Una descripción general de la arquitectura de gráficos móviles moderna
Los SoC modernos suelen integrar tanto CPU como GPU.
La CPU se utiliza para procesar conjuntos de datos secuenciales y muy ramificados que requieren una baja latencia de memoria, y sus transistores se utilizan para el control de flujo y el almacenamiento en caché de datos.
Las GPU están diseñadas para procesar conjuntos de datos grandes y no ramificados, como la renderización 3D. Los transistores están dedicados a registros y unidades lógicas aritméticas, no al almacenamiento en caché de datos ni al control de flujo.

Arquitectura de sombreador unificado de GPU y arquitectura de sombreador no unificado
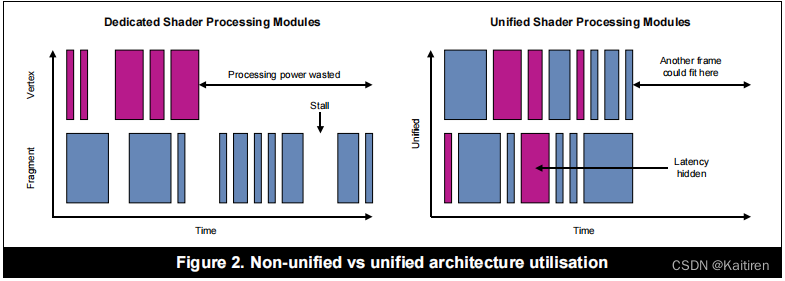
En las primeras GPU, las estructuras de hardware de los sombreadores de vértices y de píxeles eran independientes, cada una con sus propios registros, unidades aritméticas y otros componentes. Sin embargo, VS y PS independientes inevitablemente causarán un desequilibrio relativo. Por ejemplo, cuando un modelo está lejos, tiene más demanda de VS y menos demanda de PS. Cuando está cerca, ocurre lo contrario. El desequilibrio inevitablemente causará redundancia. Yu, para resolver el desequilibrio entre VS y PS, se introdujo la arquitectura de sombreado unificada. Los VS y PS de la GPU de esta arquitectura utilizan el mismo Core. Es decir, un mismo Core puede ser tanto VS como PS. , la siguiente figura muestra las ventajas de rendimiento y consumo de energía de la arquitectura de sombreado unificada en comparación con la arquitectura no unificada.
Arquitectura inmediata de GPU
La arquitectura de las GPU de escritorio generalmente se denomina arquitectura inmediata. La arquitectura Inmediata procesa la renderización como un flujo de instrucciones estricto, ejecutando sombreadores de vértices y fragmentos secuencialmente en cada primitiva en cada Draw Call. , cada objeto pasa inmediatamente a través de la canalización tan pronto como se envía, transformándose, rasterizándose y sombreándose antes de procesar el siguiente objeto. Las desventajas de esta arquitectura son obvias. Los objetos dibujados primero pueden ser sobrescritos por objetos posteriores, provocando que se produzca "Sobredibujo". Para evitar este fenómeno, las arquitecturas inmediatas modernas utilizan la tecnología Early-Z para mapear objetos en la escena. Ordenar para reducir la ocurrencia de Sobregiro.
Haciendo caso omiso del procesamiento paralelo y las canalizaciones, el siguiente pseudocódigo es un ejemplo de alto nivel de esta arquitectura:
for draw in renderPass:
for primitive in draw:
for vertex in primitive:
execute_vertex_shader(vertex)
if primitive not culled:
for fragment in primitive:
execute_fragment_shader(fragment)La siguiente figura es el diagrama de flujo de la tubería IMR:

La siguiente figura muestra la interacción entre el flujo de datos de la GPU y la memoria.

Ventajas de la arquitectura inmediata
La salida de los sombreadores de vértices y otros sombreadores relacionados con la geometría se puede almacenar en un búfer FIFO como se muestra arriba hasta que la siguiente etapa (PS) de la canalización esté lista para usar los datos. Podemos ver que durante el proceso VS->PS, la GPU usa muy poco ancho de banda de memoria, lo que también es la ventaja de esta arquitectura.
Desventajas de la arquitectura inmediata
Como se mencionó anteriormente, la arquitectura inmediata usa muy poco ancho de banda de memoria durante el proceso VS->PS, pero ocurre lo contrario durante el proceso PS->Framebuffer. Cada triángulo en la secuencia puede cubrir cualquier parte de la pantalla, lo que significa que el conjunto de trabajo de Framebuffer debe tener el tamaño de todo el framebuffer. Por ejemplo, un dispositivo de 1440p utiliza 32 bits para representar el color y 32 bits para representar la profundidad/búfer de plantilla. Entonces el tamaño del FWS es extremadamente de 30 MB. Por supuesto, un FWS tan grande no se puede guardar en el chip, por lo que solo se puede almacenado en la memoria. , entonces la GPU debe realizar una operación de lectura y escritura en la memoria cada vez que se realiza una prueba de profundidad/plantilla. Dado que cada fragmento tiene múltiples operaciones de lectura, modificación y escritura, la carga en el ancho de banda de la memoria es muy alta en este escenario.
Arquitectura basada en mosaicos de GPU
El llamado Tile es el proceso de convertir datos geométricos en un área rectangular pequeña. La rasterización y el procesamiento de fragmentos se realizan por mosaico. El propósito del renderizado basado en mosaicos es minimizar la cantidad de acceso a la memoria externa requerida por la GPU durante el sombreado de fragmentos, ahorrando así ancho de banda de la memoria. TBR divide la pantalla en mosaicos y fragmenta cada mosaico antes de escribirlo en la memoria. Para lograr esto, la GPU debe saber de antemano qué geometría pertenece a este mosaico, por lo que TBR divide cada paso de renderizado en dos pasos de procesamiento:
- La primera pasada realiza todo el procesamiento relacionado con la geometría y genera una lista de primitivas específica del mosaico, que indica qué primitivas están dentro del mosaico.
- La segunda pasada rasteriza y fragmenta mosaico por mosaico y lo vuelve a escribir en la memoria una vez finalizado.
El siguiente es el pseudocódigo de TBR:
python
# Pass one
for draw in renderPass:
for primitive in draw:
for vertex in primitive:
execute_vertex_shader(vertex)
if primitive not culled:
append_tile_list(primitive)
# Pass two
for tile in renderPass:
for primitive in tile:
for fragment in primitive:
execute_fragment_shader(fragment)La siguiente figura muestra el proceso básico de TBR.

La siguiente figura muestra el flujo de datos del hardware del TBR y la interacción con la memoria:

Ventajas de TBR
1. Ahorra ancho de banda
La principal ventaja de TBR es que los mosaicos solo ocupan una pequeña porción del Framebuffer. Por lo tanto, todo el conjunto de trabajo de color, profundidad y plantillas de mosaicos se puede almacenar en un chip que está estrechamente acoplado al núcleo de sombreado de la GPU. Por lo tanto, los datos de Framebuffer requeridos por la GPU para realizar pruebas de profundidad y combinar clips transparentes no necesitan leerse ni escribirse desde la memoria varias veces, lo que mejora el rendimiento y ahorra consumo de energía.
Además, parte del búfer de profundidad/plantilla solo necesita existir durante el proceso de sombreado y no es necesario volver a escribirlo en la memoria. TBR puede optar por descartar esta parte del contenido para reducir aún más el uso de ancho de banda (llame a glDiscardFramebufferEXT en OpenGL ES 2.0, glInvalidateFramebuffer en OpenGL ES 3.0 O use storeOp de render pass en Vulkan para realizar configuraciones específicas)
2. Facilita la implementación de algunos algoritmos.
TBR habilita algunos algoritmos que de otro modo serían demasiado costosos desde el punto de vista computacional o utilizarían un ancho de banda excesivo.
El mosaico es lo suficientemente pequeño como para que se puedan almacenar suficientes muestras localmente en la memoria para implementar MSAA. Por lo tanto, el hardware puede resolver múltiples muestras mientras el mosaico se vuelve a escribir en la memoria, sin la necesidad de realizar pases de resolución separados.
El Defer-Rendering tradicional utilizaría el renderizado de destino de renderizado múltiple (MRT) para implementar la iluminación diferida, escribiendo múltiples valores intermedios para cada píxel en la memoria principal y luego releyéndolos en una segunda pasada. Defer-Rendering se puede optimizar en TBR, donde el sombreador de fragmentos accede mediante programación a los valores almacenados en el framebuffer por fragmentos anteriores.
Problemas de TBR con PowerVR TBDR
Aunque TBR mejora el diseño de IMR, esencialmente no resuelve OverDraw. A medida que se renderiza cada mosaico, la geometría se procesa en el orden de envío. Los fragmentos que se ocluyerán se seguirán procesando, lo que dará lugar a cálculos de color y extracción de datos de textura redundantes. Las técnicas Early-Z se pueden utilizar para reducir el sobregiro, pero al igual que con IMR, la aplicación debe realizar la secuenciación.
PowerVR agrega un paso llamado HSR (eliminación de superficie oculta) después de la rasterización. El principio general es el siguiente:
Cuando un píxel pasa por Early-Z y está listo para ser dibujado por PS, no se dibuja primero, solo registra a qué primitivo pertenece el píxel para dibujar. Espere hasta que se hayan procesado todas las primitivas de este mosaico y finalmente comience a dibujar los píxeles marcados en cada primitiva que se puede dibujar.
Dado que todas las operaciones se realizan en el chip, el costo es mínimo y, en última instancia, se logra cero sobregiro.