B-tree
Related concepts
B-tree belongs to multi-fork tree, also known as balanced multi-way search tree (there are more than two search paths).
In database indexing technology, a large number of users use B-tree and B+ tree data structures for the following reasons:
- To speed up the stored process , the data and indexes in the mysql table are stored in peripheral devices such as disks. However, compared with the memory, the speed of reading data from the disk will be hundreds of times or even ten thousand times slower. Therefore, we should minimize the number of times to read data from the disk. The worst time complexity of using B-tree query is B's tree height.
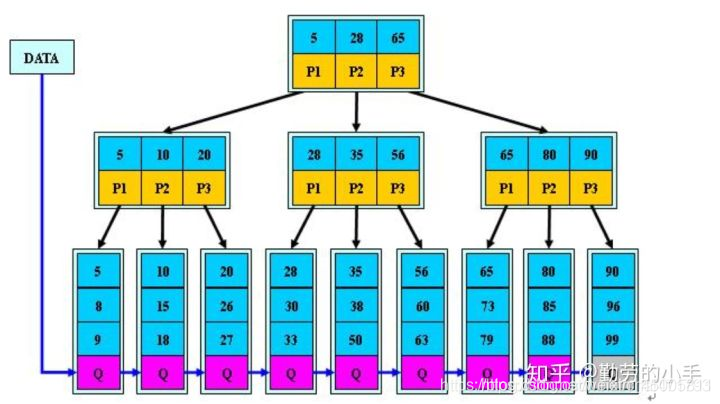
- Read as much data as possible at a time . The smallest unit of disk storage and query is a block (the size of each block is 4K). If we can put as many keywords as possible into a disk block, a disk read operation is It will read more keywords and make full use of the disk block space, compress the tree level, and reduce the number of data lookups and time complexity. (The basic unit of data reading in mysql is the page, which is the disk block mentioned above) (a keyword consists of a key key and a value value) as follows
is a B-tree with an order of 3 (the child of each page The number of nodes is the order)

The characteristics of B-tree structure are as follows:
- Sorting method: all node keywords are arranged in ascending order, and follow the principle of small on the left and large on the right;
- Number of child nodes: M>=Number of child nodes of non-leaf nodes>1 (M>=2), except for empty trees (Note: M order represents how many search paths a tree node has at most, M=M paths, when M= 2 is a 2-fork tree, M=3 is a 3-fork tree);
- Number of keywords: M-1>=number of keywords of the node>=ceil(m/2)-1 (Note: ceil() is a function that rounds towards positive infinity, such as ceil(1.1) results in 2);
related operations
Inquire
Take the above figure as an example, query the user information with id=28, the process is as follows:
- First find the root node, which is page 1, and judge that 28 is between the key value 17 and 35, then we find page 3 according to the pointer p2 in page 1.
- Comparing 28 with the key value in page 3, 28 is between 26 and 30, we find page 8 according to the pointer p2 in page 3.
- Comparing 28 with the key value in page 8, it is found that there is a matching key value 28, and the user information corresponding to key value 28 is (28, bv).
insert
Define a 5-order tree (balanced 5-way search tree;), now we need to build a 5-order tree with the numbers 3, 8, 31, 11, 23, 29, 50, and 28;
rules:
- Sorting: Satisfy the sorting rule that the node itself is larger than the left node and smaller than the right node;
- Split: If the number of node keywords is greater than the limited range, it needs to be split, that is, take out the middle node as the parent node, and connect the two sides as the left and right nodes. The
process is as follows: - Insert 3, 8, 31, 11 first
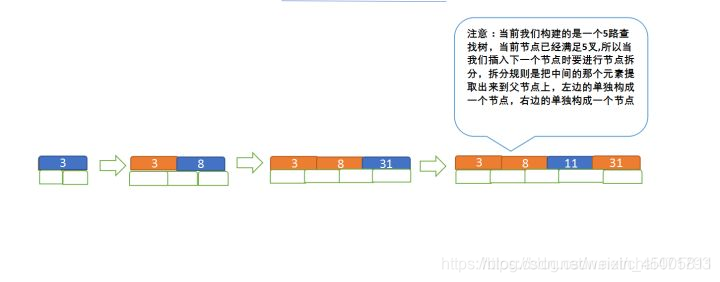
- Then insert 23, 29
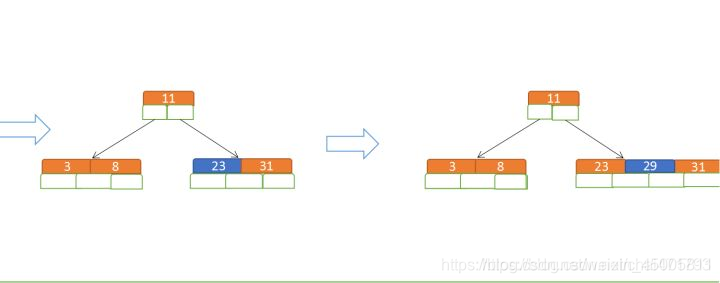
- Then insert 50, 28
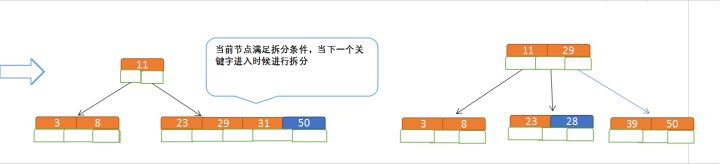
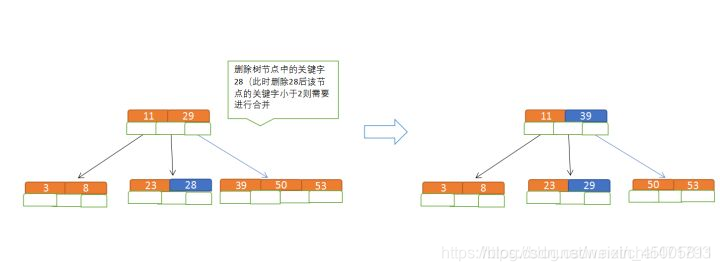
delete
3, 8, 31, 11, 23, 29, 50, and 28 have been inserted into the balanced 5-way search tree, and the 28
rule needs to be deleted at this time:
- Sorting: Satisfy the sorting rule that the node itself is larger than the left node and smaller than the right node;
- Merge: If the number of node keywords is less than the limited range, it needs to be merged, first from the child node, if the child node does not meet the conditions, it will be taken from the parent node. The process is as follows
:
B+ tree
Related concepts
The B+ tree is an upgraded version of the B tree. Compared with the B tree, the B+ tree makes full use of the node space, making the query speed more stable, and its speed is completely close to the binary search.
Compare the similarities and differences between B+ tree and B tree:
- The non-leaf nodes of the B+ tree do not save the value, but only the key key, which greatly increases the data that each non-leaf node of the B+ tree can save;
- The leaf nodes of the B+ tree store the value value, and use a one-way linked list to connect each data in order. In addition, the leaf nodes are connected by a two-way linked list, so the B+ tree makes the range search, sorting search, group search and deduplication search easy. Very simple. However, because the data of the B-tree is scattered in each node, it is not easy to achieve this.
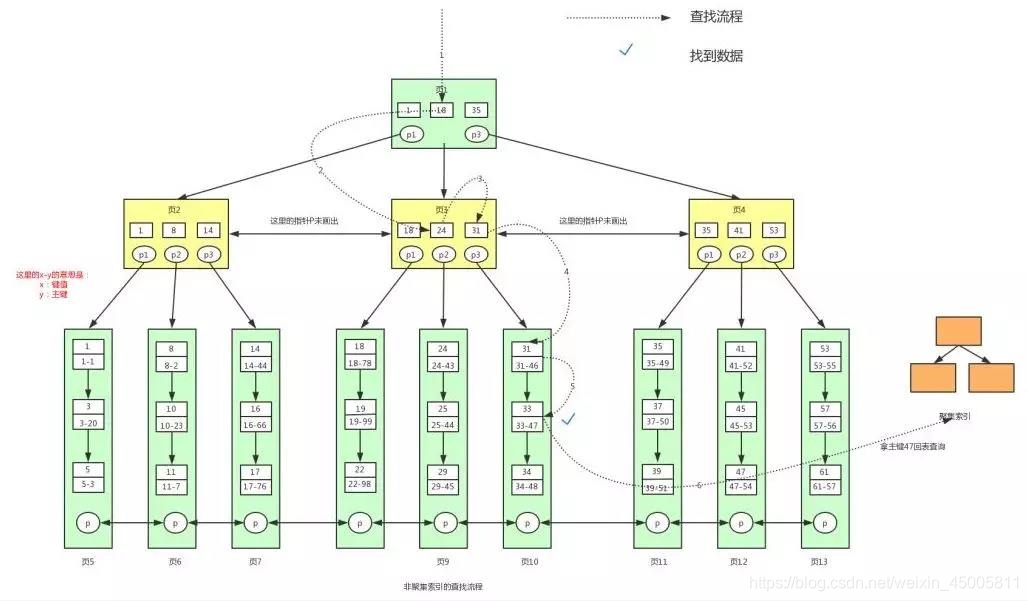
The index is the data, which can be understood as the node of the tree
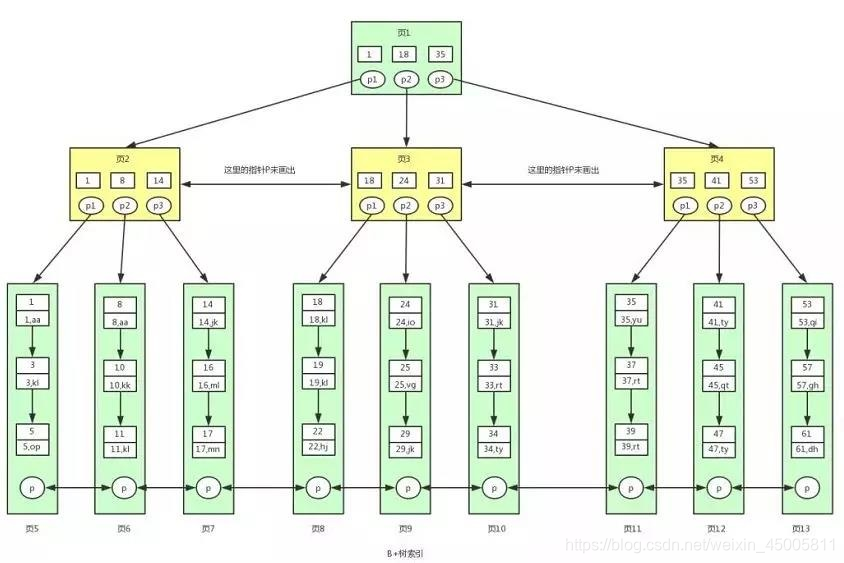
clustered index
Taking InnoDB as the storage engine as an example,
the non-leaf nodes of the B+ tree store the primary key, and
the leaf nodes of the B+ tree store the data
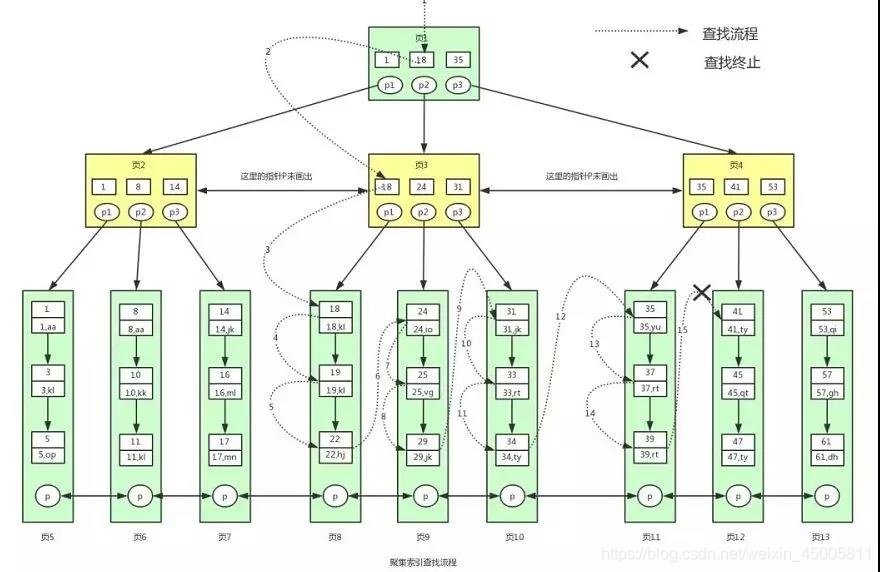
. Assuming a query statement, the query process is as follows:
select * from user where id>=18 and id <40
- Generally, the root node is resident in the memory, that is to say, page 1 is already in the memory. At this time, there is no need to read data from the disk, and it can be read directly from the memory. From page 1, we can find the key value 18. At this time, we need to locate page 3 according to the pointer p2.
- After reading page 3 from the disk, put page 3 into the memory, and then search, we can find the key value 18, and then get the pointer p1 in page 3 to locate page 8.
- After page 8 has been read into memory. Because the data in the page is connected by a linked list, and the key values are stored in order, at this time, the key value 18 can be located according to the binary search method.
- Because it is a range search, and at this time all the data have leaf nodes and are arranged in an orderly manner, then we can traverse the key values in page 8 to find and match the data that meets the conditions. We can always find data with a key value of 22, and then there is no data in page 8
- At this point we need to take the p pointer in page 8 to read the data in page 9. Because page 9 is not in memory, page 9 will be loaded into memory again, and the data will be searched in the same way as page 8, until page 12 is loaded into memory, and it is found that 41 is greater than 40, and the condition is not satisfied at this time . Then the search ends here.
nonclustered index
Taking InnoDB as the storage engine as an example,
the non-leaf nodes of the B+ tree store column values other than the primary key. The
leaf nodes of the B+ tree store the primary key

. Assuming a query statement, the query process is as follows:
select * from user where luckNum=33
- Find the primary key based on column values other than the primary key
- Use the primary key value to find the specific corresponding data information in the clustered index. This step 2 is also called returning the table