singular value decomposition
SVD is a very useful matrix factorization method.
Purpose proposed by SVD: any m × n m\times n m×The matrices of n can be regarded as a hyperellipse (ellipse in high-dimensional space), and they can be regarded as images of the unit sphere S.
A hyperellipse can be formed by placing the unit sphere in the orthogonal direction u 1 , u 2 , . . . , u m \mathbf{u_1},\mathbf {u_2},...,\mathbf{u_m} in1,in2,...,inmBy scaling factor σ 1 , . . . , σ m \sigma_1,..., \sigma_m p1,...,pm, where m is the dimension, if m=2 on the plane
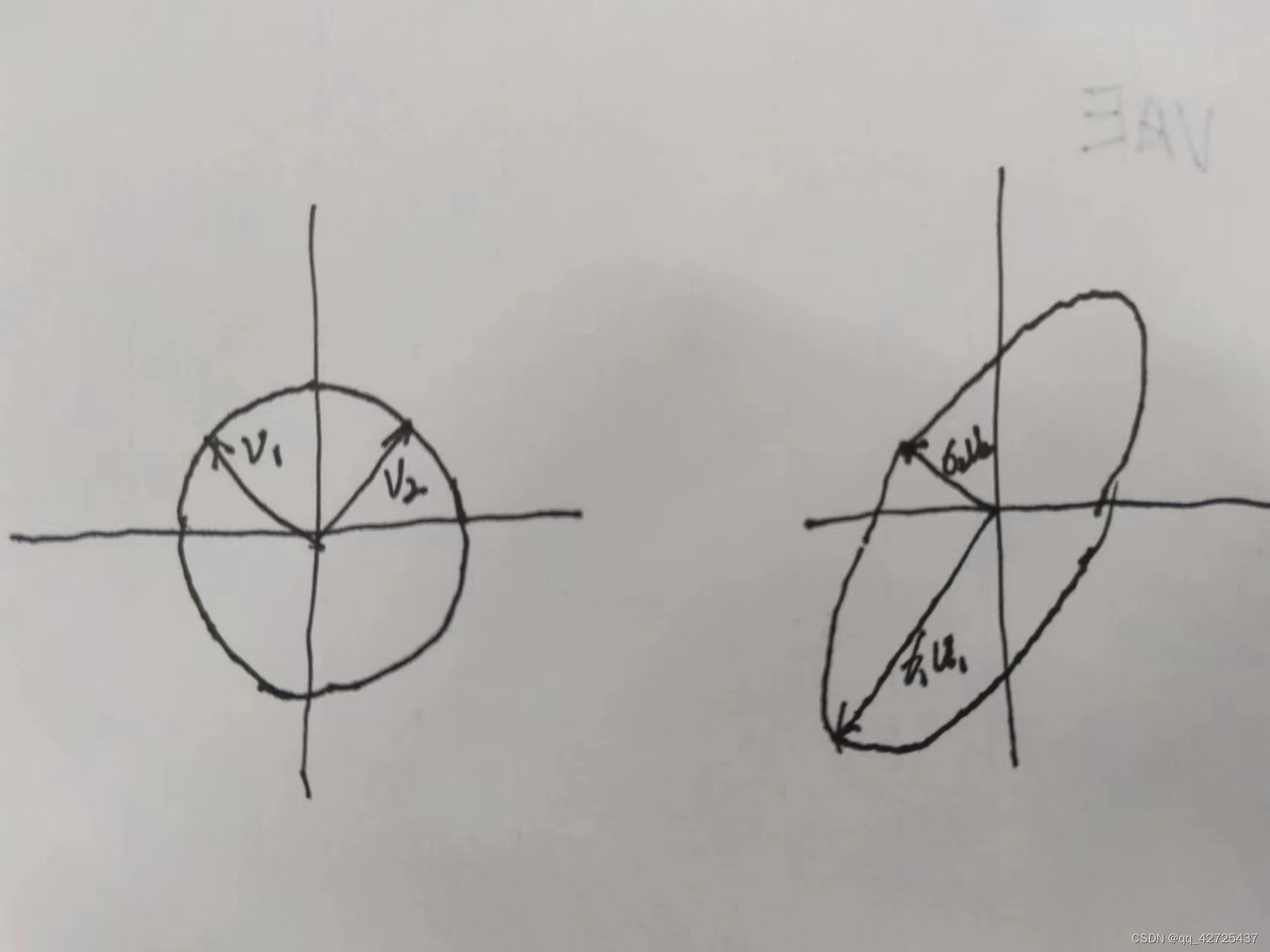
Through the above picture, the following definition can be made:
- singular value: σ 1 , . . . . . . . . , σ n ≥ 0 \sigma_1,..., \sigma_n\geq 0 p1,...,pn≥0Individualization σ 1 ≥ σ 2 ≥ . . . . . . . . . \sigma_1 \geq \sigma_2 \geq ... p1≥p2≥...
- Light singular vectors: u 1 , u 2 , . . . , u n \mathbf{u_1},\mathbf{u_2},...,\mathbf{u_n} in1,in2,...,inn,unit vector
- right singular vectors: v 1 , v 2 , . . . , v n \mathbf{v_1},\mathbf{v_2},...,\mathbf{v_n} in1,in2,...,innThis is ui's opposite direction A v i = σ i u i Av_i = \sigma_i u_i Avi=piini
The left and right names come from the formula of svd.
By matrixing the above formula, we can get:
A V = U ^ Σ ^ AV = \hat U \hat \Sigma AV=IN^S^
Zairi-myeon - Σ ^ ∈ R n × n \hat{\Sigma}\in\mathbb{R}^{n\times n} S^∈Rn×n is a non-negative diagonal matrix
- U ^ ∈ R m × n \hat{U}\in\mathbb{R}^{m\times n} IN^∈Rm×nis one straight orthogonal square
- V ∈ R n × n V\in\mathbb{R}^{n\times n} IN∈Rn×n is a column orthogonal matrix
Therefore V is an orthogonal matrix, because it is a basis vector, so we can get reduced SVD:
A = U ^ Σ ^ V T A = \hat U \hat \Sigma V^T a>A=IN^S^VT
Just like QR decomposition, the expansion U ^ \hat U IN^的列使得 U ∈ R m × m U\in\mathbb{R}^{m\times m} IN∈Rm×m
then demand line Σ ^ \ hat{\Sigma} S^Add some rows with a value of 0 so that the newly added random columns in U can be silenced, thus obtaining a complete SVD
A = U Σ V T A = U \Sigma V^T A=UΣVT
Comparing reduced and full
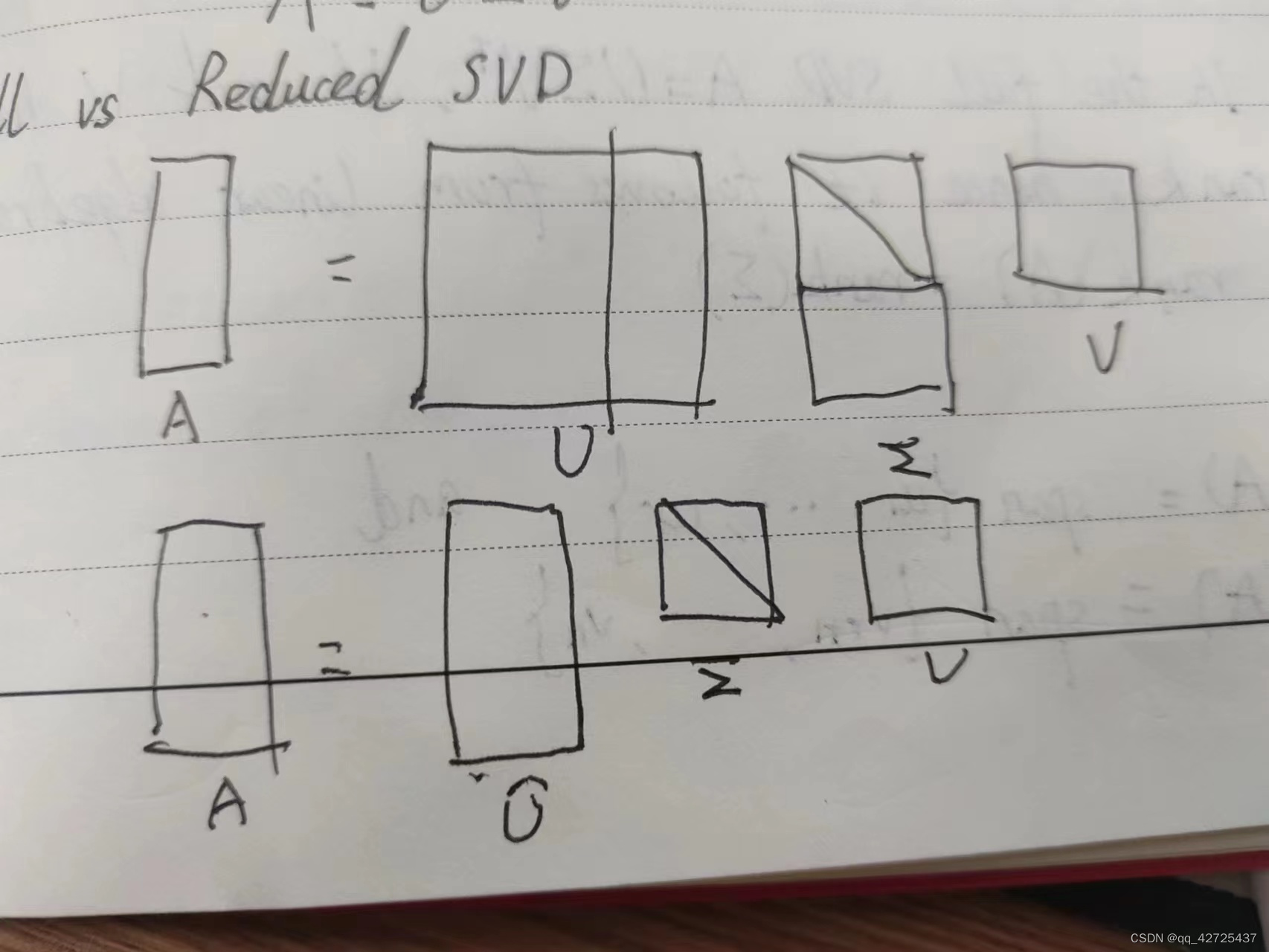
Now reconsider the purpose of changing the spherical shape into a super elliptical shape.
1 V T V^T INT是球型S
2 Σ \Sigma ΣLa extended ball type obtained to reach spherical shape
3 U U URotate projection without changing shape
You can know some matrix properties through SVD
- The rank of A is r, which is the number of non-zero singular values
Proof: U and V are of full rank, so rank(A) = rank( Σ \Sigma Σ) - image(A) = span{ the 1 , the 2 , . . . , u r \mathbf{u_1},\mathbf{u_2},...,\mathbf{u_r}
in1,in2,...,inr}
null(A) = span{ v r + 1 , . . . , v n \mathbf{v_{r+1}},...,\mathbf{v_n} inr+1,...,inn} - ∣ ∣ A ∣ ∣ 2 = σ 1 ||A||_2=\sigma_1 ∣∣A∣∣2=p1
proof: ∣ ∣ A ∣ ∣ 2 ≡ m a x ∣ ∣ V ∣ ∣ 2 = 1 ||A||_2 \equiv max_{||V||_2=1} ∣∣A∣∣2≡atx∣∣V∣∣2=1||Off||_2 - The singular value of A is the square root of the eigenvalue of AAT.
According to the above properties: we can know two applications of SVD
Condition number of rectangular matrix
K ( A ) = ∣ ∣ A ∣ ∣ ∣ ∣ A + ∣ ∣ K(A)=||A||||A^+|| K(A)=∣∣A∣∣∣∣A+∣∣
inside A + A^+ A+This is the opposite
- ∣ ∣ A ∣ ∣ 2 = σ m a x ||A||_2 = \sigma_{max} ∣∣A∣∣2=patx
- ∣ ∣ A + ∣ ∣ 2 = 1 σ m i n ||A^+||_2 = \frac{1}{\sigma_{min}} ∣∣A+∣∣2=pmin1
所以 K ( A ) = σ m a x σ m i n K(A)=\frac{\sigma_{max}}{\sigma_{min}} K(A)=pminpatx
low rank approximation
把SVD变为
A = ∑ j = 1 r σ j u j v j T A = \sum^r_{j=1}\sigma_j u_j v_j^T A=j=1∑rpjinjinjT
每个 u j v j T u_j v_j^T injinjT is a matrix of rank 1
Theorem:
for 0 ≤ v ≤ r 0\ leq v \leq r 0≤in≤A v = ∑ j = 1 v σ j u j v j T Av = \sum^v_{j=1}\sigma_ju_jv_j ^T Av=∑j=1vpjinjinjT
所以
∣ ∣ A − A v ∣ ∣ 2 = inf B ∈ R m × n , r a n k ( B ) ≤ v ∣ ∣ A − B ∣ ∣ 2 ||A-Av||_2 = \inf_{B\in \mathbb{R}^{m\times n}, rank(B)\leq v}{||A-B||_2} ∣∣A−Av∣∣2=B∈Rm×n,rank(B)≤vinf∣∣A−B∣∣2
The same can also be proved in Frobenius norm. This theory shows that SVD is a good method for compressing matrices.