Article Directory
Gathered (clustered) index, also called the clustered index
The same sequence of physical row and column values of data (that is typically the primary key column) of the logical order, a table can have only one clustered index: defined.
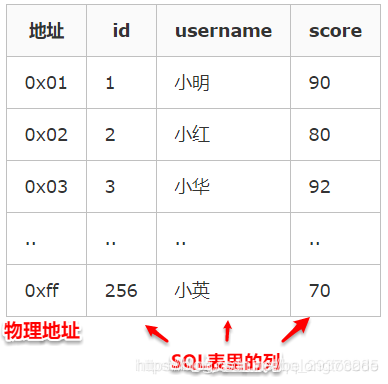
Note: The first column indicates that the address line of data in the physical address of the disk , followed by three is our SQL table with columns inside, where id is the primary key, the establishment of a clustered index.
Combined with the above table can understand this sentence right: the physical order of rows with the same order of column values, data query id if we compare against, then the address of the physical address line of data on the disk will be relatively lean back. And because the same order of the physical arrangement of the clustered index, so it can build up a clustered index.
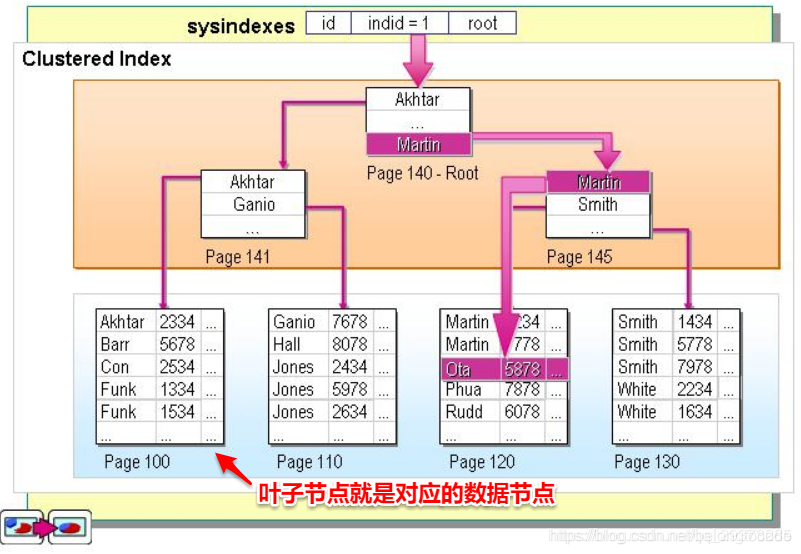
From the chart we can see the benefits of a clustered index, the index leaf node is the corresponding data node (MySQL's MyISAM exception, this storage engine clustered index and non-clustered indexes more than just a unique constraint, the other no difference), you can direct access to the data corresponding to all columns, rather than gather in the index when the index does not cover the corresponding column of the need for secondary queries , speak in more detail later. So in terms of the query, the clustered index of speed tend to be more dominant .
Create a clustered index
If you do not create the index, the system will automatically create a clustered index on the table as hidden columns.
1. Create a table when the specified primary key (Note: SQL Sever is the default primary key clustered index, you can also specify a non-clustered index, and is the primary key in MySQL clustered index)
create table t1(
id int primary key,
name nvarchar(255)
)
2. Create a clustered index is added after the table
MySQL
alter table table_name add primary key(colum_name)
Notably, a clustered index is best added when creating the table, due to the special nature of the physical order of the clustered index, thus re-created if the index moves in the above order when the above all the data lines according to a ranking index columns It will be very time-consuming and performance.
Non-aggregated (unclustered) Index
Definition: The logical order of the index index and the physical disk storage order different uplink, a table can have multiple non-clustered index.
其实按照定义,除了聚集索引以外的索引都是非聚集索引,只是人们想细分一下非聚集索引,分成普通索引,唯一索引,全文索引。如果非要把非聚集索引类比成现实生活中的东西,那么非聚集索引就像新华字典的偏旁字典,他结构顺序与实际存放顺序不一定一致。
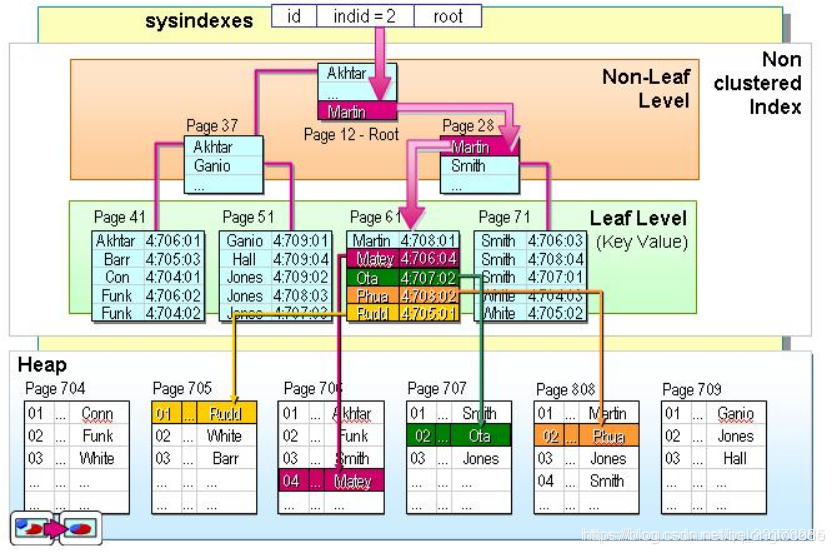
非聚集索引的二次查询问题
非聚集索引叶节点仍然是索引节点,只是有一个指针指向对应的数据块,此如果使用非聚集索引查询,而查询列中包含了其他该索引没有覆盖的列,那么他还要进行第二次的查询,查询节点上对应的数据行的数据。
有表t1:
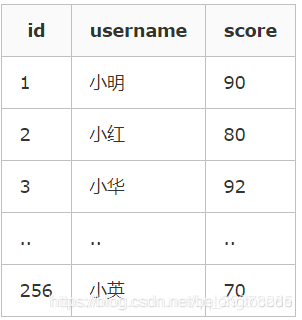
其中有 聚集索引clustered index(id), 非聚集索引index(username)。
使用以下语句进行查询,不需要进行二次查询,直接就可以从非聚集索引的节点里面就可以获取到查询列的数据。
select id, username from t1 where username = '小明'
select username from t1 where username = '小明'
但是使用以下语句进行查询,就需要二次的查询去获取原数据行的score:
select username, score from t1 where username = '小明'
总结
聚集索引和非聚集索引的根本区别是表中记录的物理顺序和索引的排列顺序是否一致,本质是叶子节点的索引文件和数据文件是否分离的
建议使用聚集索引的场合为:
-
某列包含了小数目的不同值。
-
排序和范围查找。 非聚集索引的记录的物理顺序和索引的顺序不一致。
建议使用非聚集索引的场合为:
-
此列包含了大数目的不同值;
-
频繁更新的列
其他方面的区别:
1.聚集索引和非聚集索引都采用了 B+树的结构,但非聚集索引的叶子层并 不与实际的数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中 的指针的方式。聚集索引的叶节点就是数据节点,而非聚集索引的叶节点仍然 是索引节点。
2.非聚集索引添加记录时,不会引起数据顺序的重组。
基于主键索引和普通索引的查询有什么区别?
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k)) engine=InnoDB;
(ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6)
The leaf nodes of the primary key index is stored entire row of data. In InnoDB, the primary key index is also called clustered index (clustered index).
Non-primary key index leaf node content is the value of the primary key. In InnoDB, the non-primary key index is also called the secondary index (secondary index)
If the statement is select * from T where ID = 500 , i.e., the primary key query, the tree only needs to search for a B + tree ID
If the statement is select * from T where k = 5 , that is, the general index query, you'll need to search the index k tree, get a value of 500 ID, to the ID search index tree once. This process is called back to the table
B + tree index in order to maintain orderly, insert a new value in the time required to do the necessary maintenance. In the above example, if inserting a new row ID value 700, only need to insert a new record just behind the record R5. If the newly inserted ID is 400, it is relatively cumbersome, the need to move back data logically, the empty position.
Reference article:
https://blog.csdn.net/qq_29373285/article/details/85254407
https://blog.csdn.net/qq_43193797/article/details/88593304
http://blog.itpub.net/30126024/viewspace -2221485 /
