background
Building agnet based on chatglm: Chatglm implements Agent control - Zhihu
Vector retrieval enhanced LLM: vector retrieval enhanced chatglm generation - Zhihu
Large language models (LLMs) have achieved remarkable success and ubiquity in a variety of applications. However, they often fail to capture and acquire factual knowledge. Knowledge graph (KG) is a structured data model that explicitly stores rich factual knowledge. However, knowledge graphs are difficult to construct, and existing methods in knowledge graphs are insufficient to handle the incomplete and dynamically changing nature of real-world knowledge graphs. Therefore, it is natural to combine LLM and KG while playing to the strengths of each.
Although LLMs have had many successful applications, they have been criticized due to lack of factual knowledge. Specifically, LLM memorizes the facts and knowledge contained in the training corpus. However, further research showed that LLMs were unable to recall facts and often had problems with hallucinations, i.e. generating representations with false facts. For example, if you ask LLM: "When did Einstein discover gravity?" it might say: "Einstein discovered gravity in 1687." But in fact, it was Isaac Isaacs who proposed the theory of gravity. Newton. Such problems can seriously damage the credibility of LLM.
LLM has been criticized as a black box model that lacks interpretability. LLM represents knowledge implicitly through parameters. Therefore, it is difficult for us to interpret and verify the knowledge obtained by LLM. Furthermore, LLM performs inference through probabilistic models, which is a non-decisional process. It is difficult for humans to directly obtain details and explanations for the specific modes and functions used by LLM to derive prediction results and decisions.
In order to solve the above problems, a potential solution is to integrate the knowledge graph (KG) into LLM. Knowledge graphs can store huge amounts of facts in the form of triples, namely (head entities, relationships, tail entities), so knowledge graphs are a structured and decisive form of knowledge representation. Examples include Wikidata, YAGO and NELL.

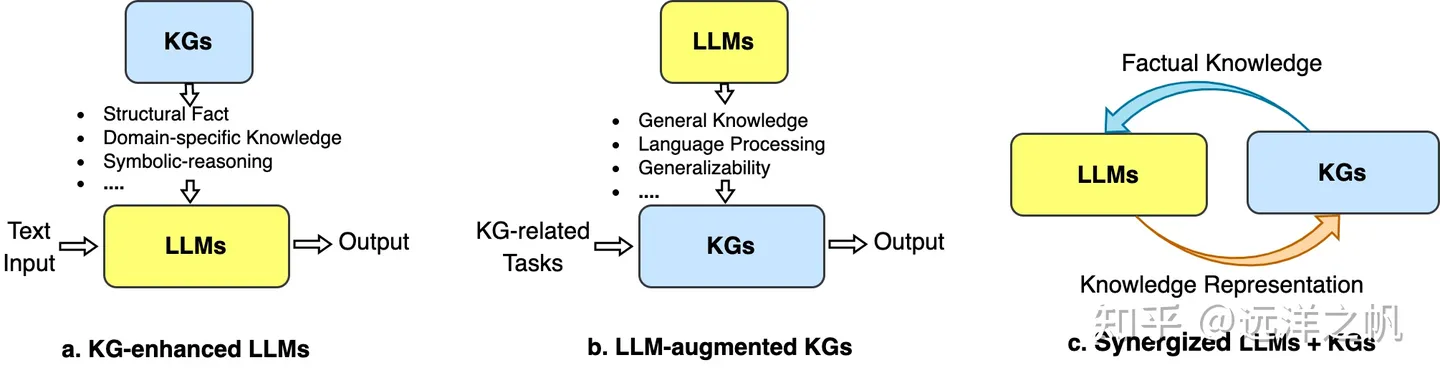
Three general frameworks unify LLM and KG: 1) KG-enhanced LLM, 2) LLM-enhanced KG, and 3) collaborative LLM + KG.

A general framework for collaboration between LLM and knowledge graphs, which contains four layers: data, collaboration model, technology, and application.
This article will introduce how to build an LLM model with strong knowledge extraction capabilities, including how to pretrain the existing LLM, build sft to extract the knowledge graph LLM, and how to encapsulate the knowledge graph LLM into a tool for LLM Agent to use. Later articles will have special articles to introduce how to use the constructed knowledge graph to enhance the LLM model, improve the model's retrieval and intent understanding capabilities, use the knowledge graph to enhance the generation ability of the LLM model, and reduce the probability of phantom writing.
Introduction to technical points
The knowledge extraction model in this article chooses the "intelligent analysis" model. This model is based on llama 13b and uses its own data + public data to pretrain the model, and then uses the instruction corpus to fine-tune the lora on top of the pretrain model.

It has information extraction capabilities, such as named entity recognition (NER), event extraction (EE), and relationship extraction (RE); prompts are provided for easy use, and you can also try to use your own prompts.
The figure below shows the entire training process and data set construction. The entire training process is divided into two stages:
(1) Full pre-training stage. The purpose of this stage is to enhance the model’s Chinese ability and knowledge reserve.
(2) Use the instruction fine-tuning phase of LoRA. This stage enables the model to understand human instructions and output appropriate content.

The Pretrain model is pre-trained on 5500K Chinese samples, 1500K English samples, and 900K code samples. We used the transformers trainer with Deepspeed ZeRO3 (actually using ZeRO2 is slower in a multi-machine and multi-card scenario), and conducted multi-machine and multi-card training on 3 Nodes (eight 32GB V100 cards on each Node).
sft training constructed the instruction data set: For the information extraction (IE) data set, the English part uses open source IE data sets such as CoNLL ACE CASIS to construct the corresponding English instruction data set. Chinese part: Open source data sets such as DuEE, PEOPLE DAILY, DuIE, etc. are used, and the self-constructed KG2Instruction is also used to construct the corresponding Chinese instruction data set. Specifically, KG2Instruction ( InstructIE ) is a Chinese information extraction dataset obtained through remote supervision on Chinese Wikipedia and Wikidata, covering a wide range of fields to meet real extraction needs. Perform multi-card training on 1 Node.
| Dataset type | Number of items |
| COT (Chinese and English) | 202,333 |
| Universal data set (Chinese and English) | 105,216 |
| Code data set (Chinese and English) | 44,688 |
| English instruction extraction data set | 537,429 |
| Chinese instruction extraction data set | 486,768 |
The training part is not the focus of this article. Students who are interested in this part can refer to: https://github.com/zjunlp/KnowLM/blob/main/README_ZH.md
Next, we introduce how to encapsulate this model into a tool for LLM agent to use: 1. Environment deployment 2. Encapsulation service.
#环境部署
#下载智析项目代码
git clone https://github.com/zjunlp/KnowLM.git
cd KnowLM
#下载zhixi fp16模型参数
python tools/download.py --download_path ./zhixi-diff-fp16 --only_base --fp16
#下载llama参数
git clone https://huggingface.co/huggyllama/llama-13b
#把zhixi模型参数和llama参数做数值合并得到实际可用的zhixi推理参数“./converted”这个地址换成llama参数地址
python tools/weight_diff.py recover --path_raw ./converted --path_diff ./zhixi-diff-fp16 --path_tuned ./zhixi --is_fp16 True
#指令微调后的lora参数下载
python tools/download.py --download_path ../lora --only_loraPackaging services:
#封装prompt模版
import sys
import json
import fire
import os.path as osp
from typing import Union
import torch
import transformers
from peft import PeftModel
from transformers import GenerationConfig, LlamaForCausalLM, LlamaTokenizer
class Prompter(object):
__slots__ = ("template", "_verbose")
def __init__(self, template_name: str = "", verbose: bool = False):
self._verbose = verbose
# file_name = osp.join("templates", f"{template_name}.json")
file_name = template_name
if not osp.exists(file_name):
raise ValueError(f"Can't read {file_name}")
with open(file_name) as fp:
self.template = json.load(fp)
if self._verbose:
print(
f"Using prompt template {template_name}: {self.template['description']}"
)
def generate_prompt(
self,
instruction: str,
input: Union[None, str] = None,
label: Union[None, str] = None,
) -> str:
# returns the full prompt from instruction and optional input
# if a label (=response, =output) is provided, it's also appended.
if input:
res = self.template["prompt_input"].format(
instruction=instruction, input=input
)
else:
res = self.template["prompt_no_input"].format(
instruction=instruction
)
if label:
res = f"{res}{label}"
if self._verbose:
print(res)
return res
def get_response(self, output: str) -> str:
return output.split(self.template["response_split"])[1].strip()
#封装tool
from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig
import torch
from typing import Optional, Type
from langchain.base_language import BaseLanguageModel
from langchain.tools import BaseTool
from langchain.callbacks.manager import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
class functional_Tool(BaseTool):
name: str = ""
description: str = ""
url: str = ""
def _call_func(self, query):
raise NotImplementedError("subclass needs to overwrite this method")
def _run(
self,
query: str,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
return self._call_func(query)
async def _arun(
self,
query: str,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
) -> str:
raise NotImplementedError("APITool does not support async")
class LLM_KG_Generator(functional_Tool):
model: LlamaForCausalLM #BaseLanguageModel
tokenizer:LlamaTokenizer
max_length:int
prompter:Prompter
def _call_func(self, query) -> str:
#self.get_llm_chain()
self.model.config.pad_token_id = self.tokenizer.pad_token_id = 0 # same as unk token id
self.model.config.bos_token_id = self.tokenizer.bos_token_id = 1
self.model.config.eos_token_id = self.tokenizer.eos_token_id = 2
prompter = self.prompter
prompt_temple = "我将给你个输入,请根据事件类型列表:['旅游行程'],论元角色列表:['旅游地点', '旅游时间', '旅游人员'],从输入中抽取出可能包含的事件,并以(事件触发词,事件类型,[(事件论元,论元角色)])的形式回答。"
prompt = prompter.generate_prompt(prompt_temple,query)
inputs = self.tokenizer(prompt, return_tensors="pt")
input_ids = inputs["input_ids"].to("cuda")
s = self.model.generate(input_ids,max_length=self.max_length)
resp = self.tokenizer.decode(s[0])
return resp
#测试例子
model = LlamaForCausalLM.from_pretrained(
"/root/autodl-tmp/KnowLM/zhixi",
load_in_8bit=False,
torch_dtype=torch.float16,
device_map="auto",
)
tokenizer = LlamaTokenizer.from_pretrained("/root/autodl-tmp/llm_model/llama-13b-hf")
prompter = Prompter("../finetune/lora/templates/alpaca.json")
KG_tool = LLM_KG_Generator(model = model,tokenizer = tokenizer,max_length =4096,prompter = prompter )
input="John昨天在纽约的咖啡馆见到了他的朋友Merry。他们一起喝咖啡聊天,计划着下周去加利福尼亚(California)旅行。他们决定一起租车并预订酒店。他们先计划在下周一去圣弗朗西斯科参观旧金山大桥,下周三去洛杉矶拜访Merry的父亲威廉。"
KG_tool.run(input)
#和llm agent配合使用
from langchain.agents import AgentExecutor
from custom_search import DeepSearch
from tool_set import *
from intent_agent imprt IntentAgent
from llm_model import ChatGLM
#model_path换成自己的模型地址
llm = ChatGLM(model_path="/root/autodl-tmp/ChatGLM2-6B/llm_model/models--THUDM--chatglm2-6b/snapshots/8eb45c842594b8473f291d0f94e7bbe86ffc67d8")
llm.load_model()
agent = IntentAgent(tools=tools, llm=llm)
tools = [KG_tool]
agent_exec = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, max_iterations=1)
agent_exec.run(input)Here are the results generated by the test example:

Theoretically, the above extracted knowledge can be stored in various graph databases, such as neo4j, gstore, TuGraph... When the business needs to use knowledge, the required relevant information can be found from the graph database through the entered search terms. Knowledge, as context or through knowledge, is used to build a reasoning strategy for the LLM model to generate the final answer.
summary
1. Introduced three modes of combining LLM and KG: LLM enhances KG's ability to extract and construct knowledge graphs, KG enhances LLM's retrieval and generation reasoning capabilities, and KG and LLM collaborate
2. Introducing the "Smart Analysis" project to explain the LLM enhanced KG extraction model and the two processes required to build the model: pretrain, sft, and the data required for pretrain and the instruction set required for sft.
3. Introduced how to encapsulate "intelligent analysis" into a tool and become a tool for LLM agent to build an application ecosystem.
4. Theoretically speaking, the knowledge construction process is time-consuming, but it can be built in advance. When the knowledge needs to be used, the knowledge graph can be retrieved and recalled to build various application scenarios. Of course, the user input can also be used to build knowledge instantly during semantic understanding. Improve intention understanding
Project code: https://github.com/liangwq/Chatglm_lora_multi-gpu/tree/main/APP_example/chatglm_agent