After the rise of Internet business, with the characteristics of massive users and massive data, a single database server can no longer meet business needs, and database clusters must be considered to improve performance. 第一种方式是“读写分离”,第二种方式是“数据库分片” for high-performance database clusters.
1. Read-write separation architecture
**Principle of read-write separation:** The basic principle of read-write separation is to disperse database read and write operations to different nodes. The following is its basic architecture diagram:
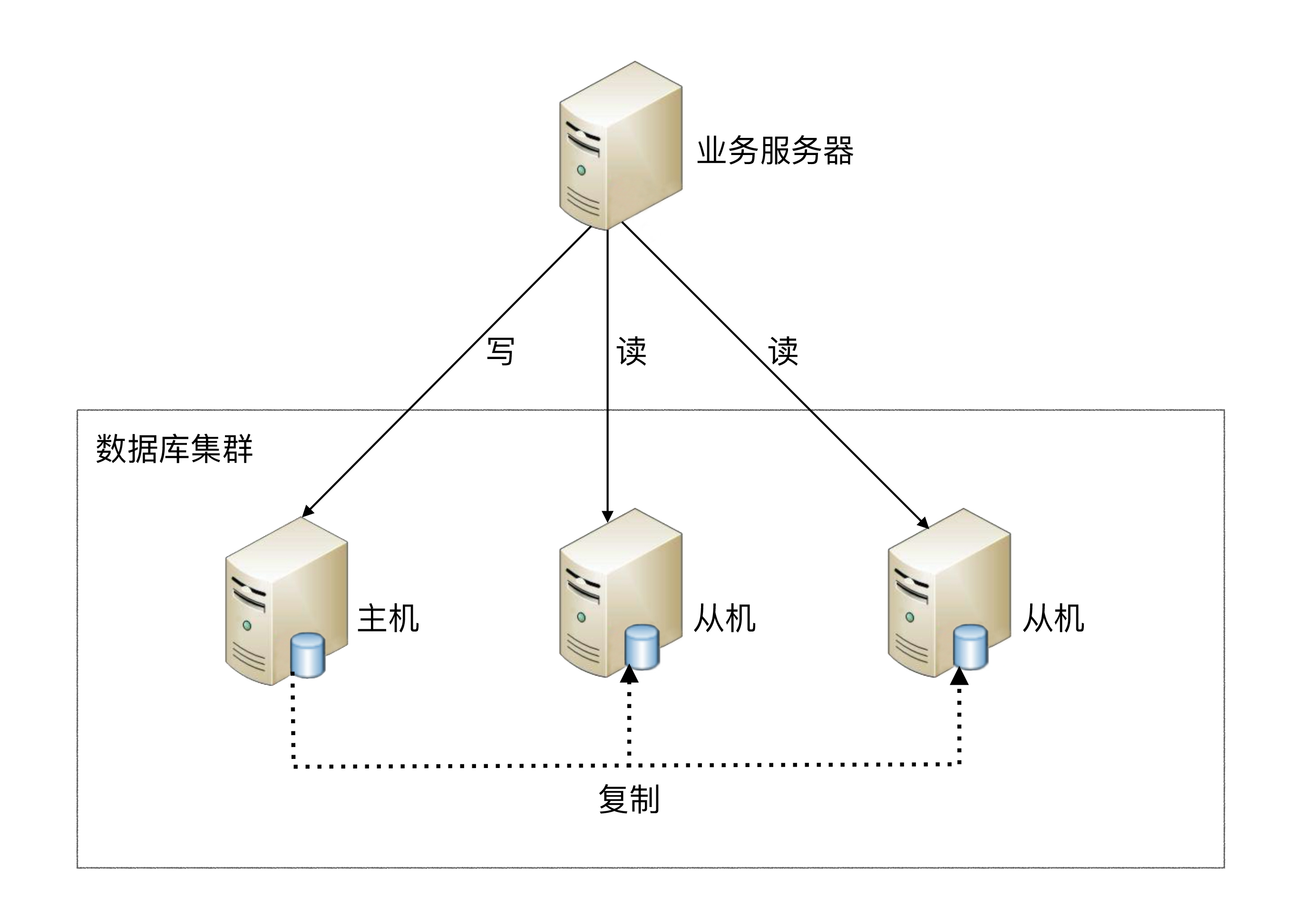
Basic implementation of read-write separation:
主库负责处理事务性的增删改操作,从库负责处理查询操作, can effectively avoid row locks caused by data updates, greatly improving the query performance of the entire system.- 读实片离here
根据 SQL 语义的分析,将读操作和写操作分别路由至主库与从库. - Through the configuration method of
一主多从, query requests can be evenly distributed to multiple data copies, which can further improve the system's processing capabilities. - Using
多主多从can not only improve the throughput of the system, but also improve the availability of the system. It can be achieved when any database is down or even the disk is physically damaged. Does not affect the normal operation of the system.
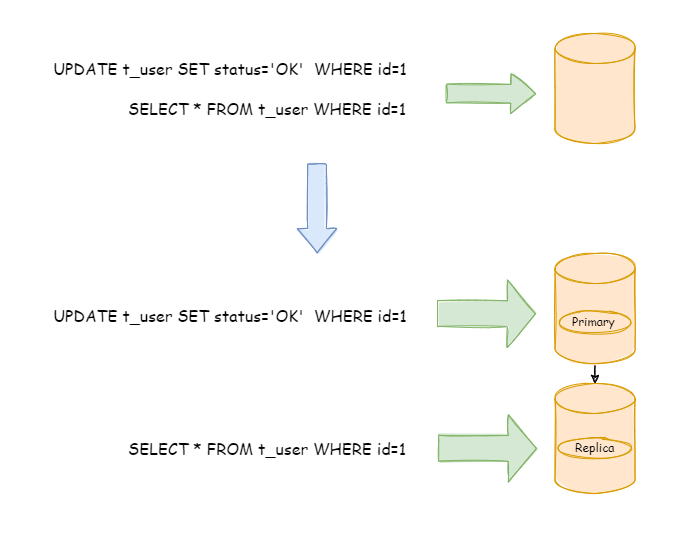
The following figure shows a solution for routing write operations and read operations of user tables to different databases based on business needs:
CAP theory:
CAP theorem, also known as Brewer’s theorem, is a conjecture proposed by Eric Brewer, a computer scientist at the University of California, Berkeley, at the ACM PODC in 2000.对于设计分布式系统的架构师来说,CAP 是必须掌握的理论。
In a分布式系统中, when it comes to read and write operations, only two of the three (Consistence), Availability (Availability), and Partition Tolerance (Partition Tolerance) can be guaranteed. one, the other must be sacrificed.
- C Consistency: For a specified client, read operations are guaranteed to return the latest write operation results.
- A Availability: non-faulty nodes return reasonable responses within a reasonable time
(不是错误和超时的响应) - P Partition Tolerance: When a network partition occurs
(可能是丢包,也可能是连接中断,还可能是拥塞), the system can continue to "perform its duties"
CAP Features:
-
In the actual design process, each system cannot process only one kind of data, but contains multiple types of data.
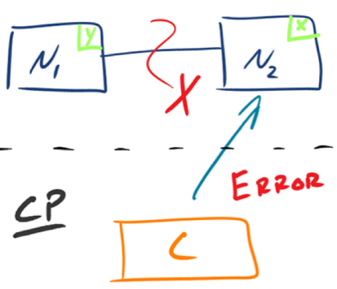
有的数据必须选择 CP,有的数据必须选择 AP,分布式系统理论上不可能选择 CA 架构。- CP: As shown in the figure below,
为了保证一致性, when the partition phenomenon occurs, the data on the N1 node has been updated to y, but due to the interruption of the replication channel between N1 and N2, Data y cannot be synchronized to N2, and the data on the N2 node is still x.这时客户端 C 访问 N2 时,N2 需要返回 Error,提示客户端 C“系统现在发生了错误”,This processing method违背了可用性(Availability) requirements, so the three CAPs can only satisfy CP.
- CP: As shown in the figure below,
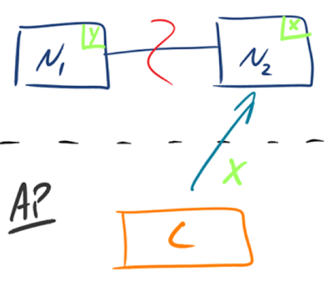
AP: As shown in the figure below,为了保证可用性, when the partition phenomenon occurs, the data on the N1 node has been updated to y, but due to the interruption of the replication channel between N1 and N2, Data y cannot be synchronized to N2, and the data on the N2 node is still x. 这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了, but in fact the latest data is already y, which is the requirement of 不满足一致性 (Consistency), so the three CAPs can only satisfy AP. Note: The N2 node here returns x, which is not a "correct" result, but a "reasonable" result, because x is old data, not a disordered value, just not the latest data.
In CAP theory C 在实践中是不可能完美实现的, during the data replication process, the data of node N1 and node N2 are not consistent (strong consistency). Even if it is not possible强一致性, the application can achieve it最终一致性 in a suitable way. Has the following characteristics:
- Basically Available: When a failure occurs in a distributed system, partial availability is allowed to be lost, that is, core availability is guaranteed.
- Soft State: Allows the system to exist in an intermediate state without affecting the overall availability of the system. The intermediate state here is the data inconsistency in CAP theory.
最终一致性(Eventual Consistency):系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
2. Database sharding architecture
The problem of separation of reading and writing:
The separation of reading and writing disperses the pressure of database read and write operations, but does not disperse the storage pressure. In order to meet the needs of business data storage, it is needed将存储分散到多台数据库服务器上.
Data sharding:
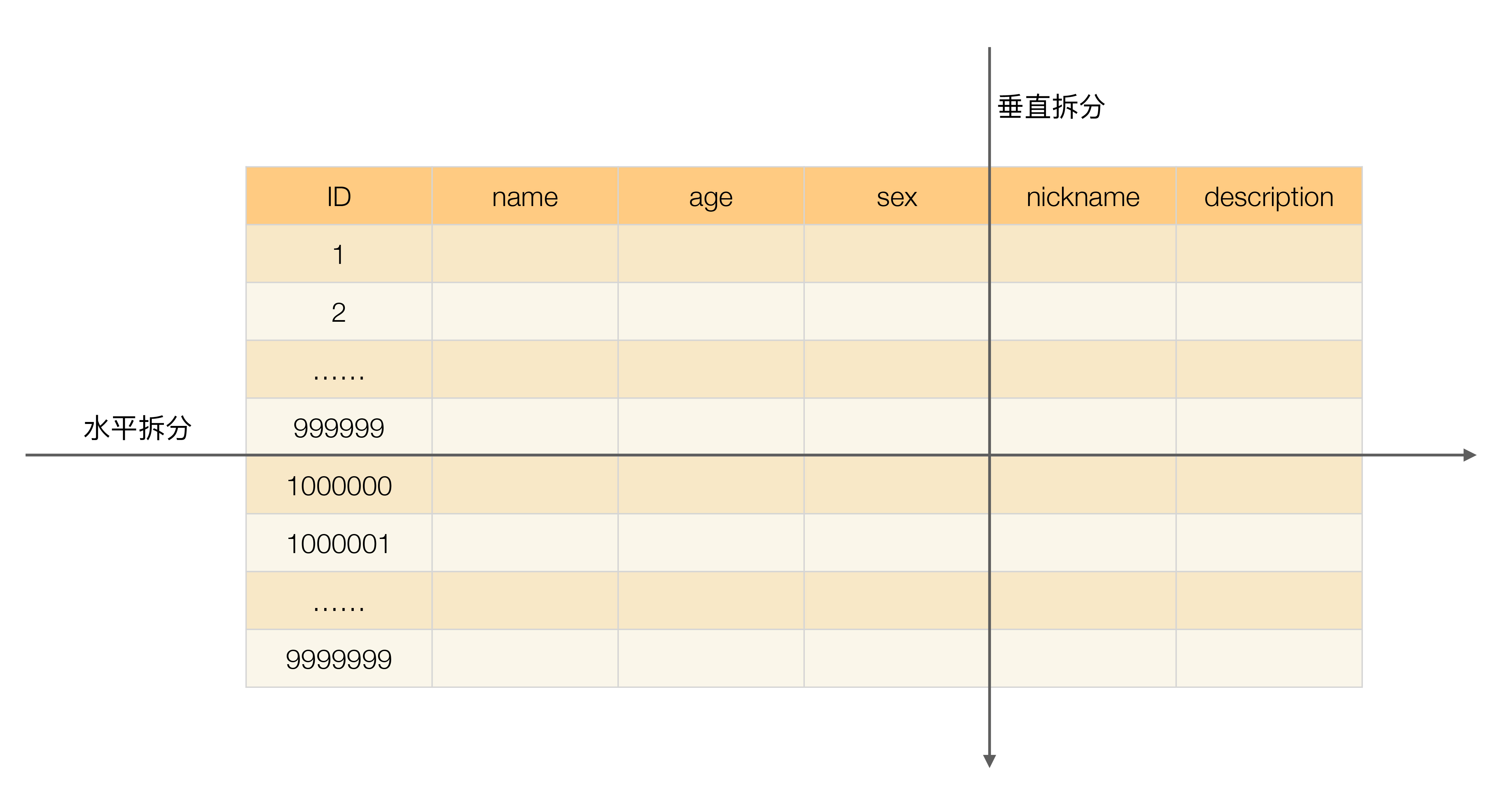
Disperse the data stored in a single database into multiple databases or tables to improve performance bottlenecks and availability. An effective means of data sharding is to perform 分库和分表 on a relational database. The splitting method of data sharding is divided into 垂直分片和水平分片.
2.1. Vertical sharding
Vertical sub-library:
按照业务拆分的方式称为垂直分片,又称为纵向拆分, its core concept is dedicated to special databases. Before splitting, a database consisted of multiple data tables, each table corresponding to a different business. After the split, the tables are classified according to business and distributed to different databases, thereby distributing the pressure to different databases.
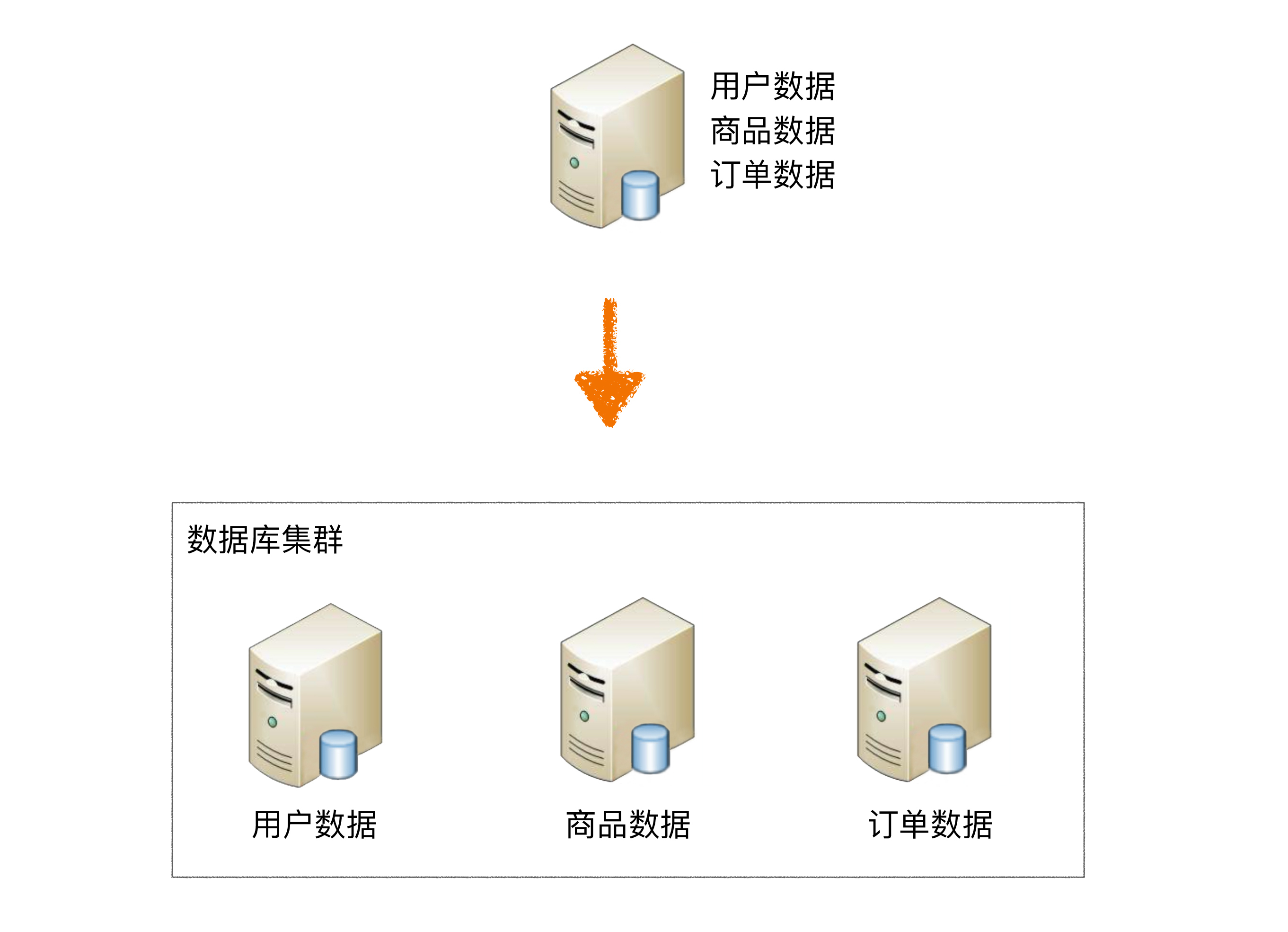
The following figure shows the solution of vertically sharding the user table and order table into different databases according to business needs:
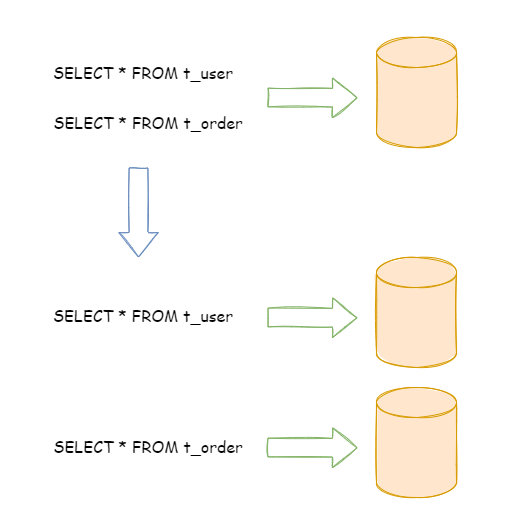
Vertical splitting can alleviate the problems caused by data volume and access, but it cannot cure it.如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
Vertical table:
垂直分表适合将表中某些不常用的列,或者是占了大量空间的列拆分出去。
Suppose we are a dating website. When users filter other users, they mainly use the two fields of age and sex to query, while the two fields of nickname and description are mainly used for display and are generally not used in business queries. description itself is relatively long, so we can separate these two fields into another table, which can bring certain performance improvements when querying age and sex.
The complexity introduced by vertical table sharding is mainly reflected in the increase in the number of table operations. For example, it used to be possible to obtain name, age, sex, nickname, and description with only one query. Now it requires two queries, one query to obtain name, age, and sex, and another query to obtain nickname and description.
水平分表适合表行数特别大的表,水平分表属于水平分片。
2.2. Horizontal sharding
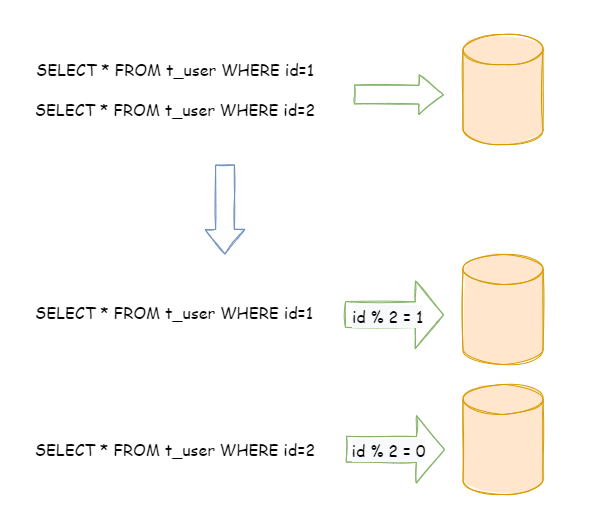
水平分片又称为横向拆分。Compared with vertical sharding, it no longer classifies data according to business logic, but disperses data into multiple libraries or tables through a certain field (or a few fields) and according to certain rules. Each shard only contains part of the data. For example: according to primary key sharding, records with even primary keys are placed in database 0 (or table), and records with odd primary keys are placed in database 1 (or table), as shown in the figure below.
单表进行切分后,是否将多个表分散在不同的数据库服务器中,可以根据实际的切分效果来确定。
-
**Horizontal table splitting:** After a single table is split into multiple tables, the new tables may bring considerable performance improvements even if they are in the same database server. If the performance can meet business requirements, it does not need to be split into multiple tables. A database server, after all, business sub-databases will also introduce a lot of complexity;
-
**Horizontal sub-database:** If a single server still cannot meet the performance requirements after splitting a single table into multiple tables, then multiple tables need to be dispersed in different database servers.
Alibaba Java Development Manual:
[Recommendation] Database and table sharding is only recommended when the number of rows in a single table exceeds 5 million or the capacity of a single table exceeds 2GB.
Note: If the amount of data expected in three years will not reach this level at all,
请不要在创建表时就分库分表.
3. Read-write separation and data sharding architecture
The following figure shows the complex topological relationship between the application and the database cluster when data sharding is used together with read-write separation.
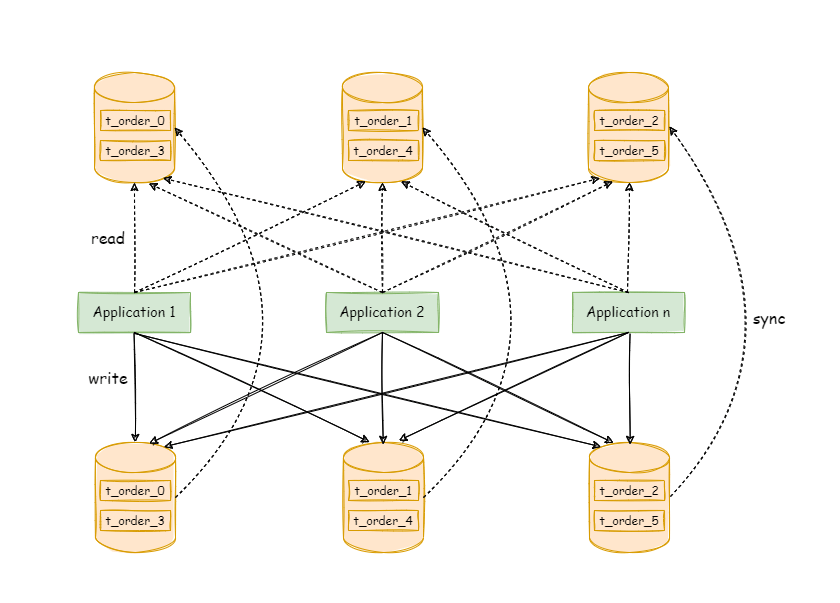
4. Implementation method
There are generally two specific ways to implement read-write separation and data sharding: 程序代码封装 and 中间件封装.
4.1. Program code encapsulation
Program code encapsulation refers to abstracting a 数据访问层(或中间层封装) in the code to achieve separation of read and write operations and management of database server connections.
**The basic architecture is: **Take reading and writing separation as an example
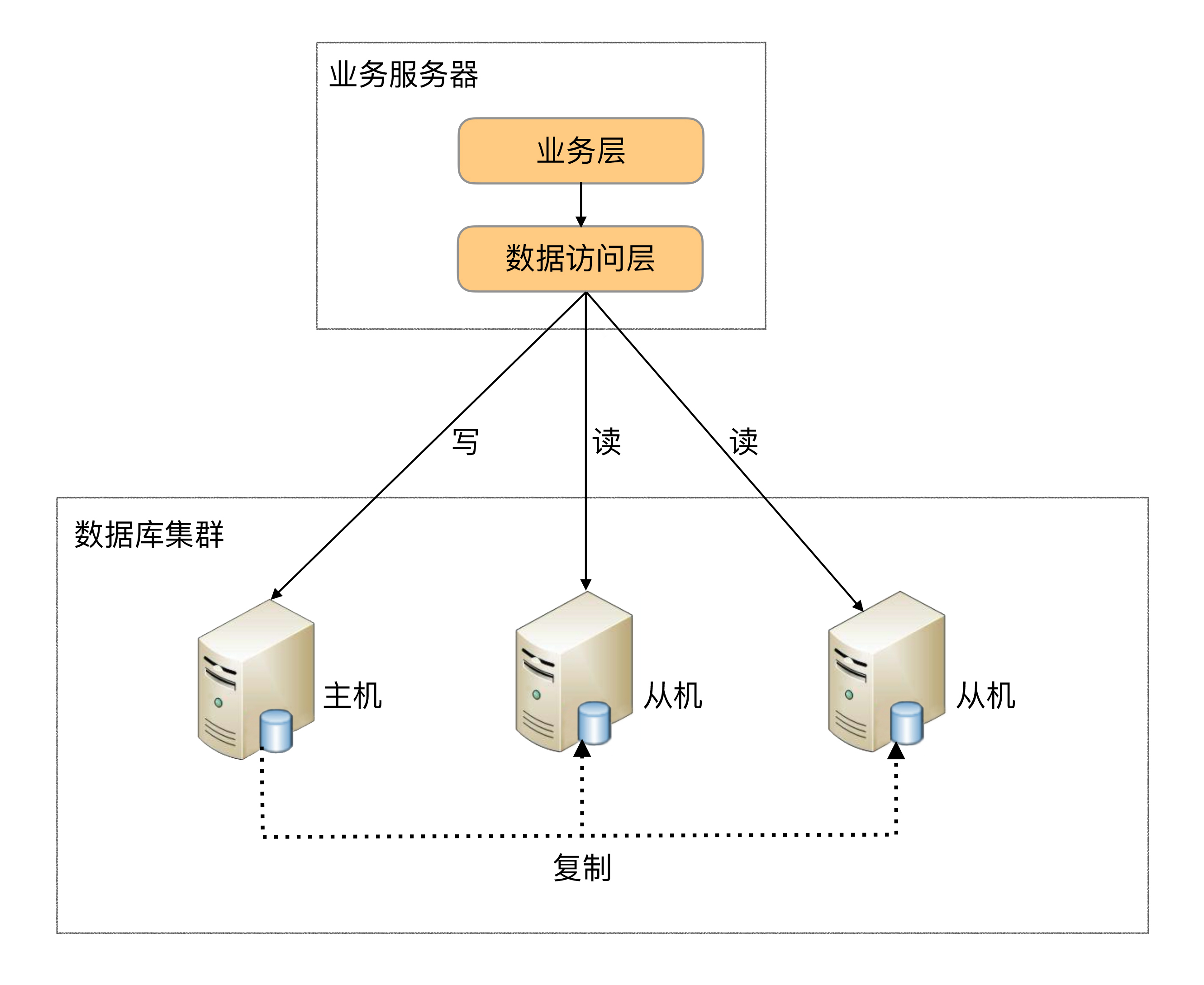
4.2. Middleware encapsulation
Middleware encapsulation refers to独立一套系统出来, which realizes the separation of read and write operations and the management of database server connections. For the business server, there is no difference between accessing the middleware and accessing the database. From the perspective of the business server, the middleware is a database server.
**The basic architecture is: **Take reading and writing separation as an example
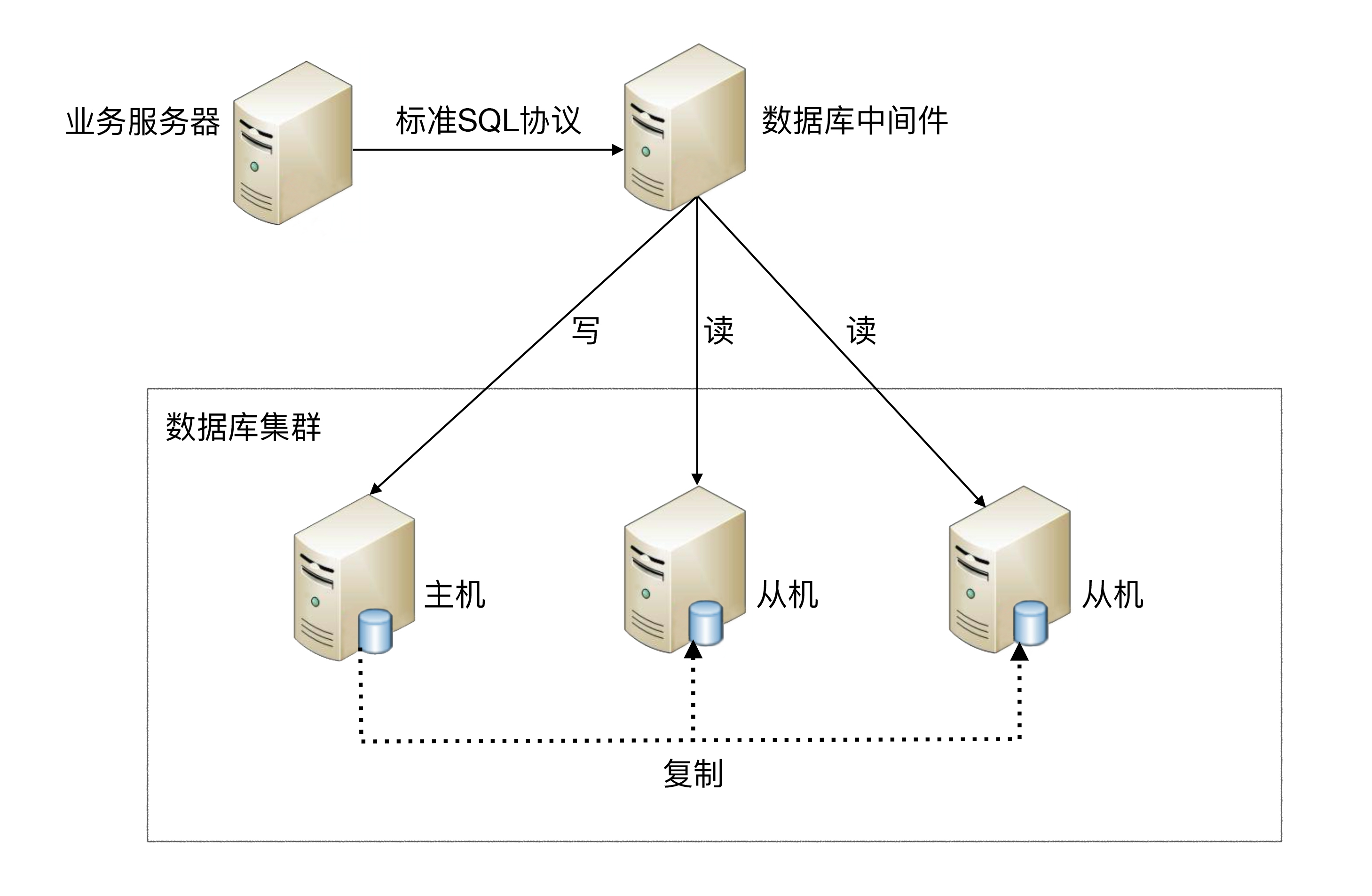
4.3. Common solutions
Apache ShardingSphere (program level and middleware level)
MyCat (database middleware)