1. Data CSV file access
CSV file
CSV (Comma-Separated Value, comma-separated value)
CSV is a common file format used to store bulk data
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
- frame: file, string or generator, can be a .gz or .bz2 compressed file
- array: the array stored in the file
- fmt: the format of the written file, for example: %d %.2f %.18e
- delimiter: delimiter string, the default is any space
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
- frame: file, string or generator, can make .gz or .bz2 compressed files
- dtype: data type, optional
- delimiter: delimiter string, the default is any space
- unpack: If True, read attributes will be written to different variables
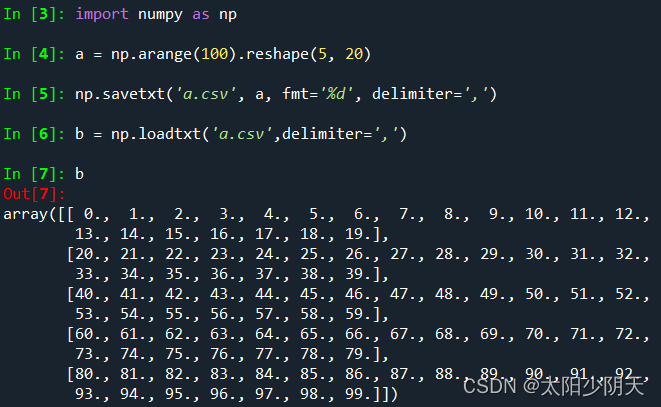
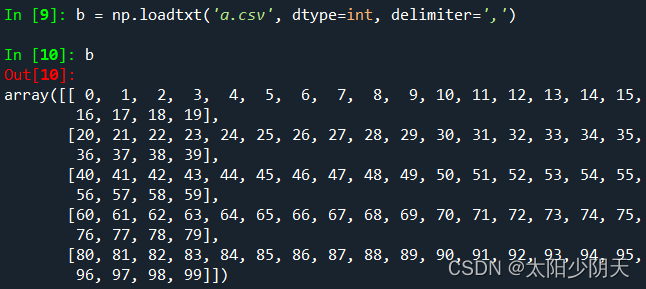
Limitations of CSV files
CSV can only efficiently store 1D and 2D arrays
np.savetxt() np.loadtxt() can only effectively access one-dimensional and two-dimensional arrays
2. Access to multidimensional data
How to access any dimension data?
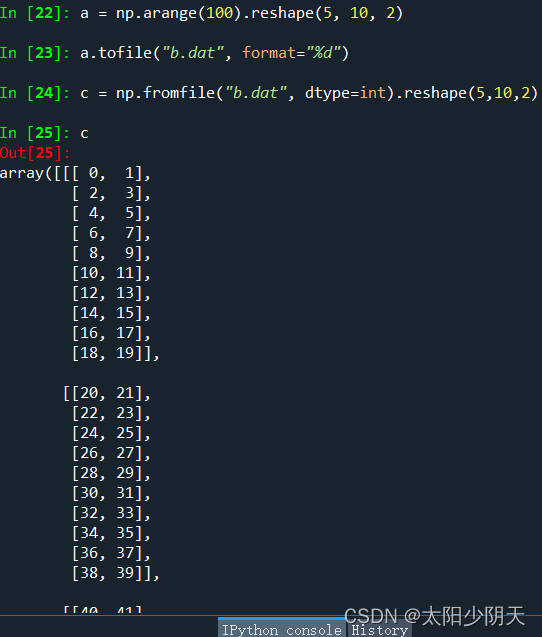
a.tofile(frame, sep=' ', format='%s')
- frame: file, string
- sep: data split string, if it is an empty string, write the file as binary
- format: the format of the written file
np.fromfile(frame, dtype=float, count=-1, sep=' ')
- frame: file, string
- dtype: the data type to read
- count: the number of elements to read, -1 means to read the entire file
- sep: data split string, if it is an empty string, write the file as binary
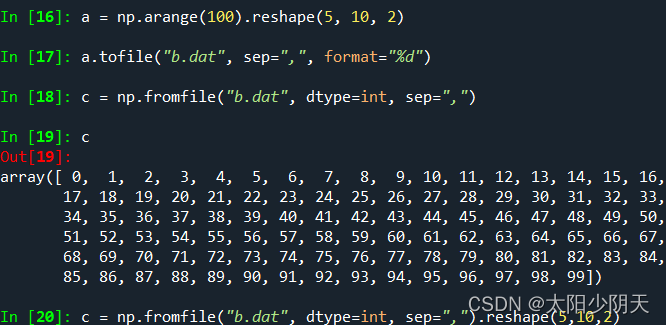
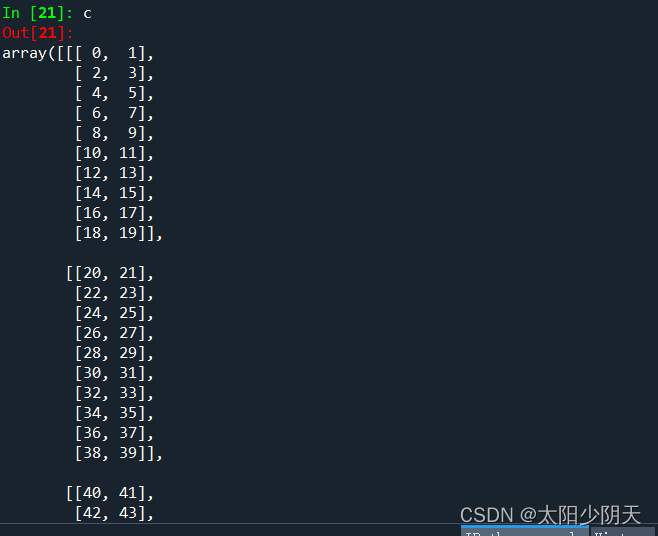
After this method writes the array information to the file, the dimension information is lost, and the original dimension information must be known at the time of reading in to effectively restore the array information.
The above is a text file and the following is a binary file:
Note :
This method needs to know the dimension and element type of the array when saving to the file when reading
a.tofile() and np.fromfile() need to be used together
Additional information can be stored via metadata files
Convenient file access for NumPy
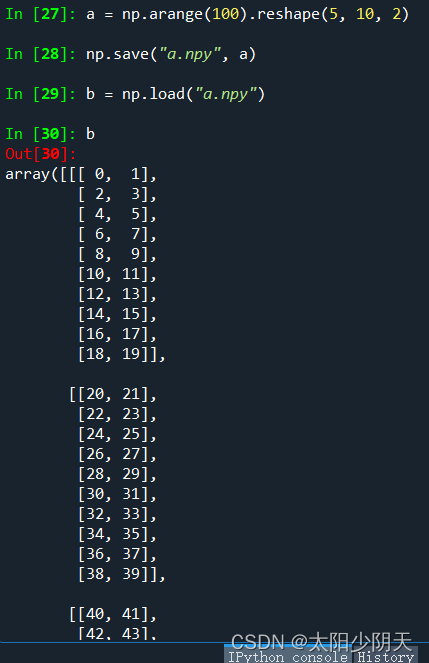
np.save(fname,array) 或 np.savez(fname,array)
- fname: file name, with the extension of .npy, and the compressed extension of .npz
- array: array variable
np.load(fname)
- fname: file name, with the extension of .npy, and the compressed extension of .npz
3. Random functions in NumPy
NumPy's sublibrary for random functions
NumPy's random sublibrary: np.random.*
| function | illustrate |
|---|---|
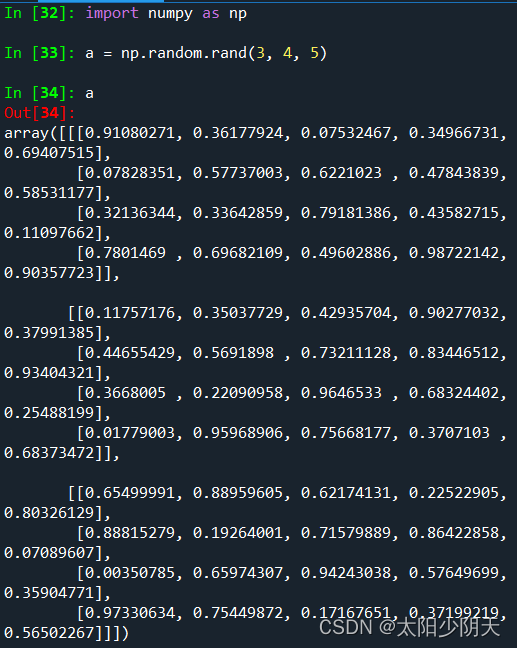
| rand(d0,d1,...,dn) | Create an array of random numbers according to d0-dn, floating point numbers, [0,1), uniform distribution |
| randn(d0,d1,...,dn) | Create an array of random numbers according to d0-dn, standard normal distribution |
| randint(low[,high,shape]) | Create a random integer or integer array according to shape, the range is [low, high) |
| seed(s) | Random number seed, s is the given seed value |
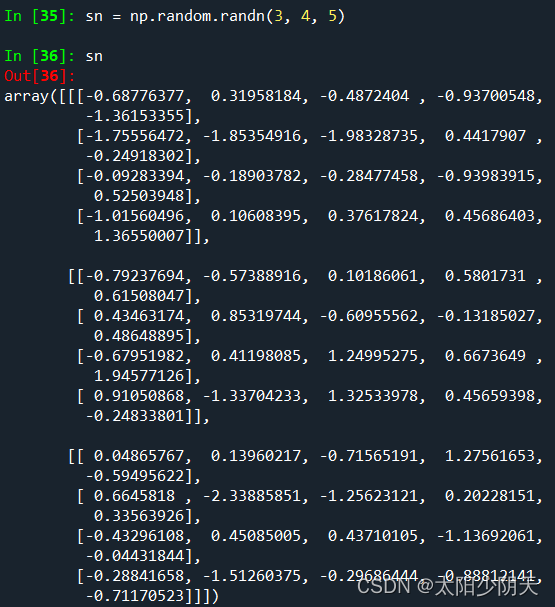
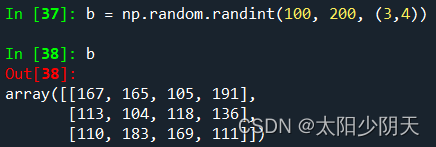
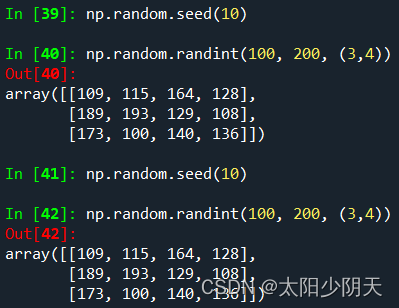
By setting and reusing the same random number seed, we can get the same generated random number array during testing.
| function | illustrate |
|---|---|
| shuffle(a) | Randomly arrange according to the 0th axis (outermost layer) of array a, change array a |
| permutation(a) | Generate a new random array according to the 0th axis of array a, without changing array a |
| choice(a[,size,replace,p]) | Extract elements from one-dimensional array a with probability p to form a new array of size shape, replace indicates whether elements can be reused, the default is True. p defaults to the same probability |
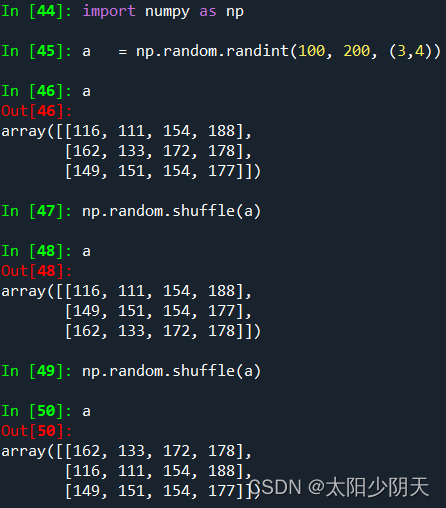
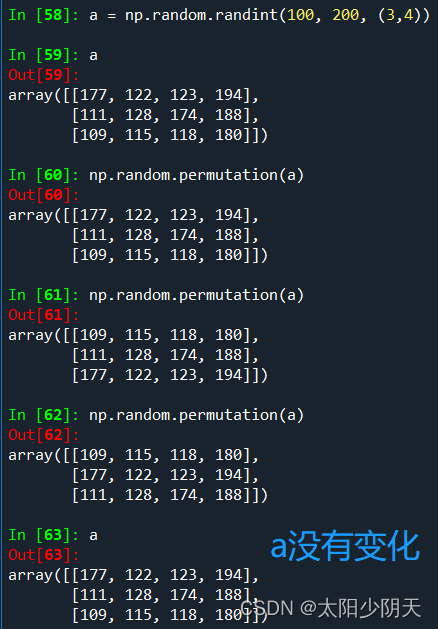
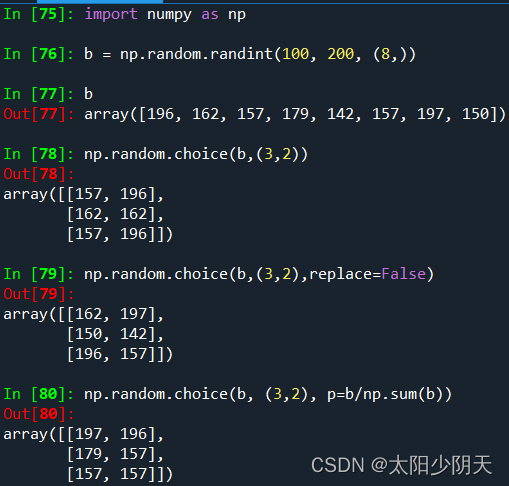
| function | illustrate |
|---|---|
| uniform(low,high,size) | Produces an array with uniform distribution, low start value, high end value, size shape |
| normal(loc,scale,size) | Generate an array with normal distribution, loc mean, scale standard deviation, size shape |
| poisson(lam,size) | Generates an array with Poisson distribution, lam random event rate, size shape |
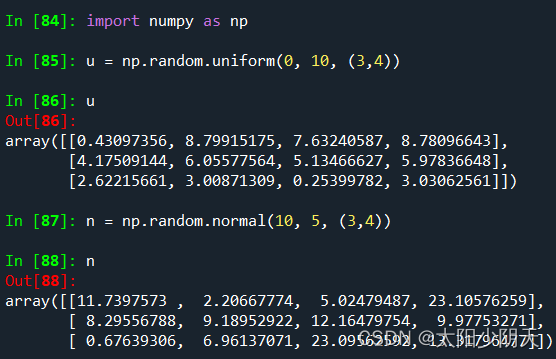
4. Statistical functions of NumPy
Statistical functions directly provided by NumPy: np.*
| function | illustrate |
|---|---|
| sum(a, axis=None) | Computes the sum of the relevant elements of the array a according to the given axis, an integer or tuple of axis |
| mean(a, axis=None) | Computes the expectation of the relative element of array a according to the given axis, axis integer or tuple |
| average(a, axis=None, weights=None) |
Computes the weighted average of the relevant elements of array a according to the given axis axis |
| std(a, axis=None) | Computes the standard deviation of the relative elements of the array a according to the given axis axis |
| var(a, axis=None) | Computes the variance of the relative elements of array a according to the given axis axis |
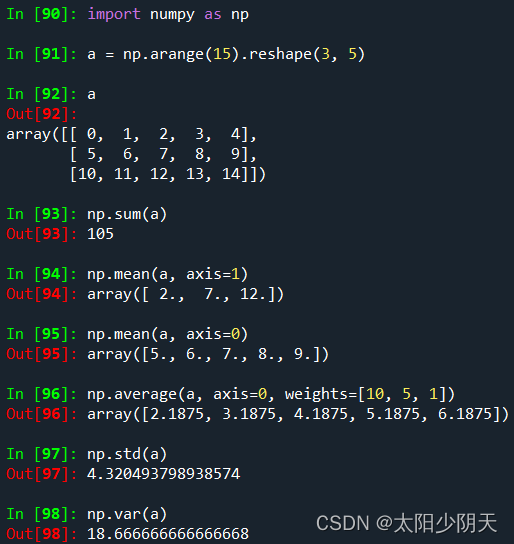
| function | illustrate |
|---|---|
| min(a) max(a) | Calculate the minimum and maximum values of the elements in the array a |
| argmin(a) argmax(a) | Calculate the subscript of the minimum value and maximum value of the elements in the array a after one-dimensional reduction |
| unravel_index(index, shape) | Convert one-dimensional subscript index to multidimensional subscript according to shape |
| ptp(a) | Calculate the difference between the maximum value and the minimum value of the elements in the array a |
| median(a) | Calculates the median (median value) of the elements in array a |
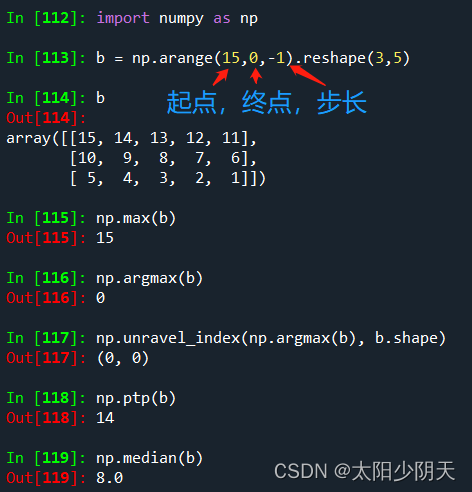
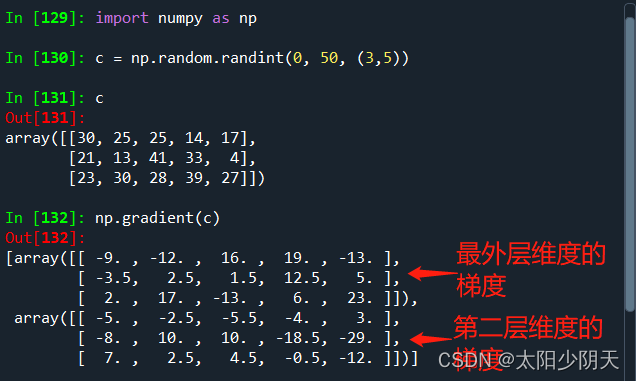
5. Gradient function of NumPy
| function | illustrate |
|---|---|
| np.gradient(f) | Calculate the gradient of the elements in the array f, when f is multi-dimensional, return the gradient of each dimension |
Gradient: The rate of change, or slope, between successive values.
The Y axis values corresponding to three consecutive X coordinates on the XY coordinate axis: a, b, c, where the gradient of b is: (ca)/2

The above content is referenced from: Teacher Songtian, MOOC, Chinese University