Table of contents
2. Introduction to the safety hat data set
4. Analysis of training results
1.Yolov8 introduction
Ultralytics YOLOv8 is the latest version of the YOLO target detection and image segmentation model developed by Ultralytics. YOLOv8 is a cutting-edge, state-of-the-art (SOTA) model that builds on previous YOLO success and introduces new features and improvements to further improve performance and flexibility. It can be trained on large datasets and is capable of running on a variety of hardware platforms, from CPUs to GPUs.
The specific improvements are as follows:
-
Backbone : still uses the idea of CSP, but the C3 module in YOLOv5 has been replaced by the C2f module, achieving further lightweighting. At the same time, YOLOv8 still uses the SPPF module used in YOLOv5 and other architectures;
-
PAN-FPN : There is no doubt that YOLOv8 still uses the idea of PAN, but by comparing the structure diagrams of YOLOv5 and YOLOv8, we can see that YOLOv8 deletes the convolution structure in the PAN-FPN upsampling stage in YOLOv5, and also removes C3 The module is replaced by the C2f module;
-
Decoupled-Head : Do you smell something different? Yes, YOLOv8 goes to Decoupled-Head;
-
Anchor-Free : YOLOv8 abandoned the previous Anchor-Base and used the idea of Anchor-Free ;
-
Loss function : YOLOv8 uses VFL Loss as classification loss and DFL Loss+CIOU Loss as classification loss;
-
Sample matching : YOLOv8 abandons the previous IOU matching or unilateral proportion allocation method, and instead uses the Task-Aligned Assigner matching method.

The framework diagram is provided at the link: Brief summary of YOLOv8 model structure · Issue #189 · ultralytics/ultralytics · GitHub
2. Introduction to the safety hat data set
The data set size is 3241 images, train:val:test is randomly allocated as 7:2:1, category: hat



3.InternImage introduction

Paper: https://arxiv.org/abs/2211.05778
For the theoretical part, please refer to Zhihu: CVPR2023 Highlight | The scholar model dominates COCO target detection, the research team’s interpretation is made public - Zhihu
Different from recent CNN solutions that focus on large cores, InternImage uses deformation convolution as the core operation (not only has the effective receptive field required for downstream tasks, but also has input and task adaptive spatial domain aggregation capabilities). The proposed scheme reduces the strict inductive bias of traditional CNN and can learn stronger and more robust expression capabilities at the same time. Experiments on tasks such as ImageNet, COCO and ADE20K have verified the effectiveness of the proposed solution. It is worth mentioning that: InternImage-H achieved a new record of 65.4mAP on COCO test-dev .
InternImage improves the scalability of convolutional models and alleviates inductive bias by redesigning operators and model structures, including (1) DCNv3 operator, which introduces shared projection weights, multi-group mechanisms and sampling point modulation based on DCNv2 operators.
(2) Basic module, integrating advanced modules as the basic module unit for model construction
(3) Module stacking rules, standardize the width, depth, number of groups and other hyper-parameters of the model when expanding the model.

Based on the DCNv2 operator, the researcher redesigned, adjusted and proposed the DCNv3 operator. Specific improvements include the following parts.
(1) Shared projection weight. Similar to conventional convolution, different sampling points in DCNv2 have independent projection weights, so its parameter size is linearly related to the total number of sampling points. In order to reduce parameter and memory complexity, we draw on the idea of separable convolution, use position-independent weights to replace grouping weights, share projection weights between different sampling points, and all sampling position dependencies are retained.
(2) Introduce multiple groups of mechanisms. Multi-group design was first introduced in grouped convolution and is widely used in Transformer's multi-head self-attention. It can be combined with adaptive spatial aggregation to effectively improve the diversity of features. Inspired by this, researchers divide the spatial aggregation process into several groups, and each group has an independent sampling offset. Since then, different groups of a single DCNv3 layer have different spatial aggregation patterns, resulting in rich feature diversity.
(3) Sampling point modulation scalar normalization . In order to alleviate the instability problem when the model capacity is expanded, the researchers set the normalization mode to Softmax normalization on a sample-by-sample basis. This not only makes the training process of large-scale models more stable, but also constructs a model of all sampling points. connection relationship.

For details on the source code, see: Point-increasing artifact: Yolov8 introduces CVPR2023 InternImage: Inject new mechanism, expand DCNv3, help increase points, COCO new record 65.4mAP! -CSDN Blog
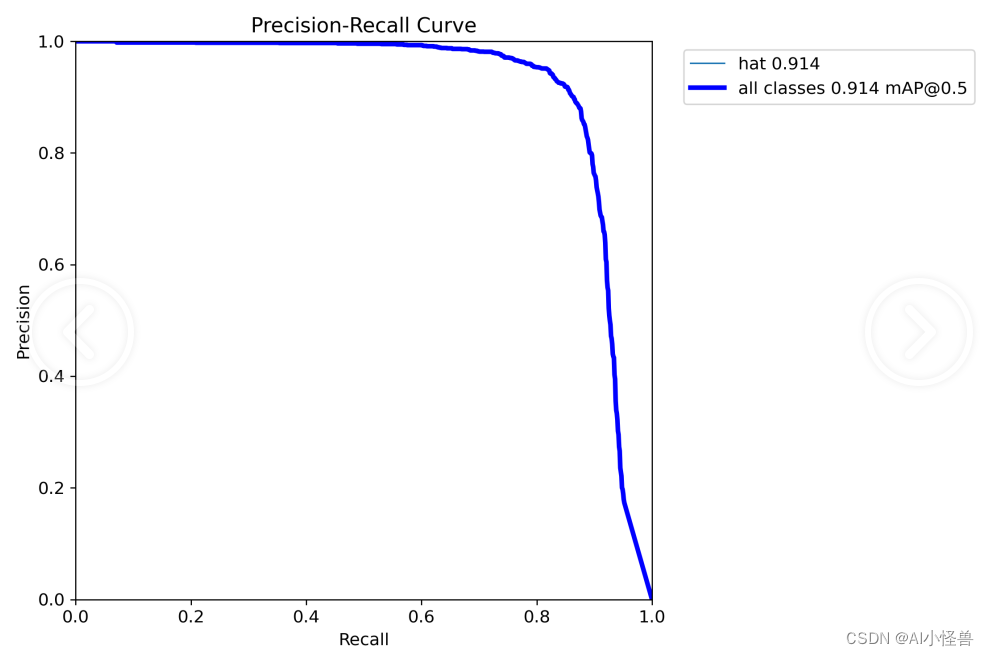
4. Analysis of training results
The training results are as follows:
[email protected] 0.897 increased to 0.914