1. Read data in text format

import pandas as pd
df = pd.read_csv('ex1.csv')
print(df)
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
If the text content is like this (without columns):

df = pd.read_csv('ex2.csv')
print(df)
1 2 3 4 hello (equivalent to a wrong interpretation)
0 5 6 7 8 world
1 9 10 11 12 foo
df = pd.read_csv('ex2.csv', header=None)
print(df)
0 1 2 3 4
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
df = pd.read_csv('ex2.csv', names=['a', 'b', 'c', 'd', 'message'])
print(df)
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
You can force the fourth column to be specified as index:
df = pd.read_csv('ex2.csv', names=['a', 'b', 'c', 'd', 'message'], index_col='message')
print(df)
print(df.index.name)
a b c d
message
hello 1 2 3 4
world 5 6 7 8
foo 9 10 11 12
message
For a csv like this:

df = pd.read_csv('csv_mindex.csv', index_col=['key1', 'key2'])
print(df)
value1 value2
key1 key2
one a 1 2
b 3 4
c 5 6
d 7 8
two a 9 10
b 11 12
c 13 14
d 15 16
For text files:
df = list(open('ex3.txt'))
print(df)
[' A B C\n',
'aaa -0.264438 -1.026059 -0.619500\n',
'bbb 0.927272 0.302904 -0.032399\n',
'ccc -0.264273 -0.386314 -0.217601\n',
'ddd -0.871858 -0.348382 1.100491\n']
Use read_table() and regular expressions to interpret:
Regular expression explanation:
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143193331387014ccd1040c814dee8b2164bb4f064cff000
df = pd.read_table('ex3.txt', sep=r'\s+') #At least one space
print(df)
print(df.columns)
print(df.index)
A B C
aaa -0.264438 -1.026059 -0.619500
bbb 0.927272 0.302904 -0.032399
ccc -0.264273 -0.386314 -0.217601
ddd -0.871858 -0.348382 1.100491
Index(['A', 'B', 'C'], dtype='object')
Index(['aaa', 'bbb', 'ccc', 'ddd'], dtype='object')
For a csv like this:
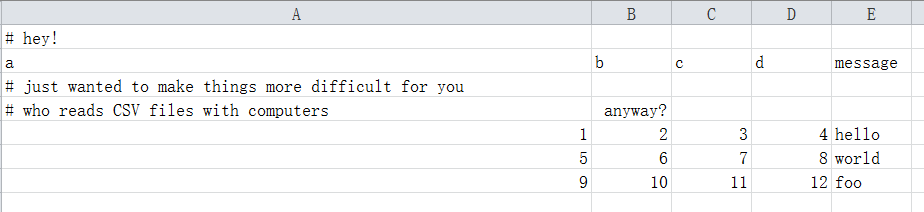
We don't need the first, third, and fourth lines, so it's optional to skip:
df = pd.read_csv('ex4.csv', skiprows=[0, 2, 3]) # skip rows 1, 3, 4
print(df)
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
For csv with missing values:

df = pd.read_csv('ex5.csv')
print(df)
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
2. Read the text file block by block
For files with large amounts of data:
Select only the first few rows:
df = pd.read_csv('ex6.csv', nrows=5) #read the first 5 rows
print(df)
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
Read block by block:
from pandas import DataFrame, Series
import pandas as pd
chunkers = pd.read_csv('ex6.csv', chunksize=1000)
all = Series ([])
for piece in chunkers: #chunker is equivalent to an iterable object, each piece has 1000 sets of data (the last set is less than 1000)
tot = tot.add(piece['key'].value_counts(), fill_value=0) #Count and sort the value of the key
to = to.sort_values(ascending=False)
print (all [: 10])
E 368.0
X 364.0
L 346.0
O 343.0
Q 340.0
M 338.0
J 337.0
F 335.0
K 334.0
H 330.0
dtype: float64
3. Write data out to text format
df = pd.read_csv('ex5.csv')
print(df)
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
df.to_csv('out.csv')
A CSV file is generated after execution:

df.to_csv('out.csv', na_rep='NULL') #Replace empty values with NULL
Of course, it is also possible not to write labels such as row and column:
df.to_csv('out.csv', index=False, header=False)

Save the Series as a csv file:
dates = pd.date_range('1/1/2000', periods=7)
ts = Series(np.arange(7), index=dates)
print(ts)
ts.to_csv('tseries.csv')

When reading, if you want to read into a Series, you need to do some work: no header row, the first column is used as an index
But there is an easier way, from_csv
obj = Series.from_csv('tseries.csv', parse_dates=True)
print(obj)
2000-01-01 0
2000-01-02 1
2000-01-03 2
2000-01-04 3
2000-01-05 4
2000-01-06 5
2000-01-07 6