torch to install the torch version. During the installation process, the torch version prompted is 2.1, and subsequently a lot of things with nvidia-cudnn are installed. This thing It can be understood as cudnn adapted according to the current torch version. These libraries with cuda and cudnn drivers are installed by default in 2.0 and above.

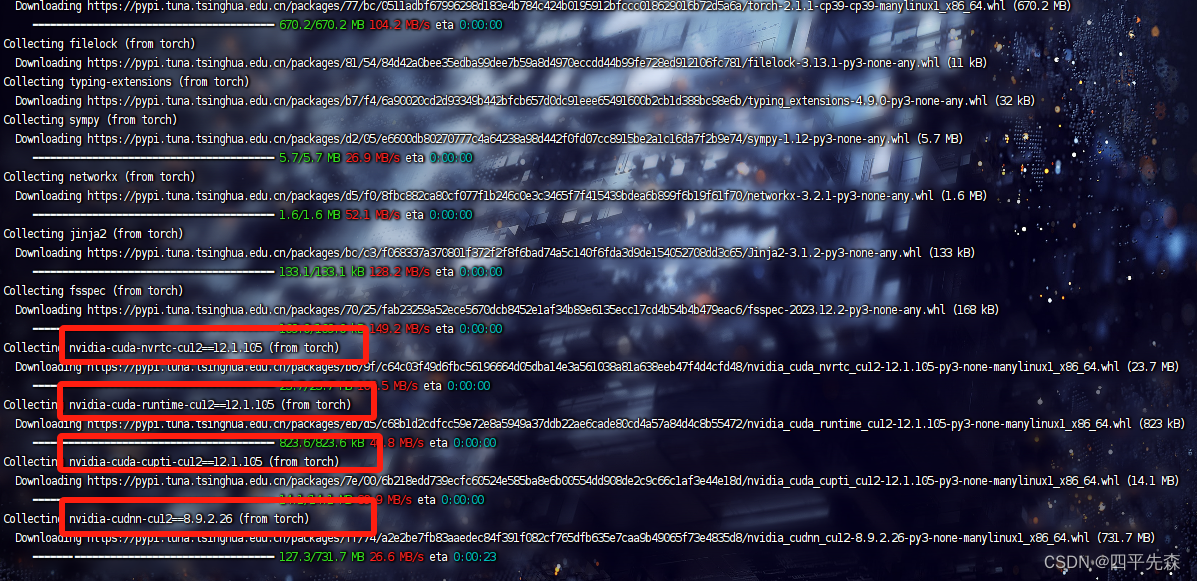
You need to pay attention here. In fact, we usually go to the official website to download cuda and cudnn. For example, I cuda11.8 and cudnn8.9.0 have been configured, and the environment variables have been configured, but torch 2.0 and above seems to have been omitted for us. When installing torch, cudnn was downloaded again in the virtual environment, resulting in external configuration Good cudnn conflicts, and versions below torch2.0 will not download these nvidia libraries, and you can train normally after the installation below 2.0 is completed.
4.Solution
Three solutions are given:
(1) Do not configure cuda and cudnn externally, that is, no longer configure environment variables . This is slightly uncomfortable, and every time you create a new environment, you need to reinstall it in a new environment, which is very redundant. , not very recommended;
(2) Download versions below torch 2.0 and directly use pip install torch==1.9.0, which is the fastest, and not all codes require versions above 2.0. Use this according to your own situation. , if you have downloaded 2.1, you need to uninstall 2.1 and also need to uninstall all the cudnn libraries that come with 2.1 . It is best to find these libraries under the lib of the virtual environment and delete them! If you are afraid that the deletion will not be clean, delete the environment directly and create a clean environment before doing it. Otherwise, even if 1.9 is installed, an error will still be reported. This has been tested.
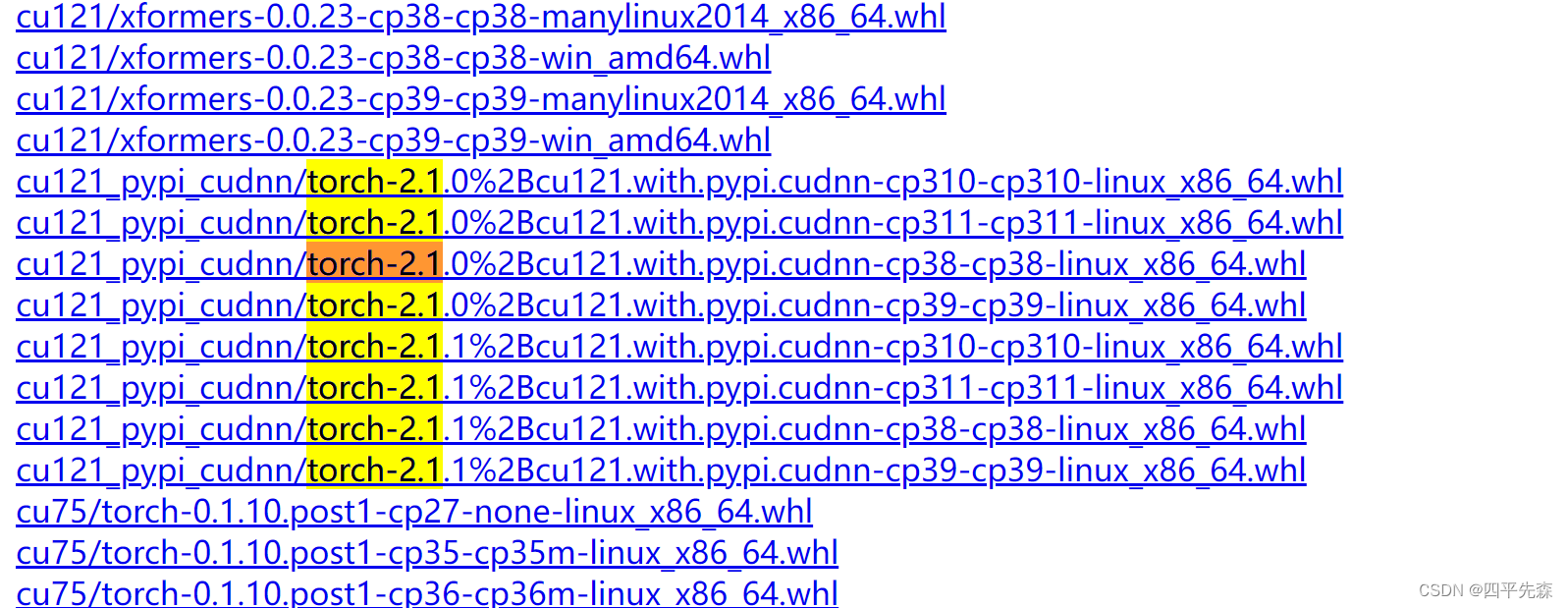
(3) If you insist on torch version 2.0 or above, go to this address to download the whl of torch without nvidia library version . The difference is that the names are different and it is easy to find:

the cudnn version with nvidia is like this, followed by cudnn Name, don't download it wrong:
After downloading it manually, just use pip install *.whl to install it, and then download torchvision and torchaudio at this address. Both of them are very small. It is best to download them together. pip install is also Yes, but it is not easy to adapt the version. The adaptation version given is as follows:
torch corresponding to torchaudio:
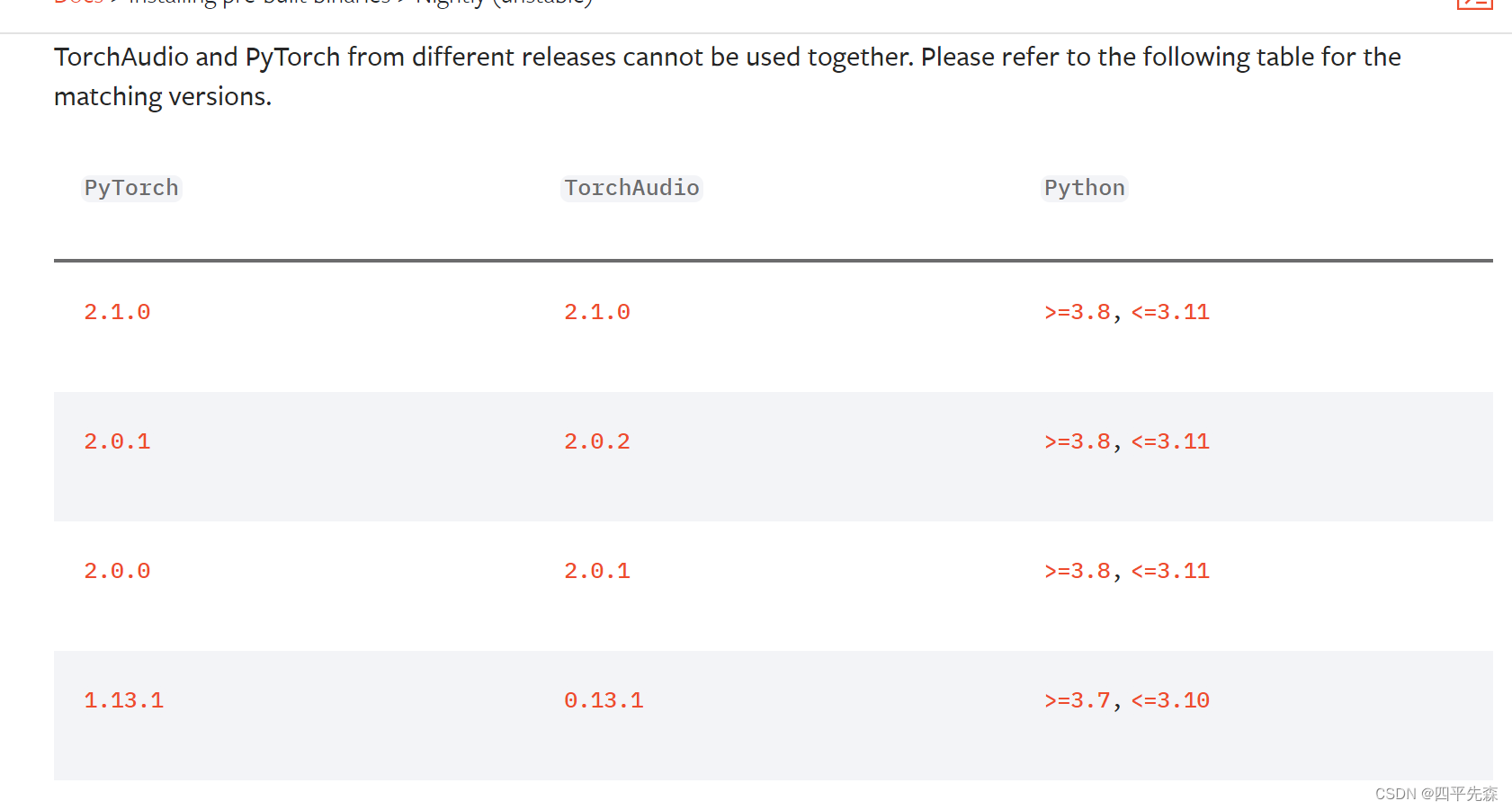
torch corresponding to torchvision:
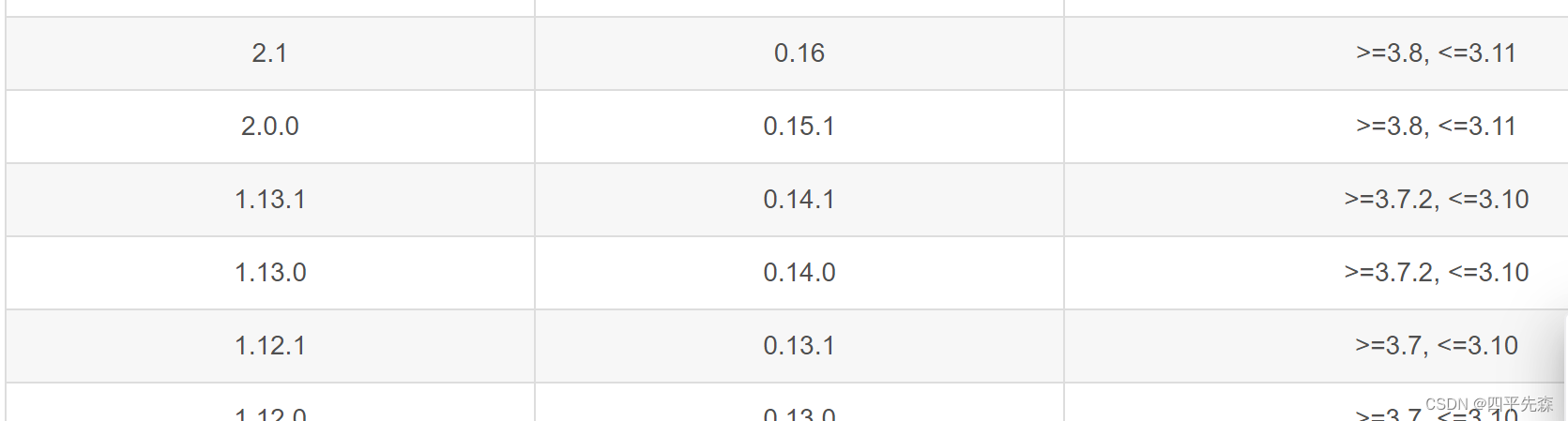
If the version does not correspond, other errors will be reported:
RuntimeError: Couldn't load custom C++ ops. This can happen if your PyTorch and torchvision versions are incompatible, or if you had errors while compiling torchvision from source. For further information on the compatible versions, check https://github.com/pytorch/vision#installation for the compatibility matrix. Please check your PyTorch version with torch.__version__ and your torchvision version with torchvision.__version__ and verify if they are compatible, and if not
please reinstall torchvision so that it matches your PyTorch install.
RuntimeError: GET was unable to find an engine to execute this computation
These are the same problems. One is that torch 2.0 and above do not correspond to other versions of torch libraries, and there are other environmental error problems that are not saved in time. You can comment and work together.
5.Reference
[1] https://blog.csdn.net/shiwanghualuo/article/details/122860521
[2] https://pytorch.org/audio/main/installation.html
[3] https://blog.csdn.net/wangmou211/article/details/134595135