Some parameters of the trained model, such as weights and observations, have been trained and exist in the model.
Note: The deploy file is a description file of the model structure. We use draw_net.py to draw the model using the method of the previous fourth blog model visualization:

The network is relatively long, with many layers and wide width. I only upload a small screenshot here, and I will not upload all the pictures. If you are interested, you can take a look at the network structure diagram yourself.
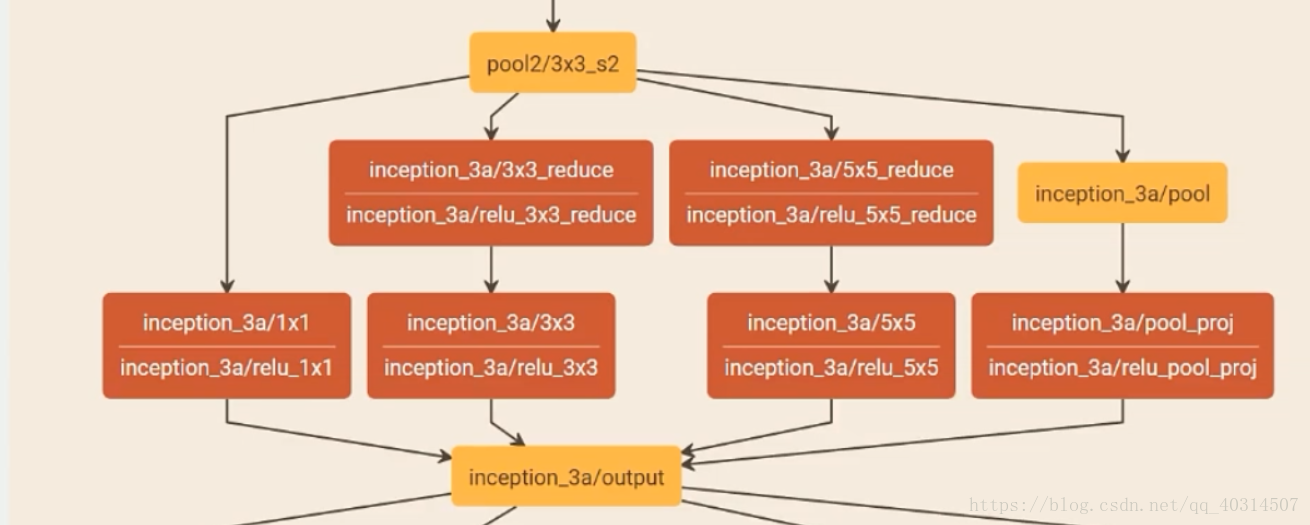
In the Inception structure in the figure, convolution kernels of different sizes mean receptive fields of different sizes, and the final merger means the fusion of features of different scales. Inception is a very characteristic structure of the googleNet network. The size of the convolution kernel is 1, 3, and 5 because the feature plane size obtained after sampling with the step size of 1 and pad=0, 1, and 2 is the same. Because the merging of data requires that the size and latitude of the image must be the same.
There are more than 2,000 lines of code in the entire network. Here I upload some of the code that needs to be annotated:
name: "GoogleNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 3 dim: 224 dim: 224 } } #10 pictures are input each time, 3-dimensional data, and the picture pixels are 224*224
}
layer {
name: "conv1/7x7_s2"
type: "Convolution"
bottom: "data"
top: "conv1/7x7_s2"
param {
lr_mult: 1
decay_mult: 1 #Used to adjust the weight decay parameters
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 3 #pad is to add zeros to the image, pad:3 is to add 3 circles.
kernel_size: 7
stride: 2 #step size
weight_filler {
type: "xavier"
std: 0.1 #standard deviation
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
2. Prepare the picture to be recognized

3. Prepare the synset_words.txt file
It can be downloaded online. synset_word.txt is a label file with 1000 lines representing 1000 objects and 1000 categories. When using googlenet, a number is returned, and we can find the object corresponding to the number from this folder.

4. Use python interface call to realize image recognition, program download address:
python interface call to realize image recognition
After identifying the above image, the final result is as follows:
