CNN
My other blog:Deep Learning - Recurrent Neural Network[Ng Enda] explains what CNN is and the predecessor of CNN. For more information on calculation and back propagation, you can refer to the theory and calculation.
1. Ask specific questions
For image classification, if you want to input an image into the model for classification, what should it look like?
For the computer, the picture is actually a three-dimensional Tensor (more than a two-dimensional matrix). The three dimensions are (height, width, channel) Among them, channel represents the channel, which for pictures is R, G, and B channels. Each point in each channel is actually a pixel value.

We all know that the inputs to the neural network are actually vectors , so if you want to input the picture into the neural network , it needs to be converted into a vector for calculation, so how to convert it into a vector? We have obtained a three-dimensional representation. Flatting the three dimensions will give us a one-dimensional input vector, such as the figure above (100 , 100, 3), after flattening, it is an input vector of 3x100x100. The value of each dimensional vector actually represents the intensity of a certain color.
If you use the previous Fully Connected Network (fully connected network), then the input of 100x100x3, if there are 1000 neurons, each neuron will give a weight to all inputs value, then this weight is 100x100x3x1000=3x10^7 weights! (This value is very large)
Therefore, it is necessary to consider using other neural networks for image recognition.
2. Try to solve the problem
If you don’t want to have so many weights, you have to wonder if each neuron should not input the characteristics of the entire image?
Two optimizations are proposed for specific features
The first feature:
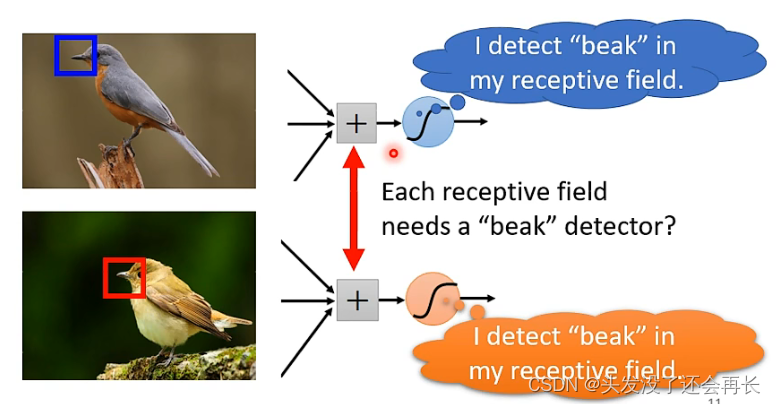
For example, in the picture below, if we want to identify whether an image is a bird, then we find that, as long as we observe With key features such as beak and claws, we can identify that this is a bird, soeach neuronYou can onlyrecognize a local feature of the image instead of taking the entire image as input.
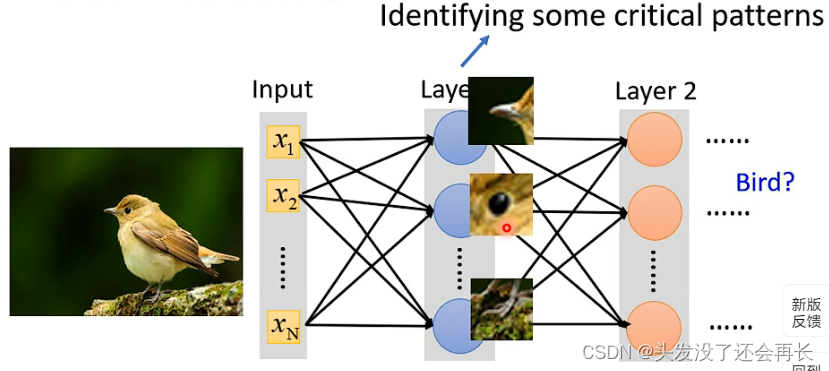
For the first feature, the input can be processed like this:
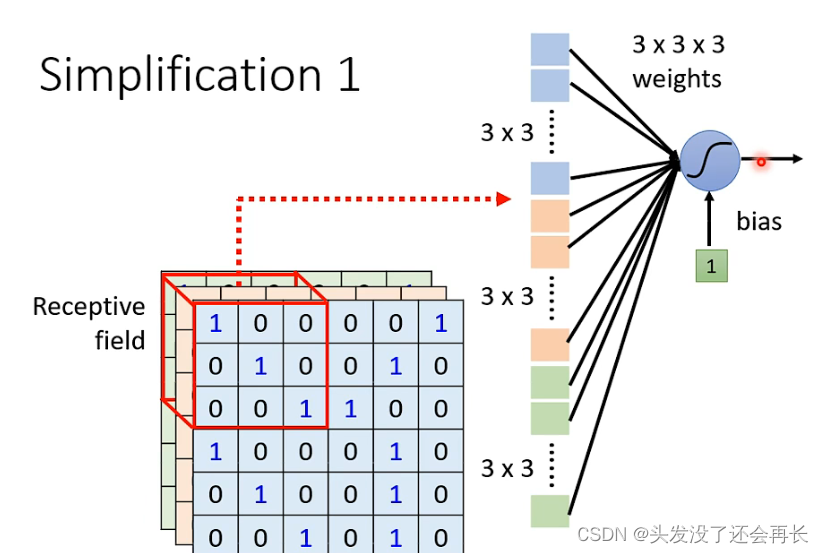
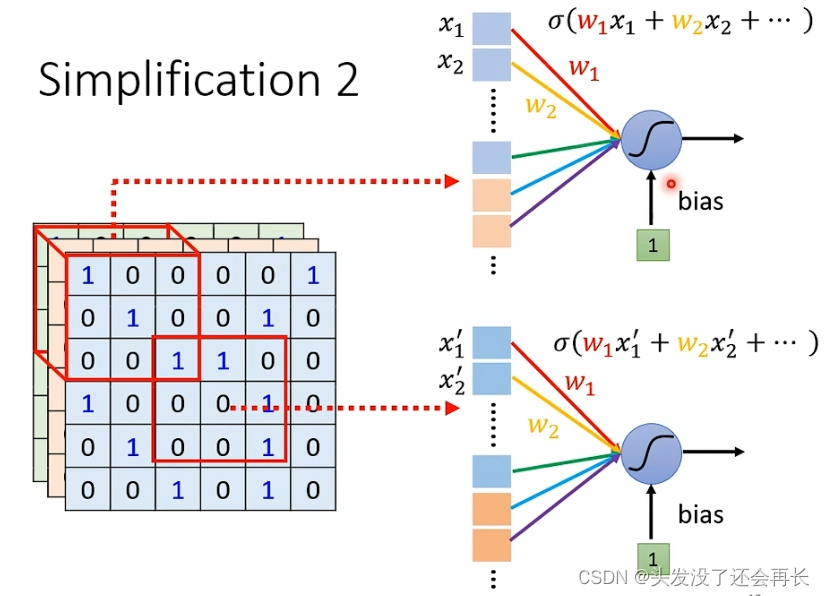
Since each neuron only considers local features, theneach neuron As input, you can only take a certain part of the pixels of the image (here calledReceptive field) as input. For example, in the figure below, for the blue neurons, we only take The pixel in the upper left corner3x3x3is used as input. After flattening, the result is a 3x3x3=27-dimensional vector
Similarly, each This can be done for each neuron. The input pixels of different neurons can overlap. Similarly, different neurons can perform operations on the same Receptive field.
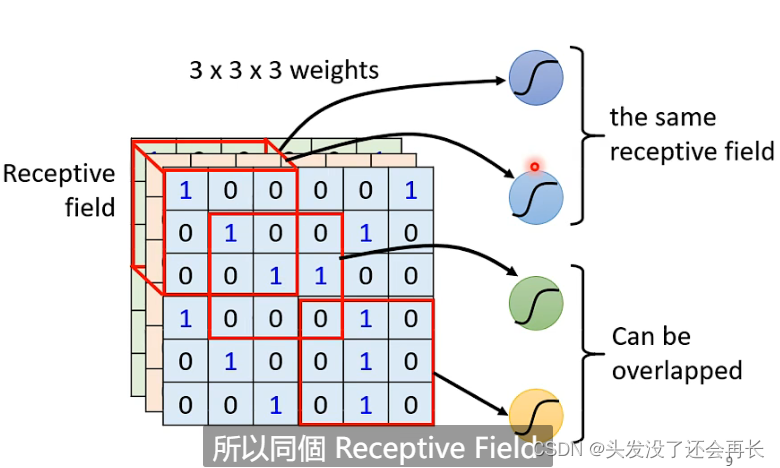
The size of Receptive Filed can be set by yourself, and each Receptive field can only consider one channel, but the most typical settings are as follows:
Receptive Filed consideration (padding)out of range should also be considered (because some characteristics to be observed may be in Between two Receptive Filed), overlap between different Receptive Fileds , there is multiple neurons (64) are (3x3), each Receptive Filed has , All channelskernel size
Second feature:
The same feature may appear in different locations in the picture. For example, in the picture below, the beak appears in different locations. , that is, different Receptive fields. As mentioned above, our Receptive field must cover the entire picture. Each Receptive field has multiple neurons to detect, so no matter where the beak is, it will definitely If it falls inside a certain Receptive field, a certain neuron of a group of neurons will detect it
However, each neuron that detects the beak is the same, but the range is different. The same, then if there is a neuron for detecting beaks in each range, there will be too many parameters.
For the second feature, the weight can be processed like this:
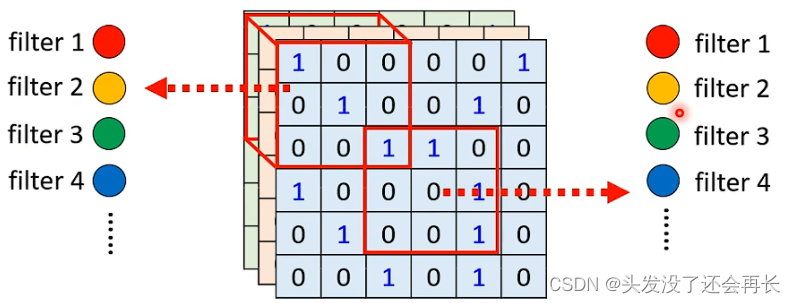
Shared parameters, we can let neurons in different Receptive fields share parameters (that is The same parameters), because the inputs of different Receptive field neurons are different, so even if the weights are the same, the outputs are different.
You can decide the method of sharing parameters yourself, but the typical processing method is as follows:
Each Receptive field has multiple neurons, we can assume 64, < /span> In the specific calculation, each filter is allowed to scan the entire picture! That is, the convolution operation. shared parameter, and so on. (The neurons of the same color in the picture below represent shared parameters)The firstThe second Receptive field and The first The first Receptive field of share parameters, the firstthe second Receptive fieldand One first Receptive field (The parameters of different neurons in a Receptive field must be different, because the input is the same and the parameters are the same. , the output is the same, there is no difference between the two neurons), shared between different Receptive fields, it is the Each neuron has its own set of parameters filterfilter1filter1filter2filter2
3. Summarize, optimize and solve problems
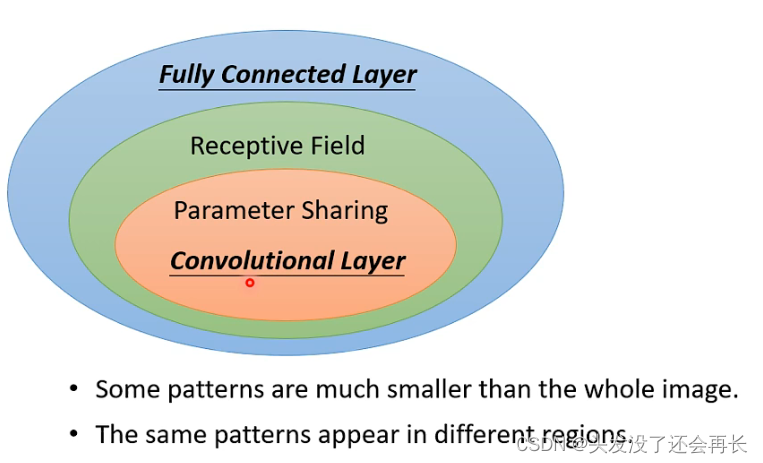
The above two optimizations are to consider a Receptive Filed for each neuron to reduce the input parameters. Different Receptive Fileds share the same parameters, and the sharing is achieved through filters
These two A summary of the optimizations is: Convolutional Layer
The network using Convolutional Layer is called Convolutional Neural Network(CNN)
Additional:
Convolutional Layer is actually calculation Convolution, regarding the convolution operation of images, you can refer to CSDN's many well-explained blogs. I will not explain it in detail here.
There will be as many channels as there are filters, and the height of each filter must be consistent with the input channel , (for example, channel is 3, filter That is 3), the size of each channel is related to filter and image
Q: If the filter size is always 3x3, will a wide range of patterns not be detected?
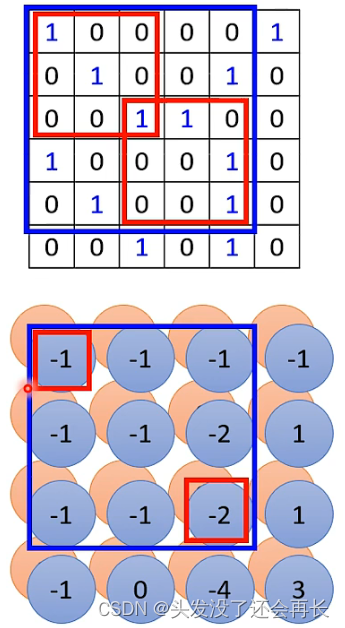
A: No, because the filter of the first layer detects the pattern of3x3, and the result is input to the second convolution layer. The filter is still 3x3, but takes the previous result as input, and the detection range is actually the area of 5x5(as shown below) , the -1 of the second image comes from the value calculated by the filter in the upper left corner of the first image, and the -2 of the second image comes from the value calculated by the filter in the lower right corner of the first image, so what the second filter detects is the original image input pattern of 5x5), and so on,As long as the network is deep enough, even if the filter is always 3x3, it will detect a large enough pattern
4. The third commonly used optimization
Pooling
We are still observing the picture. If the picture is a bird, after we do subsampling, it still looks like a bird
There are no parameters to be learned in the Pooling operation, which is very Like the activation function in the network
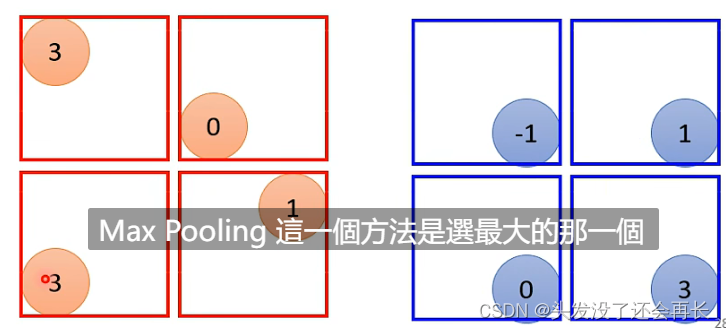
Calculation of Max Pooling:
After the filter, some numbers will be generated. When doing Pooling, the results generated by the filter are grouped. , for example, each 2x2 number is a group. Max Pooling selects a maximum value in each group as the result of this group.
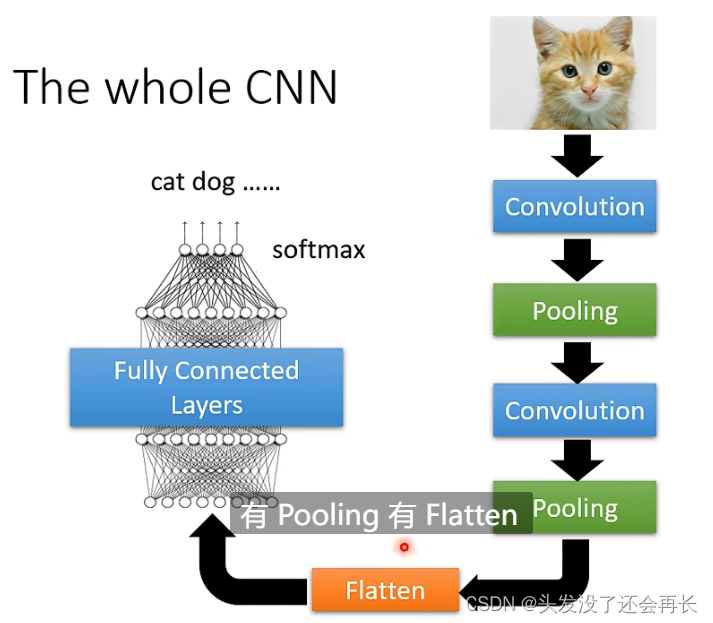
So Pooling will To make the picture smaller (the input becomes smaller, but the number of channels is not changed), usually a Convolutional is followed by Pooling, a Convolutional is followed by Pooling, and so on. In order to get the final result, < /span> (pulling a multi-dimensional matrix into one dimension), and then use a full connection and softmax to output the final result. will do an operation ofFlatten


Other applications of CNN
CNN can also be used in language and text processing, but it must be considered that text and language are different from images, so it is necessary to consider how to design a Receptive field for processing. Consider how to share parameters. These must be designed based on the characteristics of voice and text.
Disadvantages of CNN
CNN cannot process the same enlarged or rotated image. For example, CNN can recognize that a picture is a dog, but when the image is enlarged, reduced or rotated, it cannot recognize it. Before and after processing After the image is flattened, the vector values are different, so the calculation results are also different
Therefore, there is a data enhancement method when processing images, which is to process the image itself, its amplification When reduced, a certain part will also be used as input to train the network.