Table of contents
2. Introduction to wild fire smoke data set
1.2 Get the txt suitable for yolov8 through voc_label.py
2.3 The generated content is as follows
3. Analysis of training results
1.Yolov8 introduction
Ultralytics YOLOv8 is the latest version of the YOLO target detection and image segmentation model developed by Ultralytics. YOLOv8 is a cutting-edge, state-of-the-art (SOTA) model that builds on previous YOLO success and introduces new features and improvements to further improve performance and flexibility. It can be trained on large datasets and is capable of running on a variety of hardware platforms, from CPUs to GPUs.
The specific improvements are as follows:
-
Backbone : still uses the idea of CSP, but the C3 module in YOLOv5 has been replaced by the C2f module, achieving further lightweighting. At the same time, YOLOv8 still uses the SPPF module used in YOLOv5 and other architectures;
-
PAN-FPN : There is no doubt that YOLOv8 still uses the idea of PAN, but by comparing the structure diagrams of YOLOv5 and YOLOv8, we can see that YOLOv8 deletes the convolution structure in the PAN-FPN upsampling stage in YOLOv5, and also removes C3 The module is replaced by the C2f module;
-
Decoupled-Head : Do you smell something different? Yes, YOLOv8 goes to Decoupled-Head;
-
Anchor-Free : YOLOv8 abandoned the previous Anchor-Base and used the idea of Anchor-Free ;
-
Loss function : YOLOv8 uses VFL Loss as classification loss and DFL Loss+CIOU Loss as classification loss;
-
Sample matching : YOLOv8 abandons the previous IOU matching or unilateral proportion allocation method, and instead uses the Task-Aligned Assigner matching method.

The framework diagram is provided at the link: Brief summary of YOLOv8 model structure · Issue #189 · ultralytics/ultralytics · GitHub
2. Introduction to wild fire smoke data set
The data set size is 737 images, train:val:test is randomly assigned to 7:2:1, category: smoke

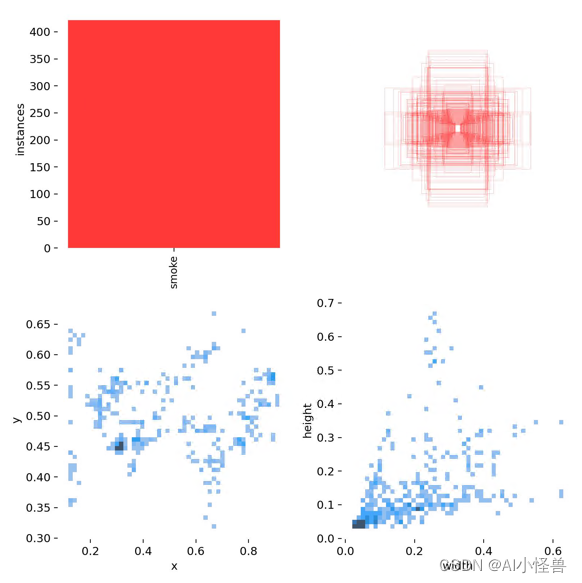
2.1 Data set division
Get trainval.txt, val.txt, test.txt through split_train_val.py
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.7
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()1.2 Get the txt suitable for yolov8 through voc_label.py
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val']
classes = ["smoke"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val']
classes = ["smoke"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()2.3 The generated content is as follows
3. Analysis of training results
The training results are as follows:
[email protected] 0.839
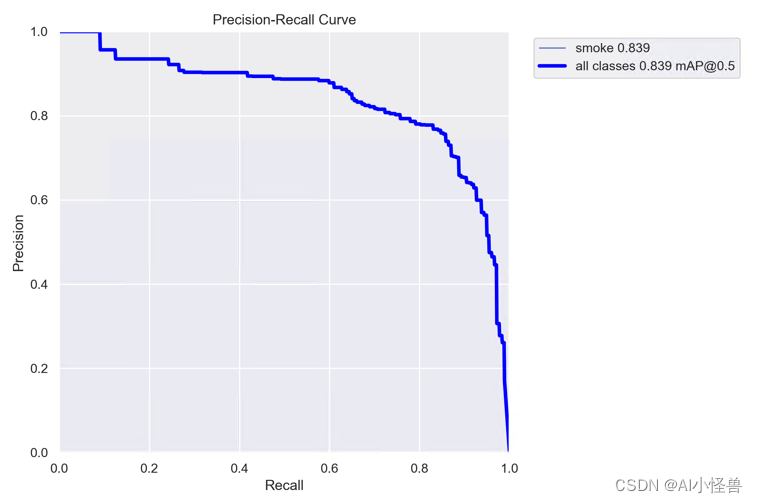
YOLOv8n summary (fused): 168 layers, 3005843 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:06<00:00, 1.55s/it]
all 199 177 0.749 0.859 0.839 0.4694.Series
1) Field smoke detection based on Yolov8