Foreword:
In order to facilitate your review and consolidation of basic knowledge, I have compiled this summary of interview questions.

Article directory
Go basics
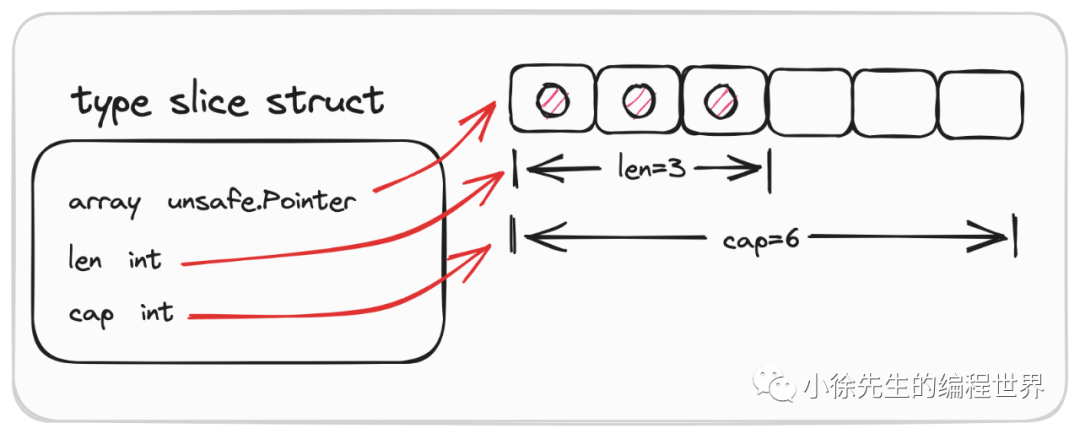
1. Let’s talk about the bottom layer of slice in go
The underlying data structure in go is an array pointer pointing to the underlying array, len represents the array length, and cap represents the slice capacity. The elements in the slice are stored in an area with continuous memory addresses, and the elements at the specified location can be quickly retrieved using the index; the length and capacity of the slice are variable and can be expanded as needed during use. The main implementation of slice is expansion. The underlying layer of slice is an array pointer. When appended, the length of the slice does not exceed the capacity cap, and the new elements will be added directly to the array. When appended, the slice length exceeds the capacity cap, and a new slice will be returned. After the expansion, copy the old data to the new array, and then point the Array pointer to the new array address. For slice expansion.
Before Go 1.17, if the required capacity is greater than twice the expansion, it will be directly changed to the required capacity; if it is less than 1024, the capacity will be doubled. If it is greater than 1024, it will enter a loop to expand the capacity. Each time it is expanded to 1.25 times the original size until it is larger than the required capacity.
After Go 1.18, if the required capacity is greater than twice the expansion, it will directly become the required capacity; if it is less than 256, the capacity will become twice the original capacity; if it is greater than 256, it will enter a loop. , to expand the capacity to (old capacity + 3*256) each time until it is larger than the required capacity.
In go, there is no reference transfer, only value transfer. When channels, pointers, and maps are passed, it is not a copy of the value, but the address.
type SliceHeader struct {
Array uintptr //指向底层数组的指针
Len int //切片的长度
Cap int //切片的容量
}
2. Let’s talk about the bottom layer of Map in go
Map, also known as dictionary, is a commonly used data structure. Its core features include the following three points:
(1) Stores patterns based on key-value pair mapping; a> a> Each element in the Bucket array is a bmap structure, that is, each bucket (bucket) is a bmap structure. Each bucket stores 8 kv pairs. If 8 are full, If another key falls into this bucket, overflow will be used to connect to the next bucket (overflow bucket). In go's map implementation, its underlying structure is hmap, and hmap maintains several bucket arrays (i.e. bucket arrays). map is a storage structure of key-value pairs, in which keys cannot be repeated, and its underlying implementation uses a hash table. (3) Control of read, write and delete operations, time complexity O(1).
(2) Deduplication of stored data based on key dimension;
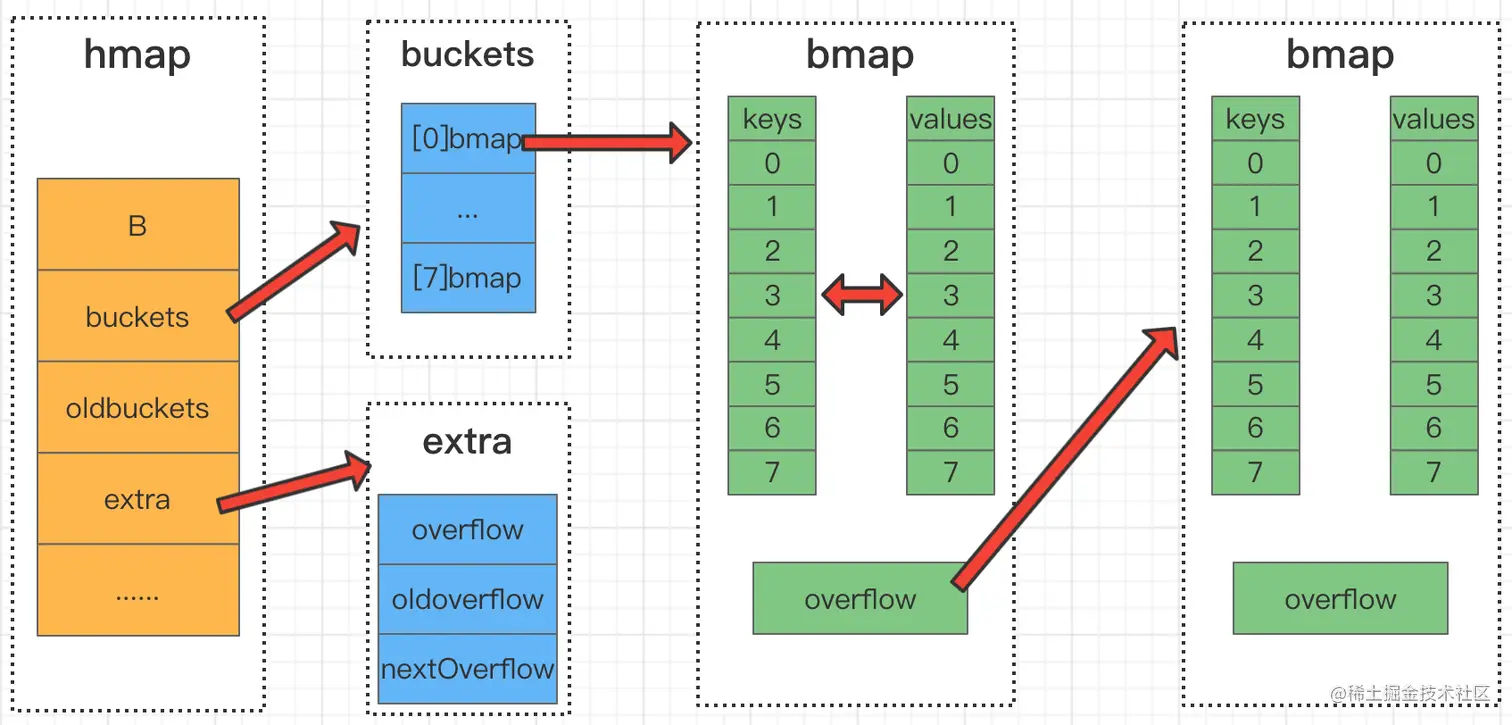
type hmap struct {
count int // 元素的个数
flags uint8
B uint8 // buckets 数组的长度,就是 2^B 个
noverflow uint16
hash0 uint32
buckets unsafe.Pointer // 2^B个桶对应的数组指针
oldbuckets unsafe.Pointer // 发生扩容时,记录扩容前的buckets数组指针
nevacuate uintptr
extra *mapextra //用于保存溢出桶的地址
}
//在编译期间的bmap结构体
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
data byte[1] //key value数据
overflow *bmap //溢出bucket的地址
}
When searching/storing hash, the key will be hashed first, the last B bits of the obtained hash value will be extracted to lock the index of the bucket, and then the first eight digits of the hash value will be used to determine the key in the bmap. Storage location, if a hash conflict occurs, there are two solutions, one is the open addressing method, and the other is the zipper method.
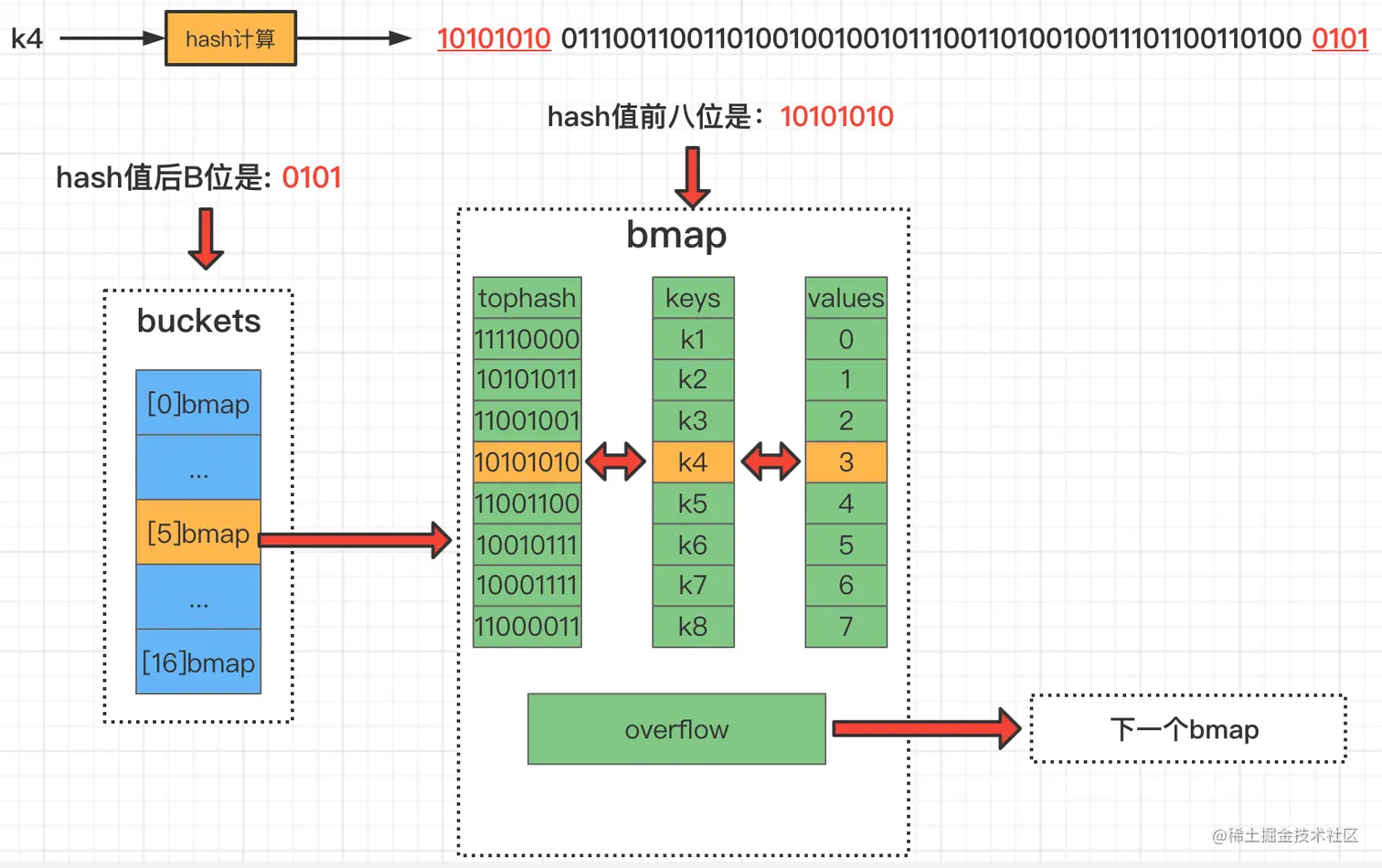
Regarding hash conflicts: When two different keys fall into the same bucket, a hash conflict occurs. The conflict resolution method is to use the linked list method: in the bucket, find the first empty position from front to back and insert it. If 8 kvs are full, then the current bucket will be connected to the next overflow bucket (bmap).
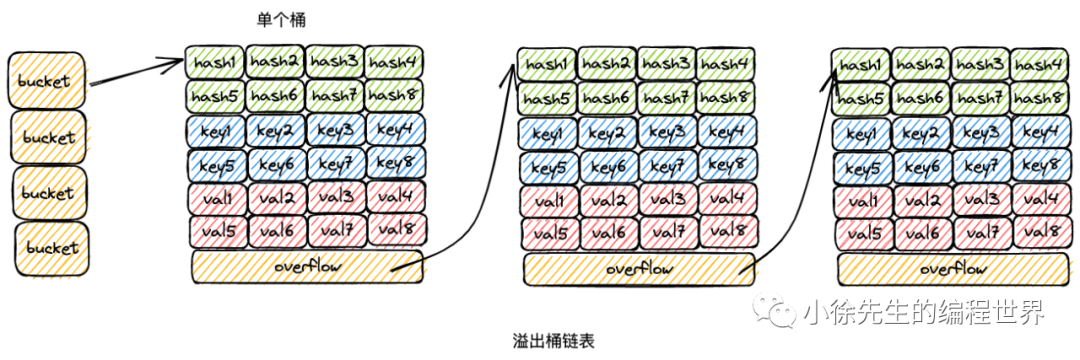
When map solves the hash/bucket conflict problem, it actually combines the two ideas of zipper method and open addressing method. Take the insertion and writing process of map as an example to elaborate on the idea: a> a> (5) If the end of the linked list is traversed and no vacancy is found, based on the zipper method, a new bucket will be added to the end of the bucket linked list and the key-value pair will be inserted. (4) If all 8 positions of the bucket are occupied, find the next bucket based on the overflow bucket pointer of the bucket, and repeat step (3); (3) When the key hits a bucket, first according to the open addressing method, empty slots are found among the 8 positions of the bucket for insertion; (2) Each bucket It is fixed that 8 key-value pairs can be stored;
(1) Each bucket in the bucket array is strictly a one-way bucket linked list, with buckets as nodes for series connection;
There are two expansion mechanisms for Map, one is equal expansion and the other is incremental expansion.
Equal expansion:
Due to the constant put and delete keys in the map, there may be many intermittent vacancies in the bucket, and these vacancies will cause the connected bmap to overflow. The bucket is very long, resulting in long scan times. This kind of expansion is actually a kind of sorting, which puts the data in the later position to the front. In this case, the elements will be rearranged, but the buckets will not be swapped.
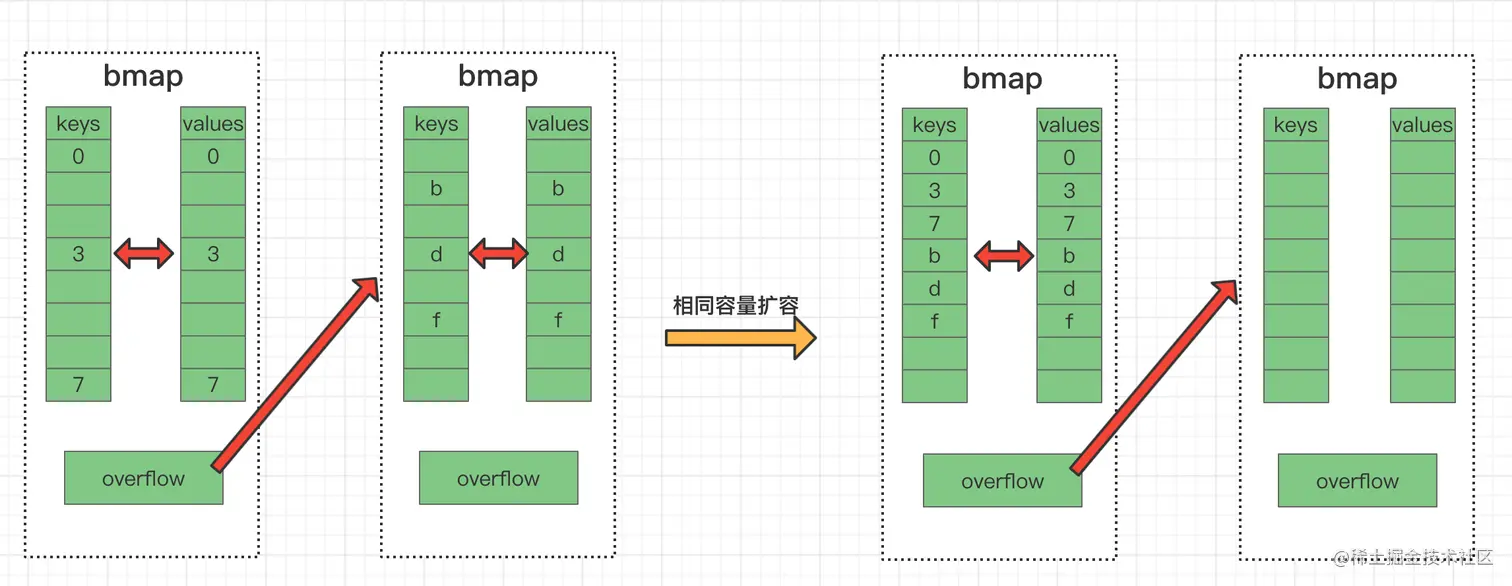
Incremental expansion:
This 2-fold expansion is because the current bucket array is indeed not enough. When this expansion occurs, the elements will be rearranged and may Bucket migration occurs.
As shown in the figure, B=2 before expansion and B=3 after expansion. Assume that the last three digits of the hash value of an element key are 101. From the above introduction, it can be seen that during expansion Before, the last two digits of the hash value determine the bucket number, that is, 01, so the element is in bucket No. 1. After the expansion occurs, the last three digits of the hash value determine the bucket number, that is, 101, so the elements will be migrated to bucket 5.
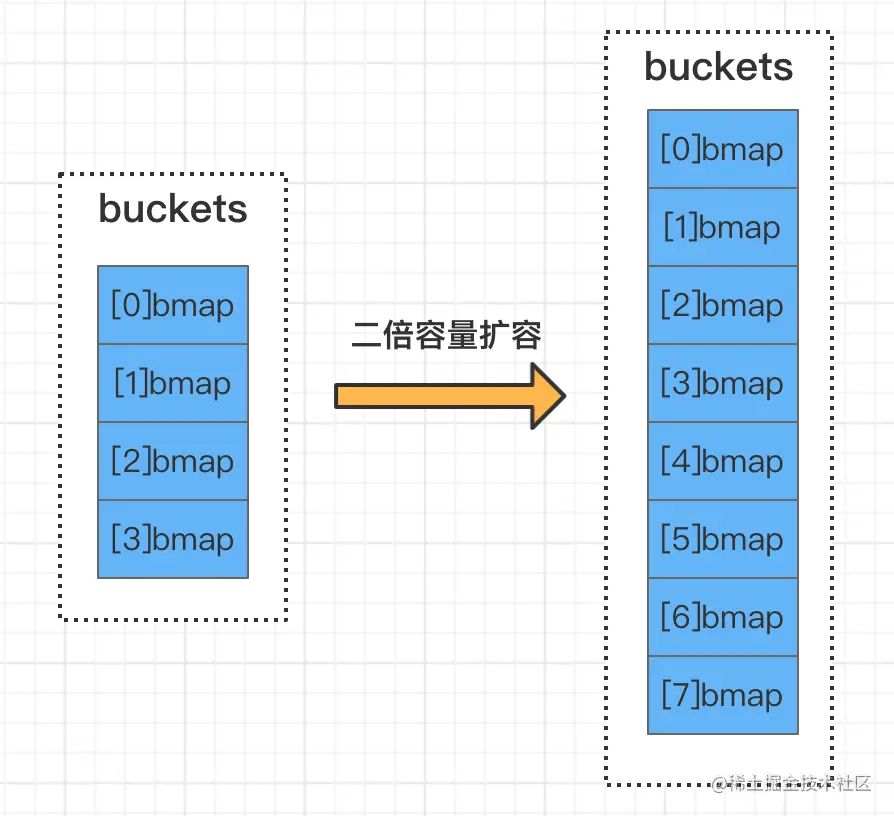
There are two conditions for expansion:
One is the loading factor (the number of key-value pairs in the map/the number of buckets in the map 2^B)>6.5 That is, each When there are more than 6.5 elements in the bucket, it means that the current capacity is insufficient, and incremental expansion occurs
. The second is when there are too many overflow buckets, and the number of buckets is less than 2^15th power. When the number of overflow buckets is greater than or equal to the number of buckets, it is considered that there are too many overflow buckets. When the total number of buckets is greater than or equal to the 2^15 power, when the number of overflow buckets is greater than or equal to the 2^15 power, it is considered that there are too many overflow buckets. .
Map is not a concurrency-safe data structure. If there is concurrent reading and writing, a fatal error will be thrown. Concurrent reading and writing will cause a fatal error, which is a more serious error than panic and cannot be captured using the recover operation.
3. Let’s talk about the bottom layer of channel in go
CSP model
Golang borrows some concepts from the CSP model to provide theoretical support for concurrency. In fact, from a practical point of view, the go language does not fully realize all the features of the CSP model. The theory just borrows the two concepts of process and channel.
Data sharing is realized between each entity through channel communication.
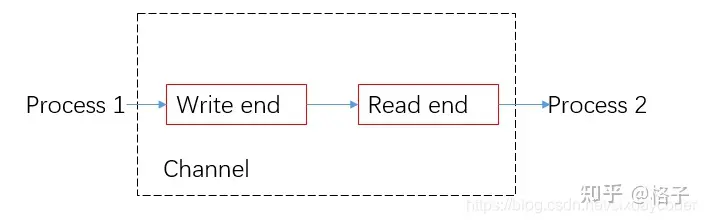
Channel is a pipeline used to implement communication between multiple goroutines in golang. Its bottom layer is a structure called hchan.
type hchan struct {
//channel分为无缓冲和有缓冲两种。
//对于有缓冲的channel存储数据,借助的是如下循环数组的结构
qcount uint // 循环数组中的元素数量
dataqsiz uint // 循环数组的长度
buf unsafe.Pointer // 指向底层循环数组的指针
elemsize uint16 //能够收发元素的大小
closed uint32 //channel是否关闭的标志
elemtype *_type //channel中的元素类型
//有缓冲channel内的缓冲数组会被作为一个“环型”来使用。
//当下标超过数组容量后会回到第一个位置,所以需要有两个字段记录当前读和写的下标位置
sendx uint // 下一次发送数据的下标位置
recvx uint // 下一次读取数据的下标位置
//当循环数组中没有数据时,收到了接收请求,那么接收数据的变量地址将会写入读等待队列
//当循环数组中数据已满时,收到了发送请求,那么发送数据的变量地址将写入写等待队列
recvq waitq // 读等待队列
sendq waitq // 写等待队列
lock mutex //互斥锁,保证读写channel时不存在并发竞争问题
}
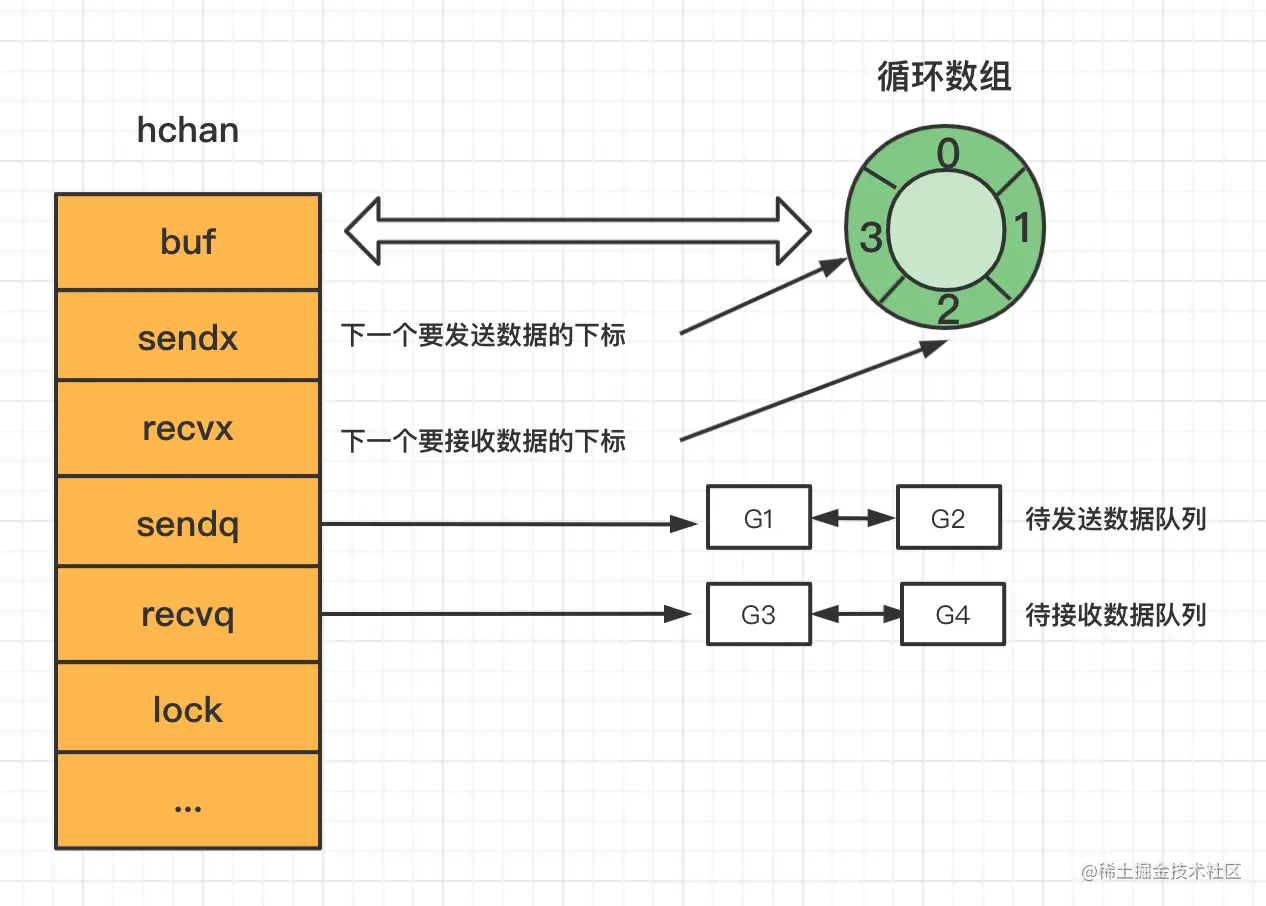
There are four main components of the hchan structure:
Circular linked list for caching data. =>buf.
The index that needs to send data / the index that needs to receive data => sendx and recvx.
Received coroutine queue / Sent coroutine queue => recvq / sendq
Mutex lock => lock
sendq and recvq store the list of Goroutines blocked by the current Channel due to insufficient buffer space. These waiting queues are represented by a doubly linked list runtime.waitq. All elements in the linked list are runtime.sudog structures:
type waitq struct {
first *sudog
last *sudog
}
type sudog struct {
g *g
next *sudog
prev *sudog
elem unsafe.Pointer
c *hchan
...
}
runtime.sudog represents a Goroutine in the waiting list. This structure stores two pointers pointing to the front and rear runtime.sudog respectively to form a linked list.
Doubly linked list, including a head node and a tail node
Each node is a sudog structure variable, which records which coroutine is waiting and what it is waiting for. Which channel is it and where is the data waiting to be sent/received
Creation strategy
If it is an unbuffered channel, memory will be allocated directly to hchan
If it is a buffered channel, and the element does not contain a pointer , then a continuous address will be allocated to hchan and the underlying array
If it is a buffered channel and the element contains a pointer, then hchan and the underlying array will be allocated separate addresses
Send data to the channel
If there is a receiver goroutine in the channel's read waiting queue
send the data directly to the first waiting goroutine. Wake up the receiving goroutine
If there is no receiver goroutine in the channel's read waiting queue
If the loop array buf is not full, the data will be sent to the loop array buf The end of the queue
If the loop array buf is full, the blocking sending process will be followed at this time, the current goroutine will be added to the write waiting queue, and suspended to wait for wake-up
Receive data into the channel
If there is a sender goroutine in the write waiting queue of the channel
If it is an unbuffered channel, directly send it from the first sender goroutine Copy the data to the receiving variable, wake up the sending goroutine
If there is a buffer channel (full), copy the head element of the circular array buf to the receiving variable, and copy the first sender goroutine Copy the data to the end of the buf loop array and wake up the sent goroutine
When sending data to the channel, buf will be locked first, then the data will be copied to buf, then sendx++ will be performed, and then the lock on buf will be released
When receiving data from the channel, the buf will be locked first, then the data in the buf will be copied and assigned to the variable, and then recvx++ will release the lock
4. Concurrent programming in go
Mutex
In Go, the most commonly used method to restrict access to public resources by concurrent programs is the mutex lock (sync.mutex).
type Mutex struct {
state int32
sema uint32
}
There are two common methods of sync.mutex:
Mutex.lock() is used to acquire the lock
Mutex.Unlock() is used to release it lock
Mysql
1) Three major paradigms of databases
The three major database paradigms refer to the three levels of normalization that need to be followed in order to avoid data inconsistency and data inconsistency in relational database design. It reduces data and data inconsistencies and improves the data integrity and reliability of the database.
First normal form (1NF) non-duplicate columns (atomicity) means that each column of the database table is an indivisible basic data item. All fields should be atomic, that is, each column of the database table is an indivisible atomic data item, and cannot be non-atomic data items such as sets, arrays, records, etc. That is, when an attribute in an entity has multiple values, it must be split into different attributes.
Second normal form (2NF) non-primary key attributes are completely dependent on the primary key, that is, non-primary attributes are completely dependent on the primary key
Third normal form (3NF) attributes do not depend on other non-primary attributes, ensuring that there is no supply dependency between non-primary key attributes.
2) Comparison of the advantages and disadvantages of relational databases and non-relational databases, and application scenarios
The most typical data structure of a relational database is a table, which is a data organization composed of two-dimensional tables and the relationships between them.

Advantages: 1. Easy to maintain: all use table structure and consistent format; 2. Easy to use: SQL language is universal and can be used for complex queries;
3. Complex operations: Supports SQL and can be used for very complex queries between one table and multiple tables.
Disadvantages: 1. Poor reading and writing performance, especially high-efficiency reading and writing of massive data;
2. Fixed The table structure is slightly less flexible; 3. High concurrent reading and writing requirements. For traditional relational databases, hard disk I/O is a big bottleneck.
Scenario:
Usage scenario:
1) Data that requires complex processing;
2) The amount of data is not particularly large;
3) Data with high security requirements;
4) Data with a single data format;
Non-relational database is not strictly a database. It should be a collection of structured data storage methods, which can be documents or key-value pairs.

Advantages: 1. Flexible format: the format of stored data can be key, value form, document form, picture form, etc., document form, picture form, etc., flexible to use , has a wide range of application scenarios, while relational databases only support basic types.
2. Fast speed: NoSQL can use hard disk or random access memory as the carrier, while relational database can only use hard disk; 3. High scalability;
4. Low cost: NoSQL database is simple to deploy and is basically open source software.
Disadvantages: 1. No SQL support is provided, and the cost of learning and use is high; 2. No transaction processing;
3 , The data structure is relatively complex, and it is slightly lacking in complex queries.
Usage scenarios:
1) Mass data storage;
2) Multi-format data storage;
3) Data storage that requires fast query speed;
3) The differences and application scenarios between MySQL, MongoDB and Redis
MySQL (relational database), MongoDB and Redis are common NoSQL databases
MySQL
is a relational database that can store structured data and support complex operations such as cross-table joint queries. It is especially suitable for scenarios such as transaction processing that require strict data security. In the internship project, MySQL is mainly used to store main business data, such as user information, order information, product information, etc. Specifically include:
Store structured data;
Support SQL statements, and perform flexible data statistics and analysis through various SQL aggregate functions; < a i=4> supports complex operations such as cross-table joint queries; supports transactions and MVCC features.
MongoDB
is an open source document database, also known as a non-relational database (NoSQL), that can easily handle semi-structured or unstructured data. In the internship project, MongoDB may be used to store log data, browser behavior data, etc. It has the following characteristics: Document-oriented design, easy to store and retrieve semi-structured and unstructured data; Inserting records is faster than traditional relational databases; It can act as a key-value pair store and can quickly Store small records, similar to Redis; Support flexible high-reliability solutions such as data sharding, replica sets, and automatic failover.
Redis
is an open source in-memory database, also known as cache and key-value store. In the internship project, Redis
is used to cache popular products, user information, etc. It has the following characteristics: In-memory database with extremely fast read and write speeds; Mainly used as a cache system or distributed lock; Supports multiple formats such as text and binary data;
Has advanced features such as data expiration mechanism ; Supports a variety of data structures, such as strings, hash tables, lists, sets and ordered sets, etc. Form a systematic application
In summary, the three mainstream databases each have their own applicable scenarios and characteristics. In actual use, we can combine them to form a complete systematic application according to specific business needs. For example, basic data such as user accounts and permissions are managed through relational databases such as MySQL, MongoDB is used to store large amounts of semi-structured data, and cache databases such as Redis are used to speed up access, thereby improving the entire system. performance and stability.
5) How to optimize the database
Expand from the perspectives of fields, transactions, indexes, avoiding full table queries, etc.
Field optimization:
Choose the appropriate data type: Choose the most appropriate data type to store data to reduce storage space overhead. Do not use overly large data types, such as INT instead of
BIGINT, unless necessary.Avoid using too many NULL values: NULL values will occupy additional storage space, so try to avoid too many NULL values.
Use integers as primary keys: Integer-type primary keys are more efficient than string-type primary keys because integers are faster to compare.
Vertically split table: Split a large table into multiple small tables, containing only necessary fields to reduce unnecessary data reading.
Transaction optimization:
Minimize the scope of the transaction: Reduce the scope of the transaction to the minimum and only cover necessary operations to reduce lock competition and transaction conflicts.
Use batch operations: Use batch insert, update, or delete operations instead of one-by-one operations to reduce transaction overhead.
Reasonable use of transaction isolation levels: Choose the appropriate transaction isolation level according to the needs of the application to avoid performance degradation caused by excessively high isolation levels.
Index optimization:
Choose appropriate indexes: Choose appropriate indexes based on the needs of the query and do not over-index the table. Composite indexes can reduce the number of indexes.
Rebuild the index regularly: Rebuild or optimize the index of the table regularly to maintain the performance of the index.
Use covering index: Try to use covering index, which can reduce the number of disk accesses by the database and improve query performance.
Evacuation Complete List 查询:
Use appropriate WHERE clauses: Make sure every query includes an appropriate WHERE clause to reduce unnecessary data retrieval.
Use paging: For large data sets, use paging to limit the amount of data returned by each query and avoid querying the entire table at once.
Cache query results: For situations where the same query is executed frequently, you can consider using cache to store query results and reduce database access.
Use index coverage: When all the fields required for the query are already included in the index, you can avoid a full table scan and improve the query speed.
6) The difference between JOIN and UNION
First explain JOIN:
A) Inner join: join, inner join
B) Outer join: left join, left outerjoin, right join, right outer join, union
C) Cross join: cross join
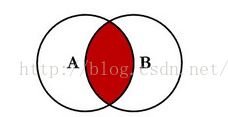
Inner join:
Application scenario:
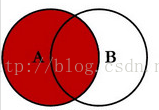
Left join:
Application scenario:
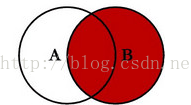
Right connection:
Application scenario:
join (join query) and union (joint query)
7) How to perform multi-table query
8) Why do we need to divide databases and tables? How to divide databases and tables?
9) The difference between left union and inner union
10) Principle of master-slave replication
Why is master-slave replication needed, what is the principle, and how to implement master-slave replication
11) The execution process of a SQL statement, how SELECT is executed, and how UPDATE is executed
Connector - Cache - Analyzer - Optimizer - Executor
12) What is an index, why should we use an index, and what are the advantages and disadvantages of an index?
13) How the index is implemented/the data structure used by the index, and the differences between them
B+ tree, Hash, B tree
The difference between B+ tree and B tree
The difference between B+ tree and Hash
Disadvantages of B+ tree indexes
14) Index type and index type
FULLTEXT,BTREE,HASH等
Primary key index, composite index, unique index, etc.
15) Clustered index and non-clustered index
16) What is a table query? Is it necessary to query a non-clustered index?
17) Index application scenarios
18) When will the index become invalid?
19) The difference between unique index and primary key index
20) Given a SQL, determine whether to use joint index
21) Leftmost prefix matching rule
22) The execution of sql statements in Mysql is too slow, what is the reason, how to solve it, and what command to use to check it
23) How to check whether the index is applied
24) Why does adding an index make it faster?
25) What locks does the MySQL database have?
26) Shared lock, update lock, exclusive lock
27) What is deadlock, how to solve deadlock, and how to avoid deadlock?
28) Database row locks and table locks
29) What are dirty reads, non-repeatable reads, and phantom reads?
30) Transaction isolation level
31) The four major characteristics of transactions (ACID), how MySQL implements ACID
32) MySQL storage engine
33)MVCC
microservices
1. What are microservices?
What is SOA (Service Oriented)?
Splitting services into smaller parts has fewer bugs, is easy to test and maintain, and is easy to expand.
Single responsibility, a service only does one thing.
Microservices is a practice of SOA. It is built around business functions. The service focuses on a single business and uses a lightweight communication mechanism between services, which can fully Automated independent deployment using different programming languages and data storage technologies.
Advantages:
Decoupled - Services in the system are largely decoupled. As a result, the entire application can be easily built, modified, and scaled
Componentized – Microservices are treated as independent components and business functionality can be easily replaced and upgraded – Microservices are very Simplicity, focus on one feature
Autonomy - developers and teams can work independently of each other, increasing speed Continuous Delivery - system automation of software creation, testing and approval, allowing for frequent software releases
Responsibility - Microservices do not focus on the application as a project. Instead, they treat applications as products they are responsible for
Decentralized Governance - Focus on using the right tool for the right job. This means there is no standardized pattern or any technical pattern. Developers are free to choose the most useful tools to solve their problems
Agile – Microservices enable agile development. Any new features can be developed quickly and discarded again
2. The difference between microservices and monoliths
Microservice architecture and monolithic architecture are two different software architecture patterns. Microservice architecture is usually more suitable for large, complex applications, while monolithic architecture may be more suitable for small projects or rapid prototype development. They differ greatly in how they design and organize their applications:
- Architecture:
Monolithic Architecture: A monolithic application packages all functions and components into a single application.
Microservices Architecture: Microservices architecture decomposes applications into small, independent services, each service is responsible for a clearly defined function. These services can be developed, deployed, and scaled independently, often using different databases or storage. - Component isolation:
Monolithic Architecture: In a monolithic application, different functional modules are usually tightly coupled, and they share the same code base and database connection. and resources. Such tight coupling means that modifying one function may affect other functions.
Microservices Architecture: Microservices are independent components that are loosely coupled to each other and can be developed, tested, deployed and expanded independently. Each microservice typically has its own data store, which increases isolation between components. - Scalability:
Monolithic Architecture: Monolithic applications usually have poor scalability because instances of the entire application need to be added to cope with high loads. This can lead to wasted resources and performance issues.
Microservices Architecture: Microservices architecture can more accurately scale individual services to cope with high loads, thus improving resource utilization and performance. - Development and deployment:
Monolithic Architecture: Development, testing, and deployment of monolithic applications are relatively simple because they are a single code base and deployment unit.
Microservices Architecture: The development and deployment of microservices applications is more complicated because multiple independent services need to be coordinated. However, this also provides greater flexibility and independence. - Maintainability:
Monolithic Architecture: Maintaining a monolithic application can be complicated because all functionality is in one code base. Larger monolithic applications can become difficult to maintain and scale.
Microservices Architecture: The independence and isolation of microservices make maintenance easier, because problems can usually be localized to specific services, and it is easier to replace or upgrade individual services .
3. Compared with RPC and HTTP, why do microservices choose RPC instead of HTTP?
- Performance: RPCs are generally more lightweight than HTTP because they can use more compact binary protocols such as ProtocolBuffers (ProtoBuf) or MessagePack, rather than text protocols like HTTP. This reduces data serialization and deserialization overhead and reduces network traffic, thereby improving performance.
- Better cross-language support: RPC frameworks are usually designed to support multiple programming languages, allowing different microservices to be implemented using different programming languages without much extra work. This helps teams choose the language that best suits their needs across different technology stacks while maintaining communication between microservices.
- Richer service discovery and load balancing: Some RPC frameworks provide built-in service discovery and load balancing mechanisms, making dynamic registration and discovery of microservices easier. This can improve the resiliency and scalability of microservices architectures.
- Strict type system: Some RPC frameworks use strong type definitions that can detect type errors at compile time, thus reducing the possibility of runtime errors. This helps improve code stability and maintainability.
- Customized performance optimization: RPC frameworks often allow you to better control the behavior of communication, including connection pooling, timeout handling, concurrency control, etc. This allows you to optimize performance based on your specific needs.
Article references:
Go interview questions (3): The implementation principle of map
WeChat public account Mr. Xiao Xu’s programming world
Go interview questions (5): Illustration of the underlying principles of Golang Channel
Go underlying principles - the underlying implementation principles of channels?
Introduction to Go CSP model
In-depth explanation of the underlying implementation principle of Go's channel [Illustration]