Practical exercises (crawling training 1, all news of "http://www.tipdm.org")
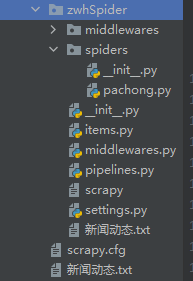
(This is the created crawler folder) This is what it looks like after opening it, there are already various components of the scrapy framework, as long as I write the code, I can crawl.
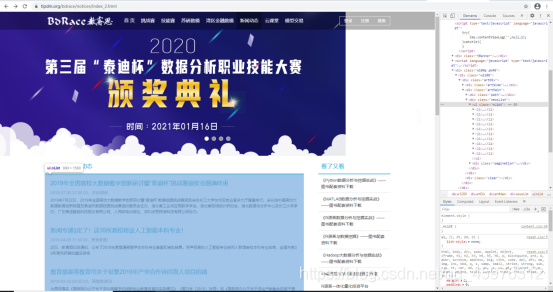
(This is the crawled webpage): The original website (here is locating the tag location)
is to write the crawler file
(1) pachong.spider python file

import scrapy
from zwhSpider.items import ZwhspiderItem
import scrapy
from zwhSpider.items import ZwhspiderItem
class PachongSpider(scrapy.Spider):
name = 'pachong' #爬虫名称
#allowed_domains = ['http://lab.scrapyd.cn']
start_urls = ['https://www.tipdm.org/bdrace/notices/'] #起始url
url='https://www.tipdm.org/bdrace/notices/index_%d.html' #要实现翻页更能,实现全站数据爬取
page_sum=2 #定义页面数
def parse(self, response): #进行全站数据的爬取
div_list = response.xpath('/html/body/div/div[3]/div/div/div[2]/div[2]/ul/li')
for div in div_list:
tit=div.xpath('./div[1]/a/text()')[0].extract() #标题位置
time=div.xpath('./div[2]/span[1]/text()').extract() #时间都位置
contnet=div.xpath('./div[3]//text()').extract() #文本内容的位置
contnet=''.join(contnet)
item=ZwhspiderItem() #将爬到的数据放入item实体,也就是将爬到的数据以item对象返回
item['tit']=tit
item['time']=time
item['contnet']=contnet
yield item
if self.page_sum<=5: #实现翻页功能
new_url=format(self.url%self.page_sum)
self.page_sum+=1
yield scrapy.Request(url=new_url,callback=self.parse)
(2) items.py file

#Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ZwhspiderItem(scrapy.Item):
# define the fields for your item here like:
tit=scrapy.Field()
time=scrapy.Field()
contnet=scrapy.Field()
(3) middlewares.py file (the initial settings does not open middleware)
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
class ZwhspiderSpiderMiddleware: #爬虫中间件
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class ZwhspiderDownloaderMiddleware: #下载中间件
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
#拦截请求
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
#拦截所有的响应
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
#拦截发生异常的请求
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
(4) pipelines.py file (pipeline)

# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ZwhspiderPipeline(object):
fp = None
# 重写父类一个方法:该方法旨在开始爬虫的hi和被调用一次
def open_spider(self, spider):
print("开始爬虫.....")
self.fp = open('./新闻动态.txt', 'w', encoding='utf-8')
# 专门用来处理item类型对象的
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
# 将接收到的item对象中存储的数据进行持久化存储操作(写入本地文件)
tit = item['tit']
time = item['time']
contnet=item['contnet']
self.fp.write(str(tit) +':'+str(time) +':' + str(contnet)+'\n\n')
return item # 就会传递给下一个即将被执行的管道类
def close_spider(self, spider):
print("结束爬虫!")
self.fp.close()
(5) settings.py file

# Scrapy settings for zwhSpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'zwhSpider'
SPIDER_MODULES = ['zwhSpider.spiders']
NEWSPIDER_MODULE = 'zwhSpider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' #url可以定义多个
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #不遵从robots.txt协议
LOG_LEVEL='ERROR' #不爬取无关日志
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'zwhSpider.middlewares.ZwhspiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'zwhSpider.middlewares.ZwhspiderDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'zwhSpider.pipelines.ZwhspiderPipeline': 300, #开启管道
# 300表示的是优先级,数值越小优先级越高
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
Use scrapy crawl pachong to start the crawler
Program running result: It

proves that the crawling is successful. I put the crawled content in the local "
news.txt" file, which is also displayed in the scrapy frame. Let's open this folder in scrapy to see if the crawling is successful .
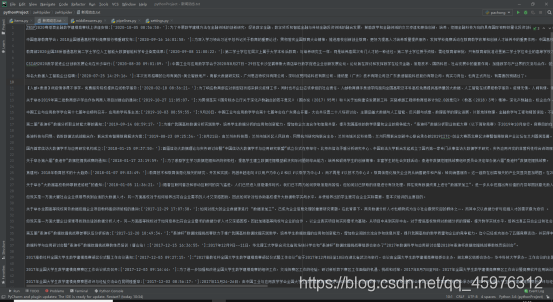
It can be seen that we successfully crawled the content we wanted, and then we saw this folder in the local file;
Open and see what we want.

(This article is only used for simple learning of crawlers, not for any website)