Table of contents
Clustered index & secondary index
Index structure (2)
B+Tree
B+Tree is a variant of B-Tree. Let's take a b+ tree with a maximum degree of 4 as an example to take a look at its structural diagram:
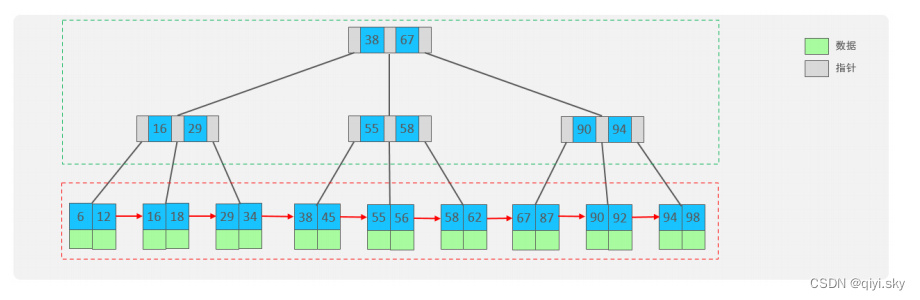
We can see two parts:
- The part enclosed by green dotted circles is the quoted part, which only serves to index data and does not store data.
- The part surrounded by red dotted circles is the data storage part, and specific data must be stored in its leaf nodes.
In other words, in the B-tree, the data stored will be placed in the last leaf node.
Similarly, we can go to the data structure visualization website to demonstrate:
https://www.cs.usfca.edu/~gall es/visualization/BPlusTree.html
Insert a set of data: 100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88 120 268 250.
Then observe the changes in the nodes during the insertion of some data.
Finally, we found that there are three main differences between B+Tree and B-Tree:
- All data will appear in leaf nodes.
- Leaf nodes form a one-way linked list.
- Non-leaf nodes only play the role of indexing data, and specific data are stored in leaf nodes.
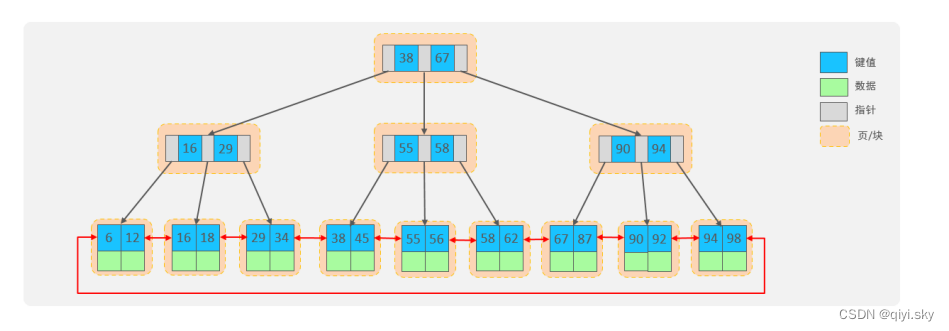
The structure we saw above is the standard B+Tree data structure. Next, let’s take a look at the optimized
B+Tree in MySQL.
The MySQL index data structure optimizes the classic B+Tree. On the basis of the original B+Tree, a linked list pointer pointing to the adjacent leaf node is added to form a B+Tree with a sequence pointer, which improves the performance of interval access and facilitates sorting.
Hash
In addition to supporting B+Tree indexes, MySQL also supports an index type---Hash index.
structure
Hash index uses a certain hash algorithm to convert the key value into a new hash value, maps it to the corresponding slot, and then stores it in the hash table.

If two (or more) key values are mapped to the same slot, they will have a hash conflict (also called a hash collision), which can be resolved through a linked list.

This is basically consistent with the hash table in the data structure.
Features
- Hash index can only be used for peer comparison (=, in) and does not support range query (between, >, <,...)
- Unable to use index to complete sort operation
- The query efficiency is high (there is no hash conflict) and usually only one retrieval is required. The efficiency is usually higher than the B+Tree index.
Storage engine support
In MySQL, the Memory storage engine supports hash indexes. InnoDB has an adaptive hash function, and the hash index is automatically built by the InnoDB storage engine based on the B+Tree index under specified conditions.
think
Why does the InnoDB storage engine choose to use the B+Tree index structure?
1. Compared with binary trees, there are fewer levels and high search efficiency;
2. For B-tree, no matter it is a leaf node or a non-leaf node, data will be saved, which will lead to a reduction in the
key values stored in a page and a decrease in pointers, which requires Saving a large amount of data can only increase the height of the tree, resulting in reduced performance;
3. Compared with Hash index, B+tree supports range matching and sorting operations.
Index classification
Index classification
In the MySQL database, the specific types of indexes are mainly divided into the following categories: primary key index, unique index, regular index, and full-text index.
| Classification | meaning | Features | Keywords |
|---|---|---|---|
| primary key index |
Index created on the primary key in the table
|
Automatically created by default
,
there can only be one
|
PRIMARY
|
|
unique index
|
Avoid duplication of values in a data column in the same table
|
There can be multiple
|
UNIQUE
|
| regular index | Quickly locate specific data | There can be multiple | |
| Full text index | Full-text indexing searches for keywords in the text rather than comparing values in the index | There can be multiple | FULL TEXT |
Clustered index & secondary index
In the InnoDB storage engine, according to the storage form of the index, it can be divided into the following two types:
| Classification | meaning | Features |
|---|---|---|
| Clustered Index |
Putting data storage and index together, the leaf nodes of the index structure store row data
|
There must be
,
and only one
|
|
Secondary
Index
|
Store data and indexes separately. The leaf nodes of the index structure are associated with the corresponding primary keys.
|
There can be multiple |
Clustered index selection rules:
- If a primary key exists, the primary key index is a clustered index.
- If no primary key exists, the first unique ( UNIQUE ) index will be used as the clustered index.
- If the table does not have a primary key, or a suitable unique index, InnoDB will automatically generate a rowid as a hidden clustered index.
The specific structures of clustered indexes and secondary indexes are as follows:

we can find out that:
- The leaf node of the clustered index hangs the data of this row.
- The leaf node of the secondary index hangs the primary key value corresponding to the field value.
Search process
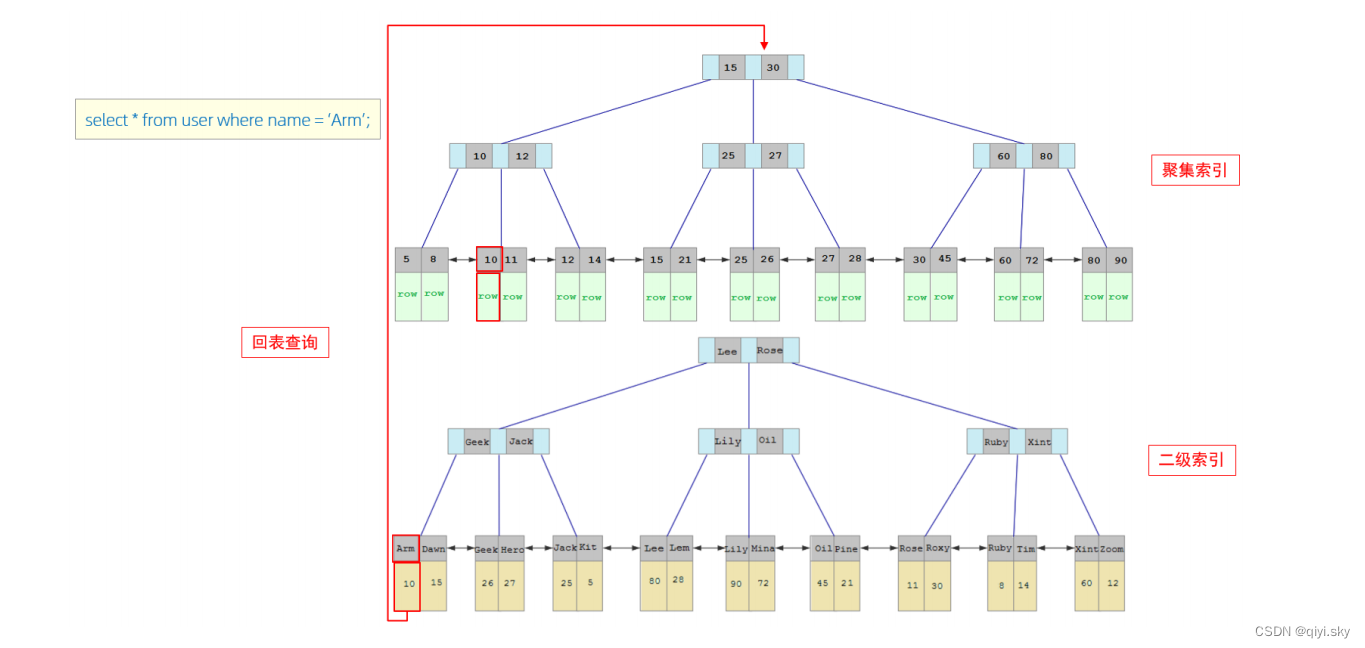
The specific process is as follows:
- Since the query is based on the name field, we first perform a matching search in the secondary index of the name field based on name='Arm'. However, only the primary key value 10 corresponding to Arm can be found in the secondary index.
- Since the data returned by the query is *, at this time, you need to search the clustered index for the record corresponding to 10 based on the primary key value 10, and finally find the row corresponding to 10.
- Finally, you can get the data of this row and return it directly.
Table-back query : This method of first searching for data in the secondary index, finding the primary key value, and then obtaining the data based on the primary key value in the clustered index is called table-back query.
think
Which of the following two SQL statements is more efficient? Why?
A. select * from user where id = 10;
B. select * from user where name = 'Arm';
(Note: id is the primary key, and the name field is indexed )
The execution performance of statement A is higher than statement B.
Because statement A goes directly to the clustered index and returns data directly. Statement B needs to query the secondary index of the name field first, and then
query the clustered index, which means a table query needs to be performed .
What is the B+tree height of InnoDB primary key index?

Assumption:
The size of one row of data is 1k, and 16 rows of such data can be stored in one page. InnoDB pointers occupy 6 bytes of space
. Even if the primary key is bigint, the number of bytes occupied is 8.
The height is 2:
n * 8 + (n + 1) * 6 = 16*1024, and n is calculated to be approximately 1170n refers to the number of keys currently stored; n*8 counts the total number of bytes occupied by the primary key; n+1 represents the number of pointers, one more pointer than key; 1KB (K) = 1024bit, all units are used here Unified to bit, so 16kb = 16 * 1024 bit, 16 means 16 pages;
1171* 16 = 18736.
In other words, if the height of the tree is 2, more than 18,000 records can be stored.
The height is 3:
1171 * 1171 * 16 = 21939856.
In other words, if the height of the tree is 3, about 2200w of records can be stored.
END
Learn from: Dark Horse Programmer - MySQL Database Course