foreword
Careful observation reveals that more and more people know and learn about reptiles.
Why are Python crawlers so popular?
On the one hand, more and more data can be obtained from the Internet. On the other hand, programming languages like Python provide more and more excellent tools, making crawlers simple and easy to use.
Using crawlers, we can obtain a large amount of valuable data, such as:
Zhihu: Crawl high-quality answers and screen out the best content under each topic for you.
Taobao: Grab product, comment and sales data, and analyze various products and user consumption scenarios.
Anjuke: capture real estate sales and rental information, analyze housing price trends, and analyze housing prices in different regions.
…
A crawler is a great way to get started with Python
Python has many application directions, such as artificial intelligence, web development, data analysis, etc.
[----Help Python learning, all the following learning materials are free at the end of the article! ----】
But the crawler is more friendly to beginners, the principle is simple, a few lines of code can realize the basic crawler, the learning process is smoother, and you can experience a greater sense of accomplishment.
After mastering the basic reptiles, it will be more handy for you to learn Python data analysis, web development and even machine learning. Because in this process, you are very familiar with the basic syntax of Python, the use of libraries, and how to find documents.
For Xiaobai, reptiles may be a very complicated thing with a high technical threshold. But it is not difficult to master the correct method and be able to crawl the data of mainstream websites in a short period of time. Here I will share with you a learning material for a quick introduction to Python crawlers with zero foundation.

This book is divided into basic chapters, intermediate chapters, and in-depth chapters, with a total of 18 chapters and 436 pages. It explains the knowledge and skills required in crawler development from shallow to deep. This book is a book suitable for beginners. It not only explains the basic knowledge points, but also involves the analysis and solution of key problems and difficulties.
Basic
Chapter 1 Review of Python Programming
Install Python
Build a development environment
I/O programming
process and thread
network programming

Chapter 2 Web front-end basics
W3C standard
HTTP standard
summary

Chapter 3 Getting to Know Web Crawlers
Web crawler overview
Python implementation of HTTP requests
summary

Chapter 4 HTML Parsing Dafa
Getting to Know Firebug
regular expression
Powerful BeautifulSoup
summary

Chapter 5 Data Storage (No Database Edition)
HTML text extraction
Multimedia file extraction
Email reminder
summary
Chapter 6 Practical Project: Basic Crawler
Basic crawler architecture and operation process
URL manager
HTML downloader
HTML parser
data storage
crawler scheduler
summary

Chapter 7 Practical Project: Simple Distributed Crawler
Simple distributed crawler structure
control node
crawler node
summary

Intermediate
Chapter 8 Data Storage (Database Edition)
SQLite
MySQL
MongoDB more suitable for crawlers
…

Chapter 9 Dynamic Site Scraping
Ajax and dynamic HTML
Dynamic crawler 1: Crawling movie review information
PhantomJS
Selenium
Dynamic Crawler 1: Crawling Qunar.com
…

Chapter 10 Web Protocol Analysis
Web page login POST analysis
Captcha problem
www>m>wap
…
Chapter 11 Terminal Protocol Analysis
PC client packet capture analysis
APP packet capture analysis
API crawler: crawling mp3 resources

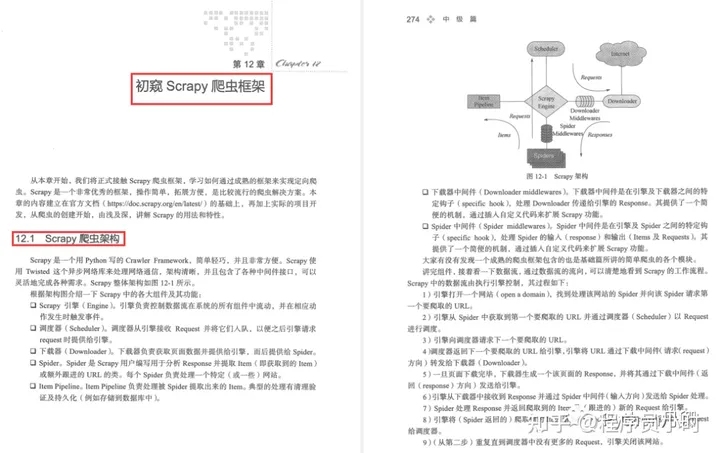
Chapter 12 A first look at the Scrapy crawler framework
Scrapy crawler architecture
Install Scrapy
Create cnblogs project
Create a crawler module
Selector
command line tool
Define Item
page turning function
Build the Item Pipeline
built-in data storage
Built-in picture and file download method
Start the crawler
Enhanced reptiles
…
Chapter 13 In-depth Scrapy crawler framework
Look at Spider again
Item Loader
Look at Item Pipeline again
request and response
Downloader middleware
Spider middleware
expand
Breakthrough Anti-crawler
…


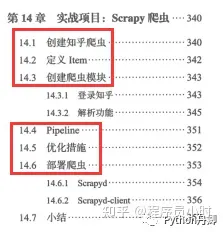
Chapter 14 Practical Project: Scrapy Crawler
Create a Zhihu crawler
Define Item
Create a crawler module
Pipeline
Optimization measures
Deploy the crawler
…
In-depth articles
Chapter 15 Incremental Crawlers
Deduplication program
BloomFilter algorithm
Scrapy and BloomFilter
…

Chapter 16 Distributed Crawlers and Scrapy
Redis Basics
Python and Redis
MongoDB cluster
…
Chapter 17 Project Combat: Scrapy Distributed
Create Yunqi Academy crawler
Define Item
Write a crawler module
Pipeline
Response to anti-reptile mechanism
Deduplication optimization
…

Chapter 18 Humanized PySpider crawler framework
PySpider and Scrapy
Install PySpider
Create Douban crawler
Selector
Ajax and HTTP requests
PySpider and PhantomJS
data storage
PySpider crawler architecture
…

Finally: Learning any language starts from the beginning, through uninterrupted practice to achieve proficiency, and the ultimate goal is mastery. Although everything is difficult at the beginning, a good beginning is half the battle. As long as the direction is right, you will not be afraid of the long road
Friends who need to receive "Python Crawler Development and Project Combat"
Data collection
This full version of the full set of Python learning materials has been uploaded to the official CSDN. If you need it, you can click the CSDN official certification WeChat card below to get it for free ↓↓↓ [Guaranteed 100% free]

Good article recommended
Understand the prospect of python: https://blog.csdn.net/SpringJavaMyBatis/article/details/127194835
Learn about python's part-time sideline: https://blog.csdn.net/SpringJavaMyBatis/article/details/127196603
