1. Use index benefits:
1, to ensure the uniqueness of the data records;
2, speed up data retrieval;
3, a faster connection between the table and the table;
4, when using the ORDER BY GROUP BY clause and retrieval of data can be significantly reduced grouped and sorted query time;
5, may be used to optimize the process of retrieving data hidden in the system performance is improved.
2. clustered index
-
Action: logical order clustered index key values in the table determines the physical order of the corresponding row .
-
Principle: We usually use the phone book, we will be various characters, such as alphabetical size last name to sort, in order to facilitate future look good, but also the type of clustered index, clustered index determines the physical order of the data in the table, so that the data in physical memory in a certain order to organize storage, easy to find later.
-
important point:
- The default setting is the primary key clustered index
- Since the predetermined data is physically clustered index storage order in the table, so a table can contain only one clustered index, but the index may comprise a plurality of columns, like the phone book can be organized in the same first and last name.
3. The non-clustered index
-
Principle: The logical order of the index index and the physical disk storage order different from the uplink.
-
Description: Like a dictionary, there is a directory, find the appropriate word to find the appropriate instructions via the catalog. The index is through the binary tree data structure to describe, so we can understand the clustered index: the index leaf node is the data node. Rather than clustered index leaf node remains inode, but there is a pointer to the corresponding data block.
4. applicable
5. Notes
- It should be the primary key clustered index
usually we establish the main key is to set an id from increasing, and will generally applicable to find data, rather than through the id generated automatically by name or date.
On the other hand, a table and we can have only one clustered index, clustered index if it is set to waste.
As long as the index can significantly improve query speed
Reference article: https: //blog.csdn.net/zhou_xuexi/article/details/78028931
6. Related sql statement:
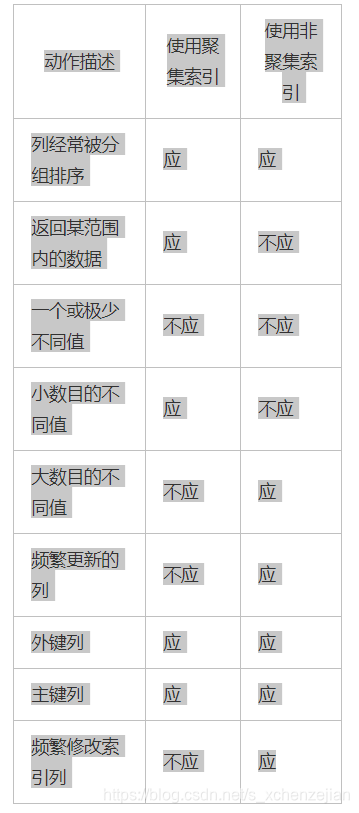
| Action Description | Use clustered index | Using non-clustered index |
|---|---|---|
Column should be sorted are often grouped
return data within a certain range should be
a little different values should or should not be
a small number of different values should not
large number of different values should be
listed should be frequently updated
outer key columns should be
the primary key columns should be
frequently modified index column should not be
//
创建索引
create CLUSTERED INDEX 索引名称 ON 表名(字段名)
//删除索引
alter table 表名 drop constraint 主键约束名称
//将指定字段设置成主键非聚集索引
alter table 表名 add constraint 主键约束名称 primary key NONCLUSTERED(字段名)
//创建表指定主键为非聚集索引,默认不写NONCLUSTERED为聚集索引
CREATE TABLE Test
(
ID INT PRIMARY KEY NONCLUSTERED --非聚集索引
)
