With the increasing demand for applications brought by large models, many well-known overseas vector database startups have recently received good news about financing. With the advent of the AI era, the vector database market has huge space. It is currently in the 0-1 stage. It is predicted that by 2030, the global vector database market size is expected to reach 50 billion US dollars, and the domestic vector database market size is expected to exceed 60 billion yuan.
Today we will briefly talk about what a vector database is!
Table of contents
1. Understand the vector database
2. Comparison with other mainstream vector databases
3. Application scenarios of vector database
1. Understand the vector database
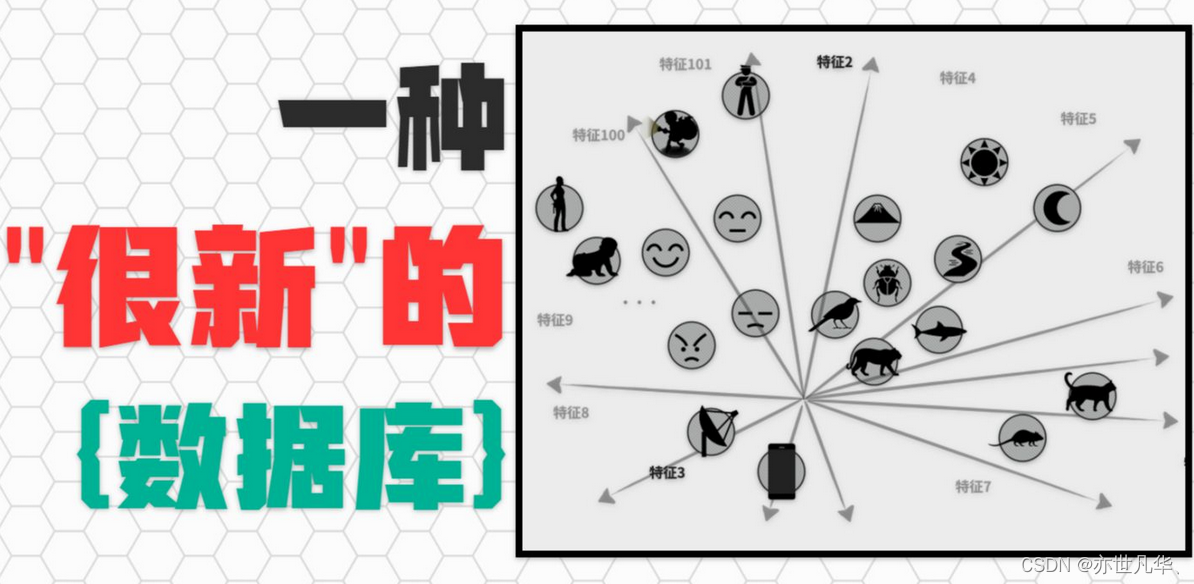
What is a vector database?: Before we discuss the vector database, we must first understand the vector database. So what is the vector database? Simply put, a vector database is a database specifically used to process and query vector data. Unlike traditional databases that organize and store data in tabular form, vector databases use multi-dimensional numerical arrays to process and store data. Its main goal is to support efficient vector similarity searches and queries.
Therefore, vector databases are widely used in areas such as face recognition, image search, video analysis, language recognition, and recommendation systems. It can achieve efficient data retrieval and analysis, and has a "memory" function, which cannot be achieved by traditional databases. If the large language model has brought us a little glory of the future world, then the vector database is the door to the future world. The key!
Next, let’s take the Amazon Cloud Technology Vector Engine Amazon OpenSearch Serverless as an example to start our topic today:
Amazon Cloud Technology announced the withdrawal of the preview version of the Amazon OpenSearch Serverless vector engine. The vector engine provides a simple, scalable, and high-performance similarity search function in Amazon OpenSearch Serverless, allowing users to easily build modern Machine learning (ML)-enhanced search experiences and generative AI applications do not require the management of the underlying vector database infrastructure. The vector engine built on Amazon OpenSearch Serverless is naturally robust, and users using vector databases do not need to worry about the selection of back-end infrastructure. , tuning and expansion issues, because when large language models process text data, they often convert text into high-dimensional vectors, and these vectors are large in size. Traditional database systems are difficult to store and query efficiently. Vector databases are specially designed for storing and querying vector data, and can provide efficient data storage and retrieval functions. Its official website:Jump link:

Amazon Cloud Vector Engine provides separate computing resources for indexing and workload search, allowing users to seamlessly obtain updates in real time and delete vectors, while ensuring that user query performance is not affected at all. Through the efficient vector calculation and query functions provided by the vector database, the training and inference process of the model can be accelerated, and the training speed and inference efficiency of the model can be improved. The vector database also provides vector The ability of similarity calculation can support more intelligent text matching and semantic search, improving user experience. Jump link:

In addition to the above-mentioned "brain function" of the Amazon Cloud Technology vector engine for large language models, the vector engine supports the same Open Search open source suite API, and by integrating LangChain Amazon Bedrock and Amazon SageMaker users can easily integrate their preferred machine learning and AI systems Integrated with the vector database engine, the above functions are only the preview version of the vector engine, which already shows the "robustness" of its performance and its indispensable role in large language models.
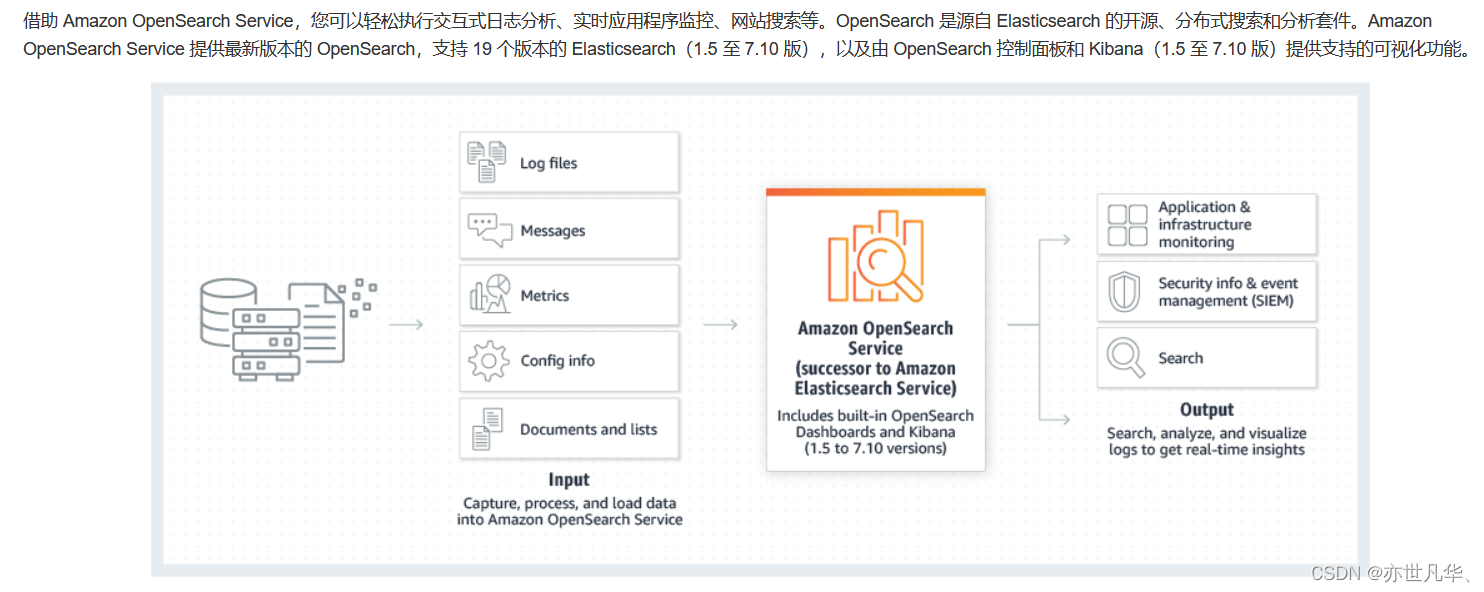
In the next few years, the official version of the Amazon Cloud Technology Vector Engine may be released soon. Let us wait and see how powerful it will be in optimizing the performance and memory usage of vector graphics, including improving caching and merging. !
2. Comparison with other mainstream vector databases
There are many mainstream vector database suppliers in China, and they have their own advantages in different application scenarios and technical features. Next, we will compare these mainstream vector databases to help you understand their characteristics, functions, and applicability, thereby providing you with a reference when choosing a suitable vector database.
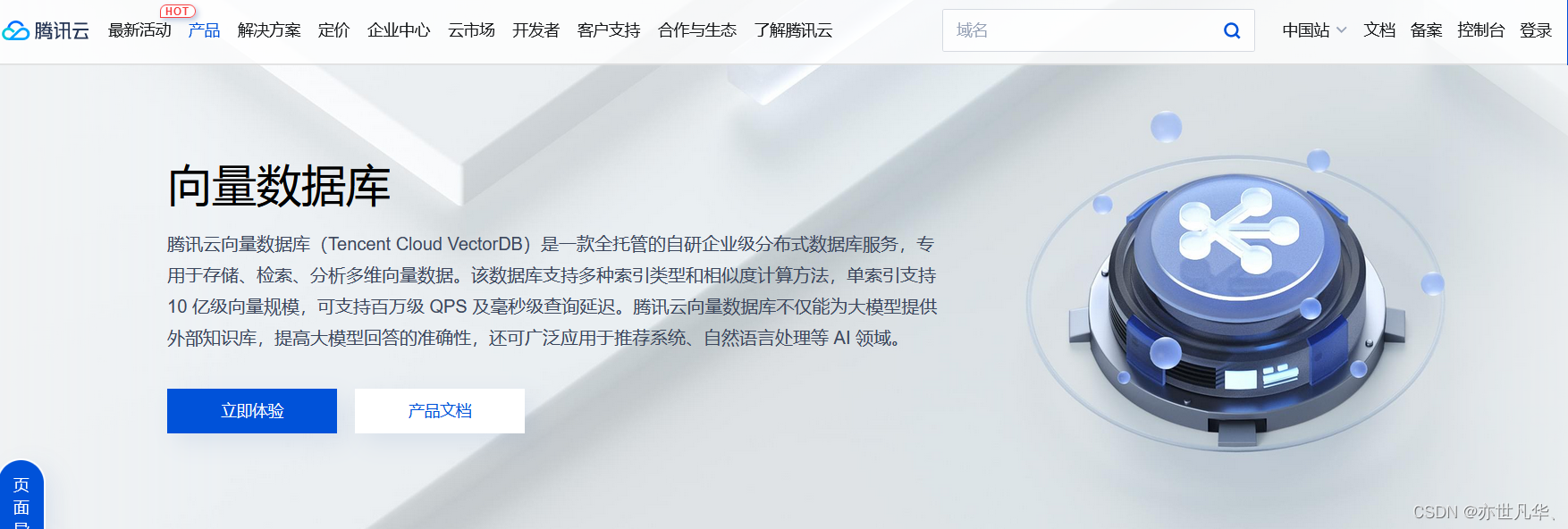
Tencent Cloud Vector DB: Tencent Cloud officially released the AI native vector database, which can be widely used in scenarios such as training of large models, inference, and knowledge base supplementation. It is the first vector database in China that provides full life cycle AI from the access layer, computing layer to storage layer. Tencent Cloud Vector Database supports up to 1 billion vector retrieval scale, with latency controlled at the millisecond level. Compared with traditional stand-alone plug-in databases, the retrieval scale is increased by 10 times, and it also has a peak query capability of one million levels per second. Jump link:
Elasticsearch: A vector engine independently developed by Baidu’s Elasticsearch team, dedicated to storing, retrieving, and analyzing multi-dimensional vector data. It supports multiple index types and similarity calculation methods, supports the construction of billion-level vector scale, and achieves millisecond-level latency. It can not only provide external knowledge base capabilities for large models such as Wenxin and improve the accuracy and timeliness of large model answers, but can also be widely used in recommendation systems, question and answer systems, semantic retrieval, intelligent customer service and other fields. Jump link:

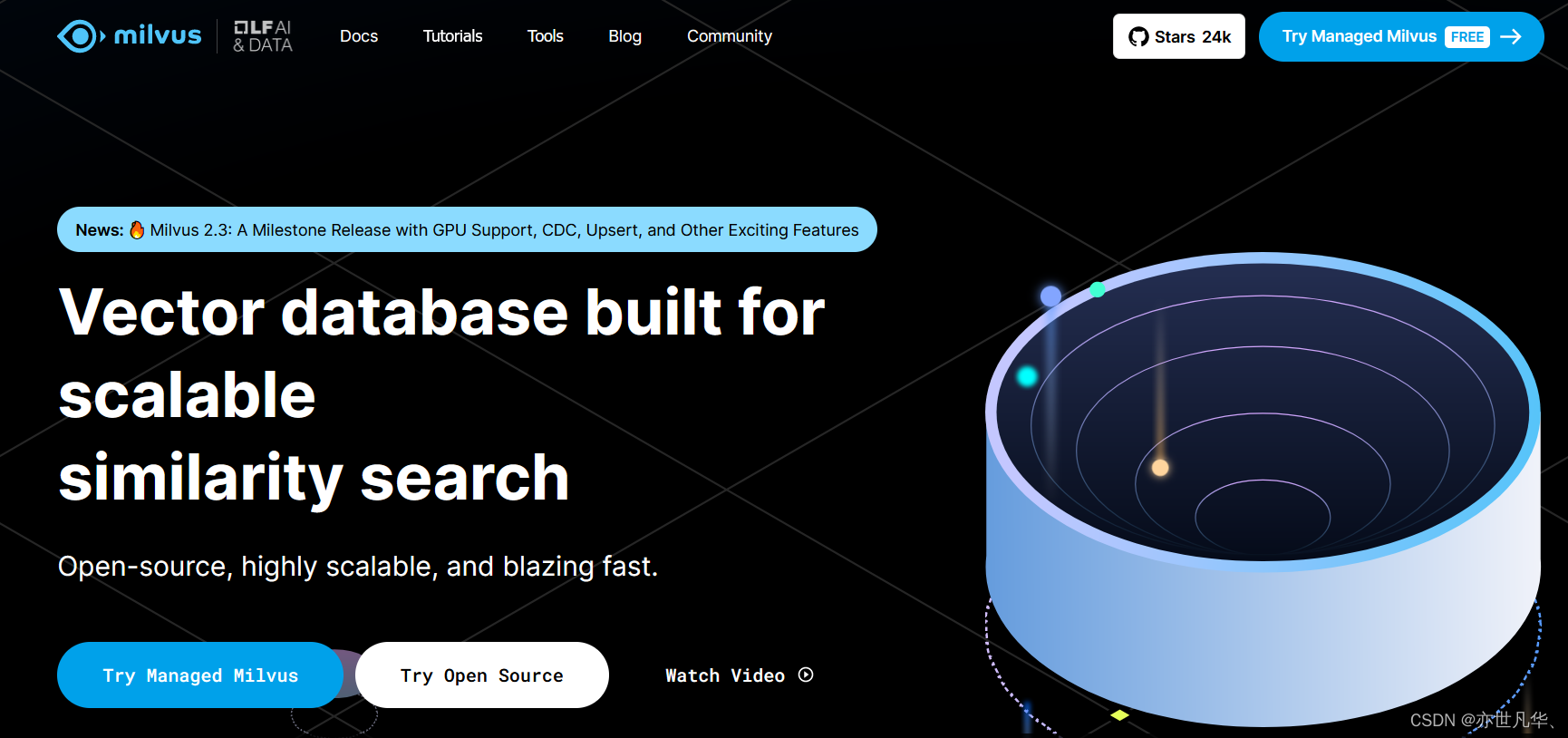
Milvus: An open source vector database engine launched by Zilliz, designed to support large-scale vector similarity search and similarity calculation. It provides efficient vector indexing and retrieval functions and is suitable for various artificial intelligence, data mining and big data analysis applications. It is built based on vector search libraries such as FAISS, Annoy, HNSW, etc., and its core is to solve the problem of dense vector similarity retrieval. Jump link
There are of course other popular vector databases, includingFaiss, Annoy andPinecone, etc. are briefly introduced as follows:
Faiss: An efficient vector search and clustering tool library developed by Facebook AI Research. Large-scale data can be processed and efficient calculations can be performed on CPU and GPU. The main advantage is that its search speed is very fast, which makes it very advantageous when dealing with large-scale data. The disadvantage is that it does not support online data updates, which means that if we need to add or delete data, we may need to rebuild the entire index.
Annoy: An efficient vector search library developed by Spotify, which can store a large number of vectors in memory and perform vector searches quickly. The main advantage is that it is very memory efficient, which makes it very advantageous when processing large-scale data. The disadvantage is that it does not support online data updates, which means that if we need to add or delete data, we may need to rebuild the entire index.
Pinecone: It is a fully managed vector search service that can handle large-scale data and perform efficient calculations in the cloud. The main advantage is its ease of use. Users do not need to care about the underlying implementation details and only need to perform vector searches through the API. The disadvantage is that it is a paid service, and the cost may be higher for some small projects or individual users.
There are many popular vector databases on the market. Each of these databases has its own advantages and disadvantages. We need to choose the most suitable vector database according to our specific needs and application scenarios.
3. Application scenarios of vector database
Vector database has a wide range of application scenarios in different fields. With the rapid development of big data and artificial intelligence, vectorized representation and processing of data have become increasingly important. As an innovative database technology, vector database shows great potential in various fields with its efficient vector indexing and query capabilities.

Taking image recognition as an example, the application of vector databases in image search and similarity matching. By converting images into vector representations and leveraging the efficient indexing and query capabilities of vector databases, we can achieve fast and accurate image searches and find images similar to the target image from a massive image library.

4. Personal summary
Which type of database to choose depends on our specific needs and application scenarios. Whether it is a relational database, a non-relational database, or a vector database, they are important tools in our data processing toolbox, and we need to choose the most suitable tool according to the actual situation.
The reason why we choose the current vector database is mainly because it has the following main features:
Efficient vector indexing and querying:
Vector databases can efficiently index and query vector data, making it possible to quickly find similar vectors in large-scale data sets. This is very useful for similarity matching and search tasks in areas such as image recognition and text processing.
Supports complex data relationships:
Vector databases can process and analyze complex data relationships, including multi-dimensional similarity calculations and queries. This allows us to better understand the relationship between users and items in recommendation systems, advertising recommendations and other fields, and provide more accurate recommendations and personalized services.
For multiple areas :
Vector databases have broad application potential in many fields, such as image recognition, natural language processing, recommendation systems, etc. By vectorizing data from different fields and utilizing the functions of vector databases, efficient data processing and analysis can be achieved.
Although vector databases have many advantages and potential, they also need to be weighed against some disadvantages and challenges compared to traditional databases in practical applications:
Storage and computational overhead:
Vector databases usually consume large storage and computing resources to store and process vector data. Especially when processing large-scale data sets, higher hardware costs and more complex system architecture may be required to support it.
Challenges of vectorized representation:
Vectorizing raw data is a prerequisite for using vector databases, but sometimes the vectorization process may face certain challenges. Issues such as how to choose appropriate vectorization methods and parameters, and how to handle high-dimensional and sparse data need to be carefully considered and solved.
Complexity of updates and maintenance:
If the data set is frequently updated or changed, the vector database needs to be able to handle new and modified data in a timely manner. This may involve index updates and maintenance, and you need to consider how to balance the relationship between data updates and query performance.
Vector databases also need to be carefully evaluated and selected for specific application scenarios to ensure the best performance and effects. If you are also interested in vector databases, welcome to try it!