1. Requests library
1. Main usage methods:

1) get() method:

This Response object contains the content returned by the crawler.

Except that the request method is the basic method, everything else is implemented by calling the request method.
Therefore, we can even understand that the Requests library has only one method, the request method. In order to make programming more convenient, there are six other methods.
Take the get method as an example:

2) Properties of Response object:

flow chart:

3) Response encoding:

Resources on the Internet have their own encodings. If we don't know the encoding of the resources, the resources will be unreadable to us.
r.encoding; If charset does not exist in the header, the encoding is considered to be ISO-8859-1.
In principle, the latter is more accurate than the former, because the former does not analyze the content, but only extracts the encoding from the relevant fields in the header to make guesses. The latter actually analyzes the content and finds possible codes.
2. General code framework for crawling web pages:
It is a set of codes that can accurately crawl web content.
We need to know that the get method may not be successful because the network connection is divided, so exception handling is very important for the program.
The Requests library supports six commonly used connection exceptions:


import requests
def ge tHTMLText (ur1) :
try:
r = requests . get (url, timeout =30)
r.raise_ for_ status () #如果状态不是200,引发HTTPError异常
r . encoding = r. apparent encoding
return r. text
except :
return "产生异常”
if __name__==”__main__ " :
url = "http: //www . baidu . com"
print (ge tHTMLText (ur1) )

In other words, the biggest role of the universal code framework is to make it more efficient and stable for users to access or crawl web pages.
3. HTTP protocol operations on resources:
URL is the Internet path for accessing resources through HTTP protocol. One URL corresponds to one data resource.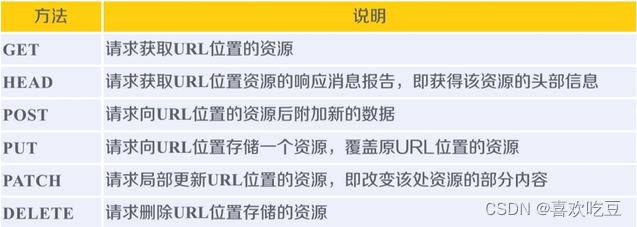
The six methods are the functions corresponding to the six main functions provided by the Requests library.

The HTTP protocol locates resources through URLs and manages resources through these six methods. Each operation is independent and stateless, which means that this operation is not related to the next operation.
In the world of HTTP protocol, network channels and servers are black boxes. All it can see are URL links and operations on URL links.
Understand the difference between PATCH and PUT.
Assume that there is a set of data UserInfo at the URL location, including 20 fields such as UserID and UserName.
Requirement: The user has modified the UserName, leaving everything else unchanged.
Using PATCH, only a partial update request for UserName is submitted to the URL.
With PUT, all 20 fields must be submitted to the URL, and unsubmitted fields are deleted.
The main benefit of PATCH: saving network bandwidth