The following content refers to the study notes of Zhihu Singular Value Decomposition (SVD) and Singular Value Decomposition (SVD) of Matrix Analysis , summarized as follows:
1 Introduction
Singular Value Decomposition (SVD) is an algorithm widely used in the field of machine learning. It is a powerful tool for extracting information. It provides a very convenient way of matrix decomposition and can find interesting data in the data . potential model. This article makes an introduction to the principle of SVD and gives a practical use case.
2 Eigenvalues and eigenvectors
Before doing SVD derivation, let’s understand the definition of eigenvalues and eigenvectors:
A x = λ x Ax=\lambda xAx=λx
where A is an n × nn\times nn×matrix of n , xxx is an n-dimensional vector, thenλ \lambdaλ is an eigenvalue of matrix A, andxxx is the eigenvalueλ \lambdaThe eigenvector corresponding to λ .
What are the benefits of finding eigenvalues and eigenvectors? That is, we can decompose the matrix A into eigenvalues.
That is to say, the information of matrix A can be represented by its eigenvalues and eigenvectors.
If we find the n eigenvalues of matrix A λ 1 ≤ λ 2 ≤ . . . ≤ λ n \lambda_{1}\leq \lambda_{2}\leq... \leq \lambda_{n}l1≤l2≤...≤ln, and the eigenvectors w 1 , w 2 , . . . , wn { { w_{1},w_{2}},...,w_{n}} corresponding to these n eigenvaluesw1,w2,...,wn ,
Then the matrix A can be represented by the eigendecomposition of the following formula: where W is the n × nn\times n

spanned by these n eigenvectorsn×n -dimensional matrix, and Σ is the n × nn\times nof the main diagonal of these n eigenvaluesn×n- dimensional matrix.
Generally, we will standardize the n eigenvectors of W, that is, satisfy ∣ ∣ wi ∣ ∣ 2 = 1 \left| \left| w_{i} \right| \right|_{2}=1∣∣wi∣∣2=1,orwiT wi = 1 w_{i}^{T}w_{i}=1wiTwi=1 , at this time the n eigenvectors of W are orthonormal bases, satisfyingWTW = IW^{T}W=IWTW=I ,即 W T = W − 1 W^{T}=W^{-1} WT=W− 1 , that is to say, W is a unitary matrix.
Orthogonal Matrix (Orthogonal Matrix) refers to the matrix whose transpose is equal to its inverse AT = A − 1 A^T=A^{-1}AT=A− 1
unitary matrix is the generalization of the orthogonal matrix to the field of complex numbers
In this way, our eigendecomposition expression can be written as

Summarize, eigenvalue decomposition can obtain eigenvalues and eigenvectors, eigenvalues indicate how important this feature is, and eigenvectors indicate what this feature is. However, eigenvalue decomposition also has many limitations, for example, the transformed matrix must be a square matrix .
3 SVD decomposition
Eigenvalue decomposition is a very good method to extract matrix features, but it is only for square matrices. In the real world, most of the matrices we see are not square matrices. For example, there are M students, each Students have grades in N subjects, so an M*N matrix A cannot be a square matrix. How can we describe the important characteristics of such an ordinary matrix? Singular value decomposition is a decomposition method that can be applied to any matrix:

where U is a m × mm\times mm×The matrix of m ,Σ \SigmaΣ is am × nm\times nm×The matrix of n is all 0 except for the elements on the main diagonal. Each element on the main diagonal is called a singular value. V is ann × nn\times nn×matrix of n . Both U and V are unitary matrices, which satisfy:
U T U = I , V T V = I U^{T}U=I,V^{T}V=I UTU=I,VTV=The
following figure can clearly see the definition of SVD above:

So how do we find the three matrices U, Σ, and V after SVD decomposition?
If we do matrix multiplication with the transpose of A and A, then we get n × nn×nn×A square matrixATAA^{T}A of nAT A__AT Ais a square matrix, then we can perform eigendecomposition, and the obtained eigenvalues and eigenvectors satisfy the following formula:
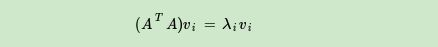
In this way, we can get the matrixATAA^{T}AAThe n eigenvalues of T Aand the corresponding n eigenvectors v. willATAA^{T}AAAll the eigenvectors of T An × nn×nn×The matrix V of n is the V matrix in our SVD formula. Generally we call each eigenvector in Vtheright singular vector
If we do matrix multiplication of A and the transpose of A, we get m × mm × mm×A square matrixAAT AA^{T} of mAAT. _ SinceAAT AA^{T}AAT is a square matrix, then we can perform eigendecomposition, and the obtained eigenvalues and eigenvectors satisfy the following formula:
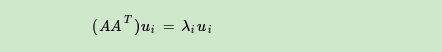
In this way, we can get the matrixAAT AA^{T}AAThe m eigenvalues of T and the corresponding m eigenvectors u. willAAT AA^{T}AAAll the eigenvectors of T are stretched into a m × mm × mm×The matrix U of m is the U matrix in our SVD formula. Generally we call each eigenvector in Utheleft singular vector
We have obtained both U and V, and now there is only the singular value matrix Σ that has not been obtained. Since Σ is 0 except for the singular value on the diagonal, then we only need to obtain each singular value σ. OK.
We noticed:
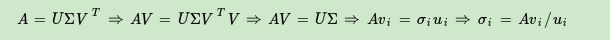
In this way we can find each of our singular values, and then find the singular value matrix Σ.
There is one more question that was not mentioned above, that is, we said ATAA^{T}AAThe eigenvectors of T Aform the V matrix in our SVD, andAAT AA^{T}AAThe eigenvector of T is the U matrix in our SVD. Is there any basis for this? This is actually very easy to prove. Let's take the proof of the V matrix as an example.
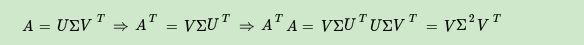
The above formula proves thatUU = I , Σ T = Σ U^{U}=I,\Sigma^{T}= \SigmaUU=I,ST=Σ . It can be seen thatATAA^{T}AAThe eigenvectors of T AA similar method can getAAT AA^{T}AAThe eigenvectors of T form the U matrix in our SVD.
Further, we can also see that our eigenvalue matrix is equal to the square of the singular value matrix, which means that the eigenvalues and singular values satisfy the following relationship: In other words,

we can use σ i = A viui \sigma_{i}=\ frac{Av_{i}}{u_{i}}pi=uiA viTo calculate the singular value, you can also find ATAA^{T}AATake the square rootof the eigenvalues of T Ato find the singular values.
4 SVD Calculation Example
For the singular value of matrix A, we can first calculate it through wolframalpha:

manual calculation steps:

Singular Value Decomposition (SVD) of Matrix Analysis
https://www.bilibili.com/video/av15971352/?p=5
As shown in the figure above, we can see that SVD can divide the matrix into different matrices and add them together, and the coefficients in front of the division are the SVD values. For the singular value, it is similar to the eigenvalue in our eigendecomposition, and it is also in the singular value matrix. Arranged from large to small, and the singular values decrease very fast. In many cases, the sum of the top 10% or even 1% of the singular values accounts for more than 99% of the total sum of the singular values.
In other words, we can also use the largest k singular values and the corresponding left and right singular vectors to approximate the description matrix.

Due to this important property, SVD can be used for PCA dimension reduction for data compression and denoising , and can also be used for recommendation algorithms to decompose the matrix corresponding to users and preferences, and then obtain implicit user needs for recommendation .
5 SVD for PCA
PCA dimensionality reduction, need to find the sample covariance matrix XTXX^{T}XXThe largest d eigenvectors of T X, and then use the matrix formed by the largest d eigenvectors to perform low-dimensional projection dimensionality reduction. It can be seen that in this process, the covariance matrixXTXX^{T}XXT X, when the number of samples is large and the number of features of samples is large, the amount of calculation is very large.
Note that our SVD can also get the covariance matrix XTXX^{T}XXThe matrix formed by the largest d eigenvectors of T XXTXX^{T}XXT X, can also find our right singular matrix V.
In other words, our PCA algorithm can be done without eigendecomposition, but with SVD. This method is very effective when the sample size is large.
In fact, the real implementation behind scikit-learn's PCA algorithm is to use SVD instead of the violent feature decomposition we think.
On the other hand, notice that PCA only uses the right singular matrix of our SVD, not the left singular matrix, so what is the use of the left singular matrix?
Suppose our sample is m × nm × nm×The matrix X of n , if we find the matrixXXT XX^{T}XXThe m × dm×dspanned by the largest d eigenvectors of Tm×d- dimensional matrix U, if we proceed as follows:
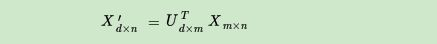
we can get ad × nd × nd×The matrix X' of n , this matrix and our originalm × nm × nm×Compared with the n- dimensional sample matrix X, the number of rows is reduced from m to k, which shows that the number of rows is compressed.
Left singular matrices can be used to compress the number of rows.
The right singular matrix can be used to compress the number of columns, that is, the feature dimension, which is our PCA dimensionality reduction.
6 Summary
1. SVD decomposition is to decompose a matrix into its left eigenspace matrix and right eigenspace matrix, and the eigenvalue matrix in the middle represents the weight value, so we only need to select those important features and keep them every time. Restore the original matrix with almost no loss;
2. SVD decomposition can be regarded as a low-rank expression of the original matrix ;
3. SVD can be used for data denoising;
4. SVD can be used for feature dimension compression;
