1. CUDA thread organization and GPU architecture
1.1 CUDA thread organization
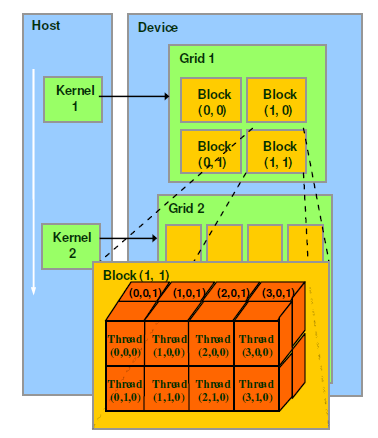
A kernel function corresponds to a grid. There are several blocks in the grid, and several threads in the block. 32 threads are called a warp.
The following four paragraphs are introduced and copied from: Understanding thread, block, grid and warp in CUDA - Zhihu (zhihu.com)
SM adopts the SIMT (Single-Instruction, Multiple-Thread, single instruction multi-thread) architecture. Warp (thread warp) is the most basic execution unit. A warp contains 32 parallel threads. These threads. Execute the same instruction with different data resources
When a kernel is executed, the thread blocks in the grid are allocated to SMs. The threads of a thread block can only be scheduled on one SM. , SM can generally schedule multiple thread blocks, and a large number of threads may be assigned to different SMs. Each thread has its own program counter and status register, and uses the thread's own data to execute instructions. This is the so-called Single Instruction Multiple Thread (SIMT).
One CUDA core can execute one thread. The CUDA core of an SM will be divided into several warps (that is, CUDA cores are grouped in SM), and the warp scheduler is responsible for scheduling. Although the threads in a warp start from the same program address, they may have different behaviors, such as branch structures. Because the GPU stipulates that all threads in a warp execute the same instructions in the same cycle, warp divergence will cause performance degradation. The concurrent warps of an SM are limited. Due to resource limitations, SM must allocate shared memory for each thread block and also for each thread. Threads in a warp are allocated independent registers, so the configuration of the SM will affect the number of thread blocks and warp concurrency it supports.
The threads in a warp must be in the same block. If the number of threads in the block is not an integral multiple of the warp size, then there will be some inactive threads left in the warp where the extra threads are located, that is, It is said that even if there are not enough threads that are an integral multiple of the warp, the hardware will make up enough threads for the warp, but those threads are inactive. It should be noted that even if these threads are inactive, they will consume SM resources. Since the size of the warp is generally 32, the size of the threads contained in the block should generally be set to a multiple of 32.
1.2 GPU framework
GPU
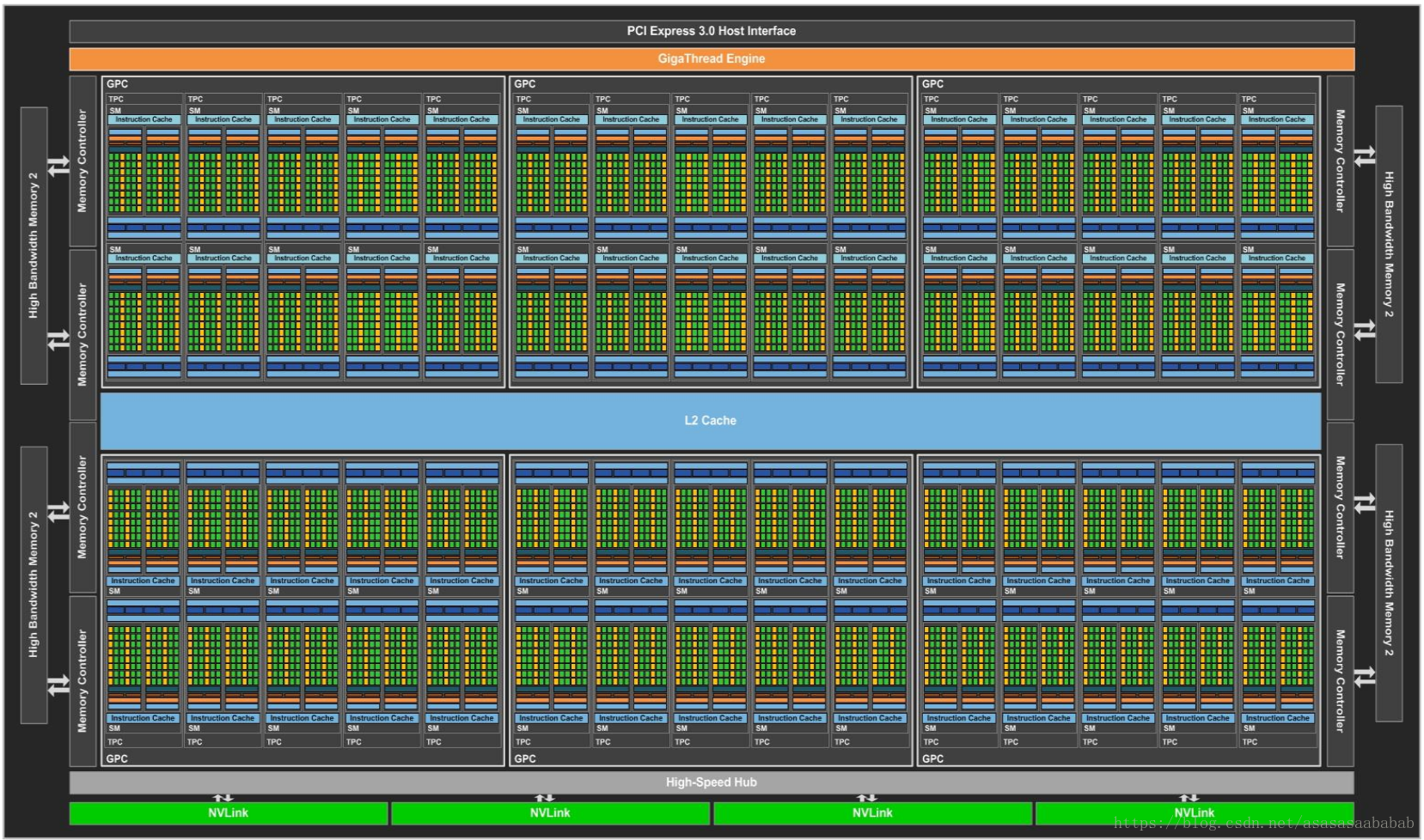
The picture below is the architecture diagram of a GPU, with many SMs in it.
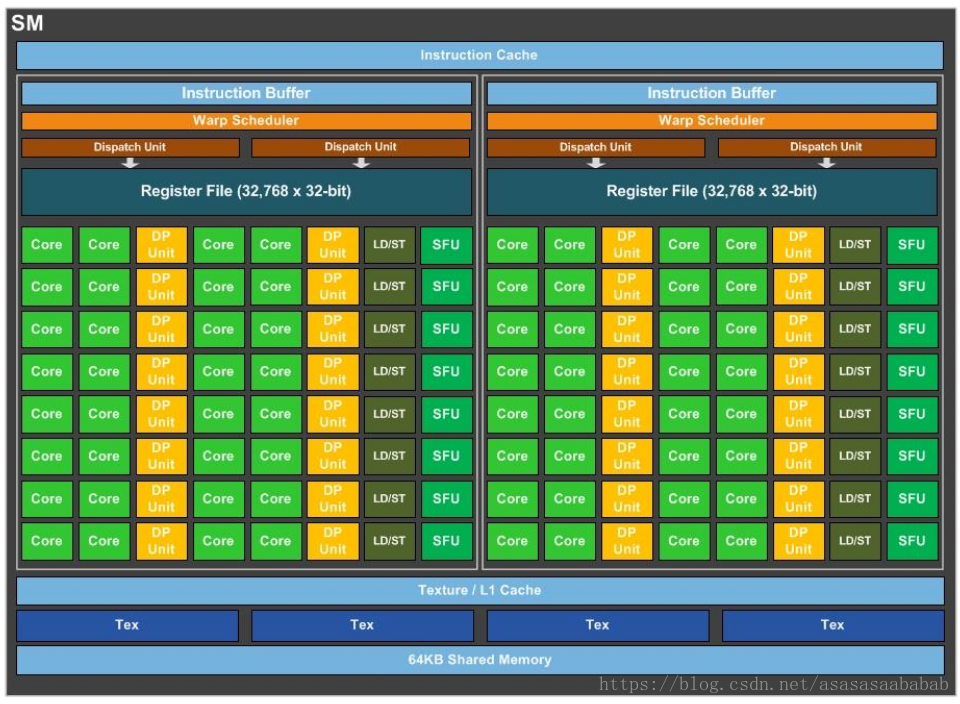
SM (Streaming MultiProcessor)
There are two SMP (SM Processing Block) in one SM. The green square Core is the CUDA core; the dark green square LD/ST is the memory operation load/store; it should be noted that the CUDA core does single-precision floating-point number operations, and the DP Unit does double-precision floating-point number operations. The ratio of the number of users is 2:1; the green square SFU refers to the Special Function Unit, which performs calculations of some special functions, such as sin, cos, etc.
Each SM has its own instruction cache, L1 cache, and shared memory. Each SMP has its own warp scheduler, Register File, etc.
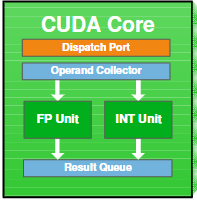
CUDA core
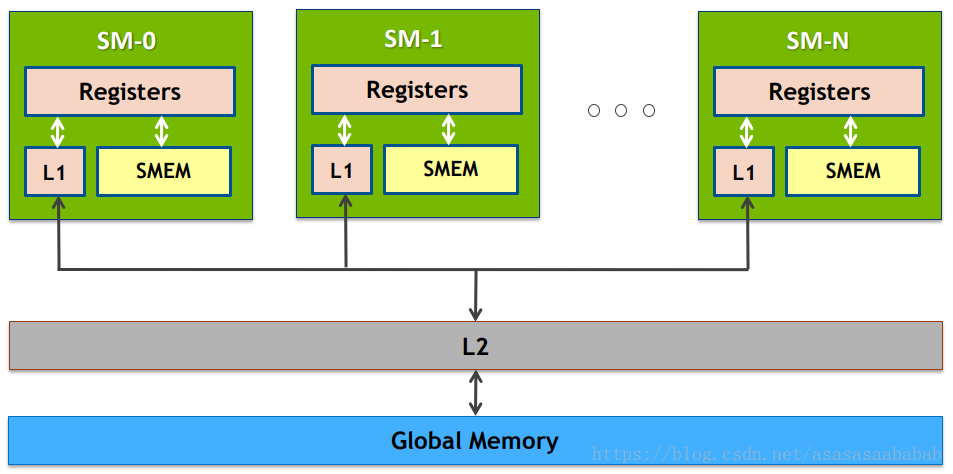
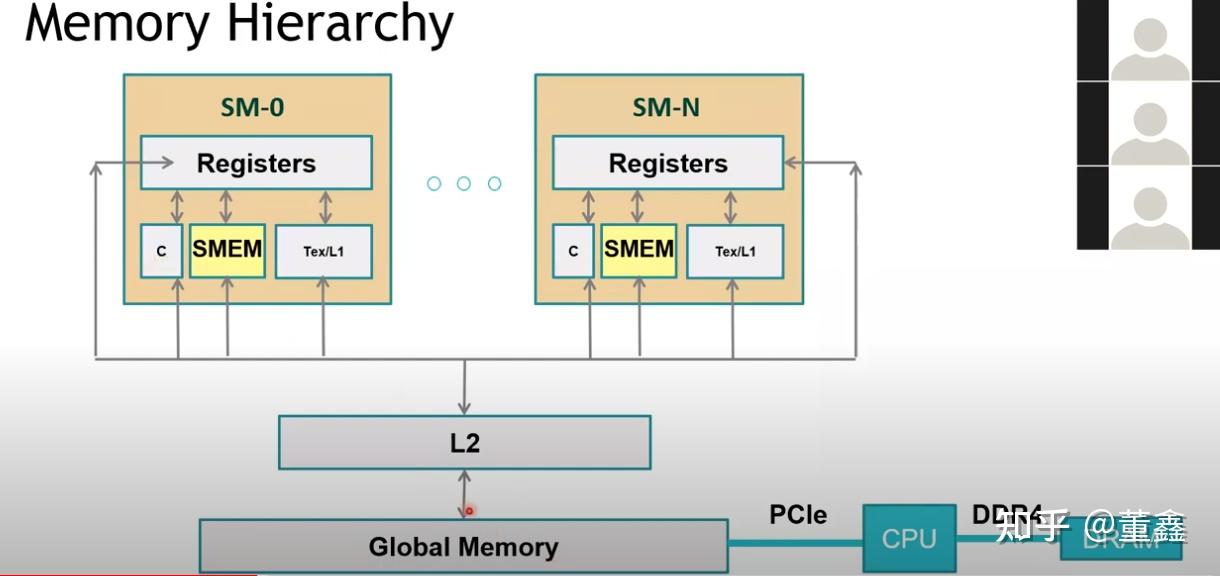
GPU memory architecture
Global Memory is commonly referred to as video memory (GPU Memory), and L1 cache refers to shared memory (will be explained in detail in Chapter 5).
Every time shared memory (that is, L1) wants to access Global Memory, it will first check if there is one in L2. If there is, there is no need to go to global memory.
2. Hello World
The GPU is just a device. For it to work, it needs a host to give it commands. This host is the CPU.
All calls made by the host to the device are implemented through the kernel function. Therefore, the structure of a simple CUDA program has the following form:
int main() {
主机代码
核函数的调用
主机代码
return 0;
}
The kernel function must be modified with ***__global__*** in front of it, and the return value type must be void, such as the following:
__global__ void hello_from_gpu() {
printf("Hello World From the GPU!");
}
The order of __global__ and void can be exchanged
The above kernel function needs to be called by the host to work, as follows:
#include<stdio.h>
__global__ void hello_from_gpu() {
printf("Hello World From the GPU!");
}
int main() {
hello_from_gpu<<<1, 1>>>();
cudaDeviceSynchronize();
return 0;
}
- hello_from_gpu<<<1, 1>>>() : When the host calls a kernel function, it needs to indicate how many threads are allocated to the device. The first parameter is grid_size, and the second parameter is block_size. In other words, the first parameter is the number of blocks, and the second parameter is the number of threads in a block.
- cudaDeviceSynchronize() : The output stream is first stored in the buffer, and the buffer will not be refreshed automatically. The buffer will only be refreshed when the program encounters some kind of synchronization operation. This function synchronizes the host and device, thereby causing the buffer to be flushed.
3. Array addition
#include<stdio.h>
#include<math.h>
const double a = 1.11;
const double b = 2.22;
__global__ void add(const double *x, const double *y, double *z);
int main() {
const int N = 10000;
const int M = sizeof(double) * N;
double *h_x = (double*)malloc(M);
double *h_y = (double*)malloc(M);
double *h_z = (double*)malloc(M);
for (int i = 0; i < N; i++) {
h_x[i] = a;
h_y[i] = b;
}
double *d_x, *d_y, *d_z;
cudaMalloc((void**)&d_x, M);
cudaMalloc((void**)&d_y, M);
cudaMalloc((void**)&d_z, M);
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice);
const int block_size = 128;
const int grid_size = N / block_size;
add<<<grid_size, block_size>>>(d_x, d_y, d_z);
cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost);
free(h_x);
free(h_y);
free(h_z);
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
return 0;
}
__global__ void add(const double *x, const double *y, double *z) {
const int tid = blockIdx.x * blockDim.x + threadIdx.x;
z[tid] = x[tid] + y[tid];
}
C++ VS CUDA
Using C++ to write array addition requires a for loopfor(int i = 0; i < N; i++){z[i] = x[i] + y[i]}, but when using CUDA, "Single instruction - multi-thread" is used, That is, SIMT maps array elements to threads one-to-one. Each thread performs the addition of a pair of array elements, that is, each thread will performSIMT. a>, no need for that layer of for loop. z[tid] = x[tid] + y[tid]
Memory allocation, release, copy
-
cudaMalloc: Allocate device memory. The function prototype is as follows:
cudaError_t cudaMalloc(void **address, size_t size);
Address is the pointer to the device memory to be allocated, that is, the pointer of the address, which is a double pointer. size is the number of bytes of memory to be allocated.
(void**) is a forced conversion and does not need to be written, which means that device memory allocation can also be written like this:cudaMalloc(&d_x, M);
-
cudaFree: Release device memory. The memory allocated by cudaMalloc needs to be released using cudaFree. The function prototype is as follows:
cudaError_t cudaFree(void* adress); -
cudaMemcpy: Data transfer between the device and the host. The function prototype is as follows:
cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind);dst is the destination address; src is the source address; count is the number of bytes copied; kind is an enumeration type variable indicating the data transfer direction, with five values: cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice, cudaMemcpyDefault (according to dst and src automatically determines the transmission direction, which requires the system to have the function of unified virtual addressing)
-
Invisible device initialization: In the CUDA runtime API, there is no function that explicitly initializes the device. The first time a runtime API function is called that has nothing to do with device management and version query functions, the device will be automatically initialized.
When N % block_size != 0
Before, specify N=100000000, which is an integer multiple of block_size, exactly 781250 blocks. Each block has 128 threads, and each thread is responsible for the addition of a pair of array elements. But what about when N is not an integer multiple of block_size? For example, when N=100000001, grid_size=781251 should be specified, that is, the 128 threads in the last block only need to process the addition of a pair of array elements. It should be noted that the above writing method z[tid] = x[ tid] + y[tid], an out-of-bounds access will occur, so an if should be written as follows:
if (tid < N) {
z[tid] = x[tid] + y[tid];
}
In addition, the previous grid_size assignment should also be modified.
grid_size = (N % block_size == 0) ? (N / block_size) : (N / block_size + 1)
4. Device functions
Kernel functions can call custom functions without execution configuration. Such custom functions are called device functions.
__global__ The modified function is a kernel function, which is called by the host and executed by the device.
__device__ The modified function is the device function (device function), which is called by the device and executed by the device.
__host__ The modified function is an ordinary C++ function on the host side. It is called and executed by the host. This modifier can be omitted.
Give a chestnut
__device__ double add_device(const double x, const double y) {
return (x + y);
}
__global__ void add(const double *x, const double *y, double *z) {
const int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
z[tid] = add_device(x[tid], y[tid]);
}
}
add_device is a device function, add is a core function, and add calls add_device.
5. Memory organization
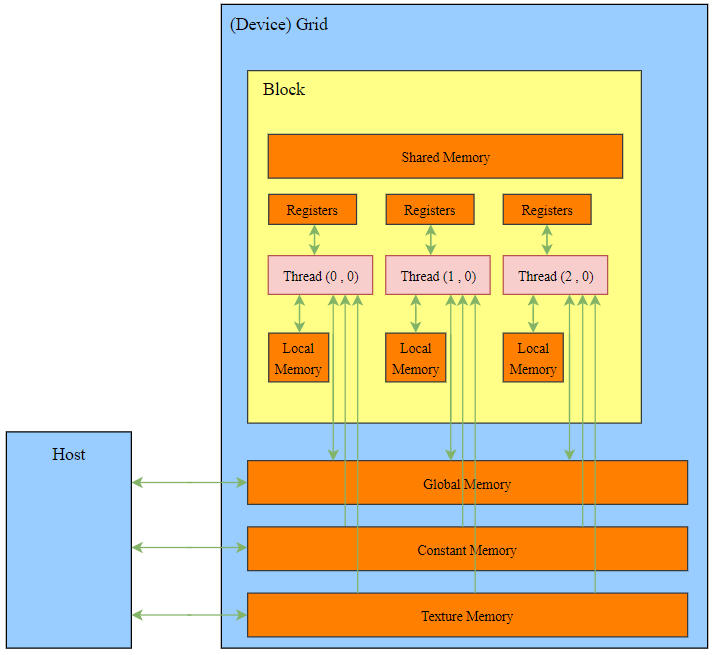
5.1 Global memory
Global memory is not on-chip and is the memory space with the largest capacity and highest latency in the GPU.
All threads in the kernel function can access global memory. The main role of global memory is to provide data for the kernel function and transfer data between the host and the device, and between the device and the device.
A global memory variable can be used on the host sidecudaMalloc for dynamic declaration, or it can be statically declared using ***__device__***, such as This looks like this:
__device__ double data; // 静态全局内存变量
It should be noted that the address of data cannot be obtained through &, but its address can be obtained through cudaGetSymbolAddress. The function prototype is as follows:
cudaError_t cudaGetSymbolAddress(void **devPtr, const void *symbol); // devPtr是symbol的地址
This function can obtain the global address of the device, and then transfer data to the host memory through cudaMemcpy, such as the following:
__device__ double dev_data;
int main() {
xxxxxxxxxxxx
double *dev_ptr = NULL;
cudaGetSymbolAddress((void**)&dev_ptr, dev_data);
xxxxxxxxxxxx
}
In addition, there is another way to realize data transfer between static global memory and host memory, which requires the use of two functions: cudaMemcpyToSymbol and cudaMemcpyFromSymbol. The function prototype is as follows:
cudaError_t cudaMemcpyToSymbol(
const void *symbol, // 静态全局内存变量的名称
const void *src, // 主机内存缓冲区指针
size_t count, // 复制的字节数
size_t offset = 0, //从symbol对应设备地址开始偏移的字节数
cudaMemcpyKind kind = cudaMemcpyHostToDevice // 可选参数
) // 主机->设备(给symbol赋值)
cudaError_t cudaMemcpyFromSymbol(
void *dst, // 主机内存缓冲区指针
const void *symbol, // 静态全局内存变量的名称
size_t count, // 复制的字节数
size_t offset = 0, //从symbol对应设备地址开始偏移的字节数
cudaMemcpyKind kind = cudaMemcpyDeviceToHost // 可选参数
) // 设备到主机(给dst赋值)
The specific usage is as follows:
#include<stdio.h>
__device__ int d_x = 1;
__device__ int d_y[2];
__global__ void my_kernel() {
d_y[0] += d_x;
d_y[1] += d_x;
}
int main() {
int h_y[2] = {
10, 20};
cudaMemcpyToSymbol(d_y, h_y, sizeof(int)*2);
my_kernel<<<1, 1>>>();
cudaMemcpyFromSymbol(h_y, d_y, sizeof(int)*2);
return 0;
}
In fact, the constant memory to be introduced below can also use the above two functions for data transmission, which means that symbol can also be the name of a constant memory variable.
5.2 constant memory (const memory)
Constant memory is global memory with constant cache, and its access speed is higher than global memory.
Constant memory variables are modified using __constant__ and need to be declared in the global space and outside all kernel functions.
Data transfer between constant memory and host memory is also implemented through cudaMemcpyToSymbol and cudaMemcpyFromSymbol.
5.3 Texture memory and surface memory
Texture memory and surface memory are similar to constant memory and are also global memories with cache, but the capacity of texture memory and table memory is larger than that of constant memory.
Texture memory resides in device memory and is cached in a read-only cache per SM. Texture memory is a global memory accessed through a designated read-only cache. It optimizes the locality of two-dimensional space, so use texture memory to access two-dimensional dataThreads can achieve optimal performance.
5.4 Register
The registers are on-chip and have the fastest access speeds of any memory.
Variables declared in the kernel function and not modified by other modifiers are usually stored in registers. Registers are usually used to store thread private variables that need to be accessed frequently in kernel functions. These variables have the same life cycle as the kernel function. After the kernel function is executed, they can no longer be accessed. For example, tid in the following code will be stored in the register.
__global__ void add(const double *x, const double *y, double *z) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
z[tid] = add_device(x[tid], y[tid]);
}
}
Built-in variables such as gridDim, blockDim, blockIdx, threadIdx, warpSize, etc. are also stored in registers.
The number of registers in an SM is relatively limited. Once the kernel function uses the number of registers that exceeds the hardware limit, local memory will be used to replace the multi-occupied registers. This register overflow will bring adverse effects on performance. Actual programming We should avoid this situation during the process. Use the nvcc compilation option maxrregcount to control the maximum number of registers used by kernel functions.
5.5 local memory
Local memory is almost the same as registers in usage, but from a hardware perspective, local memory is only a part of global memory.
In the kernel function, variables that are stored in registers but cannot enter the allocated register space will be overflowed into local memory. Variables that may be stored in local memory are:
- Local array referenced with unknown index at compile time
- Large local structures or arrays that may take up a lot of register space
- Any variable that does not meet the kernel function register qualifications
5.6 shared memory
Shared memory has read and write speeds second only to registers. Variables modified by ***__shared__*** in the kernel function are stored in shared memory.
Shared memory is visible to the entire thread block and is common to all threads in a thread block, but they cannot access the shared memory of other thread blocks.
Threads in a thread block can cooperate with each other by using data in shared memory. However, when using shared memory, the following functions must be called for synchronization:
void __sybcthreads()
This function sets a barrier for all threads in the thread block, so that all threads in the thread block must execute to the barrier before they can continue to execute, avoiding potential data conflicts.
5.7 L1 and L2 cache
Starting from the Fermi architecture, there are L1 cache (level one cache) at the SM level and L2 cache (level two cache) at the device (a device has multiple SMs). They are mainly used to cache global memory and local memory accesses. , reduce delay.
From a programming perspective, shared memory is a programmable cache (the use of shared memory is completely controlled by the user), while the L1 and L2 caches arenon-programmable cache (the user can only instruct the compiler to make some choices at most)
5.8 Host-side memory - pageable memory, page-locked memory
In the process of collaborative computing between CPU and GPU, data transmission between CPU memory and GPU memory is involved.
The operating system divides CPU memory into two categories at the logical level: pageable memory (Pageable Memory) and page lock memory (Page Lock Memory, also known as Pinned Memory). Pageable memory does not have locking features and may be swapped out, such as Transferred to the hard disk, while page-locked memory is locked and will not be swapped out.
The GPU cannot safely access data on pageable memory because the host operating system has no control over when that data is physically moved. Therefore, data transfer between CPU memory and GPU memory occurs between page-locked memory and global memory. If the data on the pageable memory wants to be transferred to the GPU memory, it should first be transferred to the page-locked memory, and then transferred from the page-locked memory to the GPU memory; if the data on the GPU memory wants to be transferred to the CPU memory, it can only be transferred to Page locked memory.
CUDA provides cudaMallocHost, which can directly allocate page-locked memory:
cudaError_t cudaMallocHost(void **devPtr, size_t count);
Then it needs to be released through cudaFreeHost:
cudaError_t cudaFreeHost(void *ptr);