Article directory
Preface
After playing stable diffusionwith webUI and comfyUI, I thought about 微调a personalized checkpoint, LyCORIS or LoRA.
Be prepared to have your mentality shattered by environmental issues.
My old computer had a 4G GPU and it jumped three times.
If you don’t have a good computer, it’s better not to make the model yourself. It takes time and money, and if the GPU is not enough, it will definitely not work.
Prepare environment
python: 3.10.9 (official recommendation), the official emphasizes that it must not be 3.11+ , otherwise it will not run.
Prepare pictures
You probably need to prepare 10-20 pictures.
Here we use Andy Lau’s picture:
https://stable-diffusion-art.com/wp-content/uploads/2023/09/lora_training_captions.zip

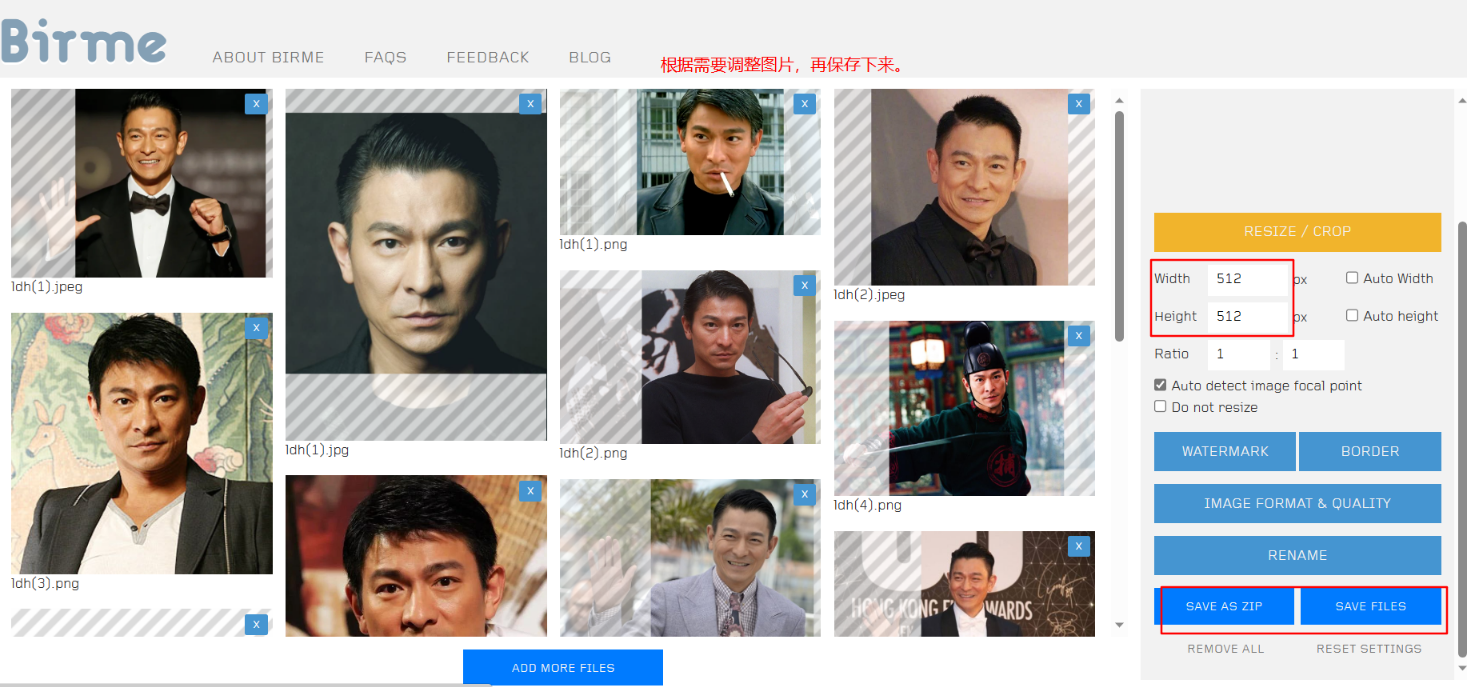
Process pictures
This is an online image processing website: https://www.birme.net/
Download kohya_ss code
https://github.com/bmaltais/kohya_ss#setup
git clone https://github.com/bmaltais/kohya_ss.git
After downloading, open cmd in the directory and
run:
.\setup.bat
During the installation process, there will be error messages. For example, in my installation message below, there will be an error.
At this time, we can install them separately.
My installation information is as follows:
07:30:01-098969 INFO Python 3.10.9 on Windows
07:30:01-114591 INFO nVidia toolkit detected
07:30:22-313445 INFO Torch 2.0.1+cu118
07:30:27-317148 INFO Torch backend: nVidia CUDA 11.8 cuDNN 8700
07:30:27-524602 INFO Torch detected GPU: NVIDIA GeForce GTX 960M VRAM 4096 Arch (5, 0) Cores 5
07:30:27-546322 INFO Installing modules from requirements_windows_torch2.txt...
07:30:27-571730 INFO Installing package: torch==2.0.1+cu118 torchvision==0.15.2+cu118 --index-url
https://download.pytorch.org/whl/cu118
07:30:31-836436 INFO Installing package: xformers==0.0.21
07:31:57-013124 INFO Installing package: bitsandbytes==0.35.0
07:32:51-316790 INFO Installing package: tensorboard==2.12.3 tensorflow==2.12.0
07:37:59-014316 ERROR Error running pip: install --upgrade tensorboard==2.12.3 tensorflow==2.12.0
07:37:59-014316 INFO Installing modules from requirements.txt...
07:37:59-014316 WARNING Package wrong version: accelerate 0.23.0 required 0.19.0
07:37:59-014316 INFO Installing package: accelerate==0.19.0
07:38:03-229388 INFO Installing package: aiofiles==23.2.1
07:38:06-751172 INFO Installing package: altair==4.2.2
07:38:38-267155 INFO Installing package: dadaptation==3.1
07:38:51-524642 INFO Installing package: diffusers[torch]==0.18.2
07:38:59-209713 INFO Installing package: easygui==0.98.3
07:39:02-399649 WARNING Package wrong version: einops 0.6.1 required 0.6.0
07:39:02-415277 INFO Installing package: einops==0.6.0
07:39:06-136609 INFO Installing package: fairscale==0.4.13
07:39:25-893111 INFO Installing package: ftfy==6.1.1
07:39:29-690634 INFO Installing package: gradio==3.36.1
07:40:36-392666 WARNING Package wrong version: huggingface-hub 0.17.2 required 0.15.1
07:40:36-400190 INFO Installing package: huggingface-hub==0.15.1
07:40:40-941236 INFO Installing package: invisible-watermark==0.2.0
07:41:24-129685 INFO Installing package: lion-pytorch==0.0.6
07:41:30-507921 INFO Installing package: lycoris_lora==1.8.3
07:41:37-013021 INFO Installing package: open-clip-torch==2.20.0
07:41:50-051513 INFO Installing package: opencv-python==4.7.0.68
07:42:25-089723 INFO Installing package: prodigyopt==1.0
07:42:28-598267 INFO Installing package: pytorch-lightning==1.9.0
07:42:38-209014 WARNING Package wrong version: rich 13.5.3 required 13.4.1
07:42:38-215011 INFO Installing package: rich==13.4.1
07:42:43-854357 WARNING Package wrong version: safetensors 0.3.3 required 0.3.1
07:42:43-860357 INFO Installing package: safetensors==0.3.1
07:42:48-383515 INFO Installing package: timm==0.6.12
07:42:54-170484 INFO Installing package: tk==0.1.0
07:42:57-803992 INFO Installing package: toml==0.10.2
07:43:01-527071 WARNING Package wrong version: transformers 4.33.2 required 4.30.2
07:43:01-533037 INFO Installing package: transformers==4.30.2
07:43:24-744913 INFO Installing package: voluptuous==0.13.1
07:43:29-529060 INFO Installing package: wandb==0.15.0
Modify pyvenv.cfg
My path: E:\openai\project\kohya_ss\venv
I habitually change to true. The reasons are: 1. To save space, and 2. There is no need to install modules that have been installed again.
include-system-site-packages = true
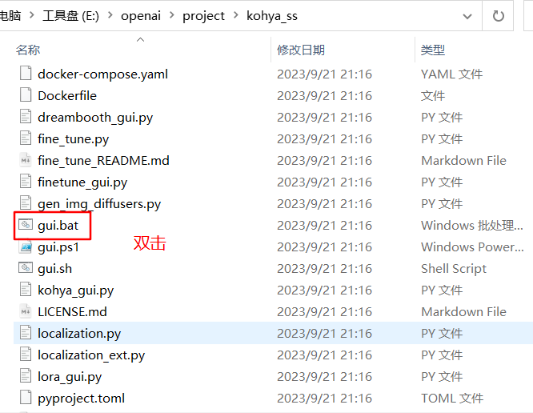
Start interface
In kohya_ssthe directory, double-click gui.batthe file to start.
address
This address is the same as the stable diffusion webUI.
Generate subtitles
Open the page we started:
Path: Utilities – Captioning – BLIP Captioning( WD14 Captioningcan also be used)
Select the folder, select the folder where we processed the pictures,
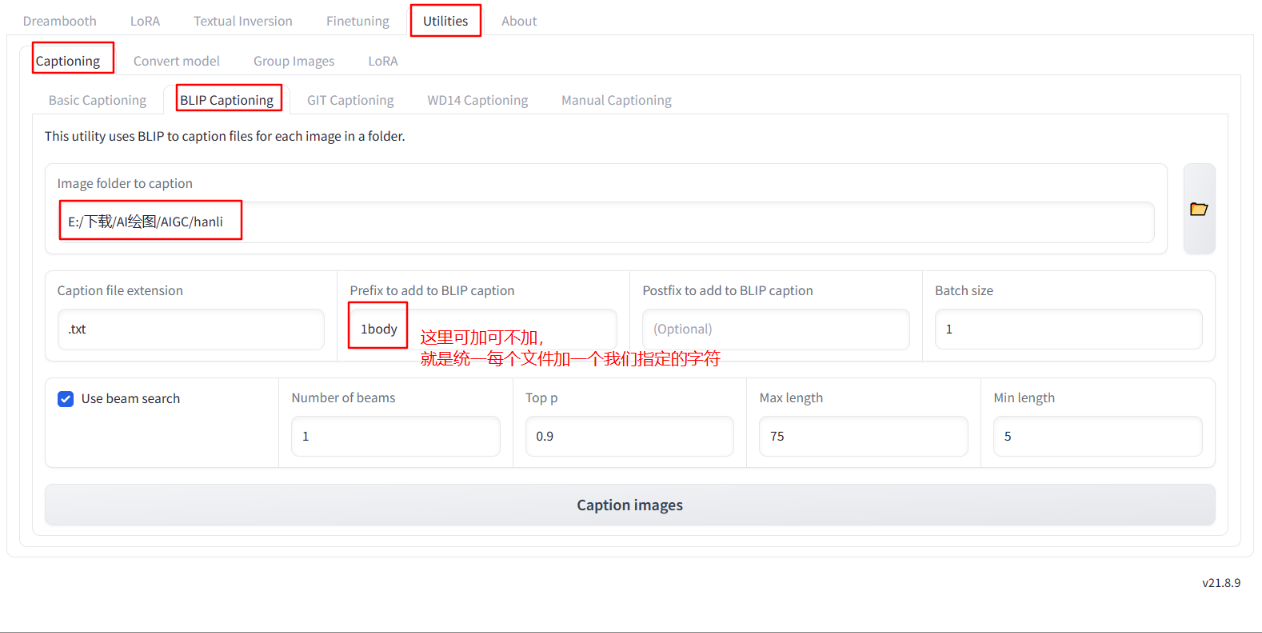
and finally click: Caption images. It can help us generate subtitles.
The log printed in the command line is as follows:
To create a public link, set `share=True` in `launch()`.
19:29:13-558295 INFO Captioning files in E:/下载/AI绘图/AIGC/hanli...
19:29:13-561260 INFO ./venv/Scripts/python.exe "finetune/make_captions.py" --batch_size="1" --num_beams="1"
--top_p="0.9" --max_length="75" --min_length="5" --beam_search --caption_extension=".txt"
"E:/下载/AI绘图/AIGC/hanli"
--caption_weights="https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/mode
l_large_caption.pth"
Current Working Directory is: E:\openai\project\kohya_ss
load images from E:\下载\AI绘图\AIGC\hanli
found 13 images.
loading BLIP caption: https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_large_caption.pth
Downloading (…)solve/main/vocab.txt: 100%|███████████████████████████████████████████| 232k/232k [00:00<00:00, 360kB/s]
Downloading (…)okenizer_config.json: 100%|██████████████████████████████████████████████████| 28.0/28.0 [00:00<?, ?B/s]
Downloading (…)lve/main/config.json: 100%|████████████████████████████████████████████████████| 570/570 [00:00<?, ?B/s]
100%|█████████████████████████████████████████████████████████████████████████████| 1.66G/1.66G [09:01<00:00, 3.30MB/s]
load checkpoint from https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_large_caption.pth
BLIP loaded
100%|██████████████████████████████████████████████████████████████████████████████████| 13/13 [00:30<00:00, 2.36s/it]
done!
19:41:08-386110 INFO ...captioning done
It can be seen that it downloaded a 1.6G file. This problem exists in the path: C:\Users\yutao\.cache\torch\hub\checkpoints\model_large_caption.pth
it can be seen that it is stored on the C drive, which is very unfriendly.
Generate subtitles, the effect is as follows:
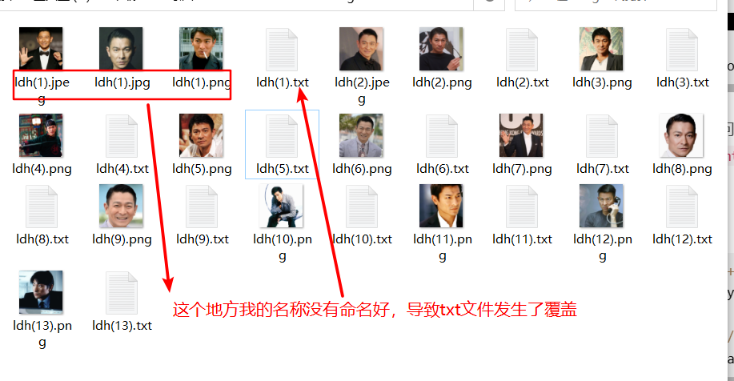
Open any one:

Folder to prepare for training
Set a folder to prepare for training.
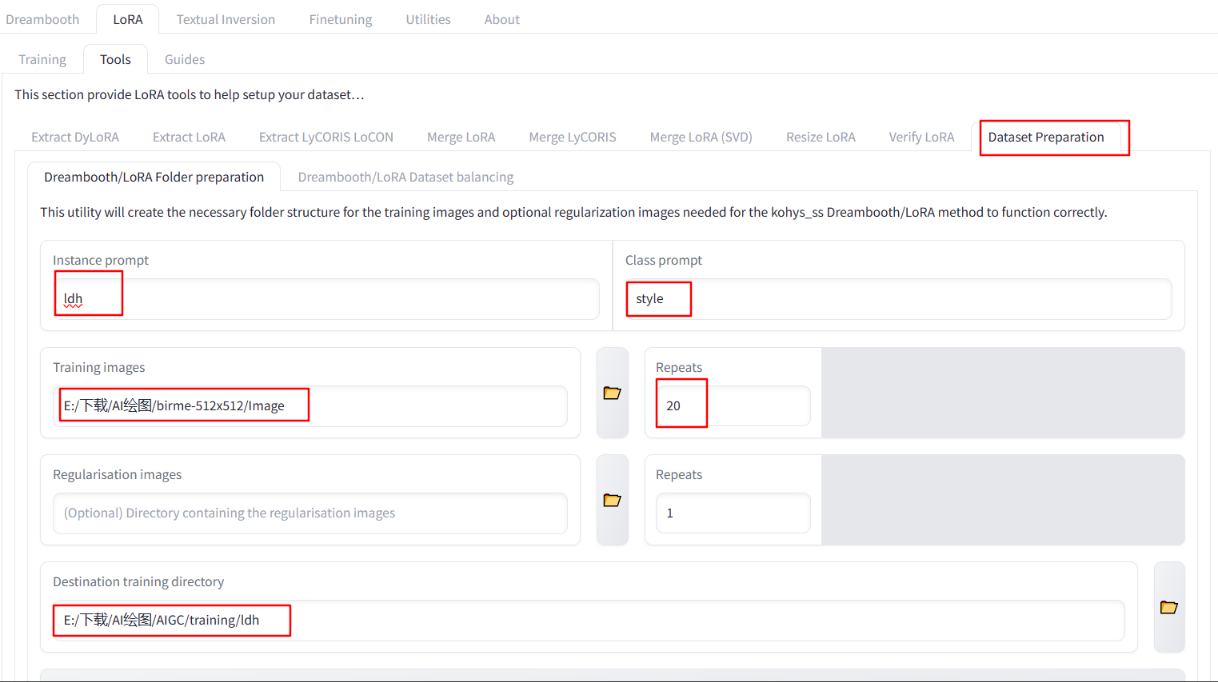
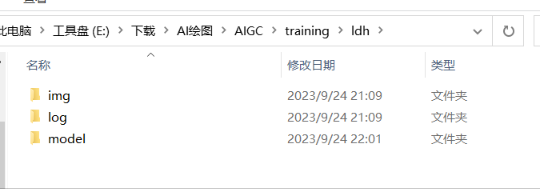
Clicking Prepare training datathe button will generate a folder as shown below:
Configure training parameters
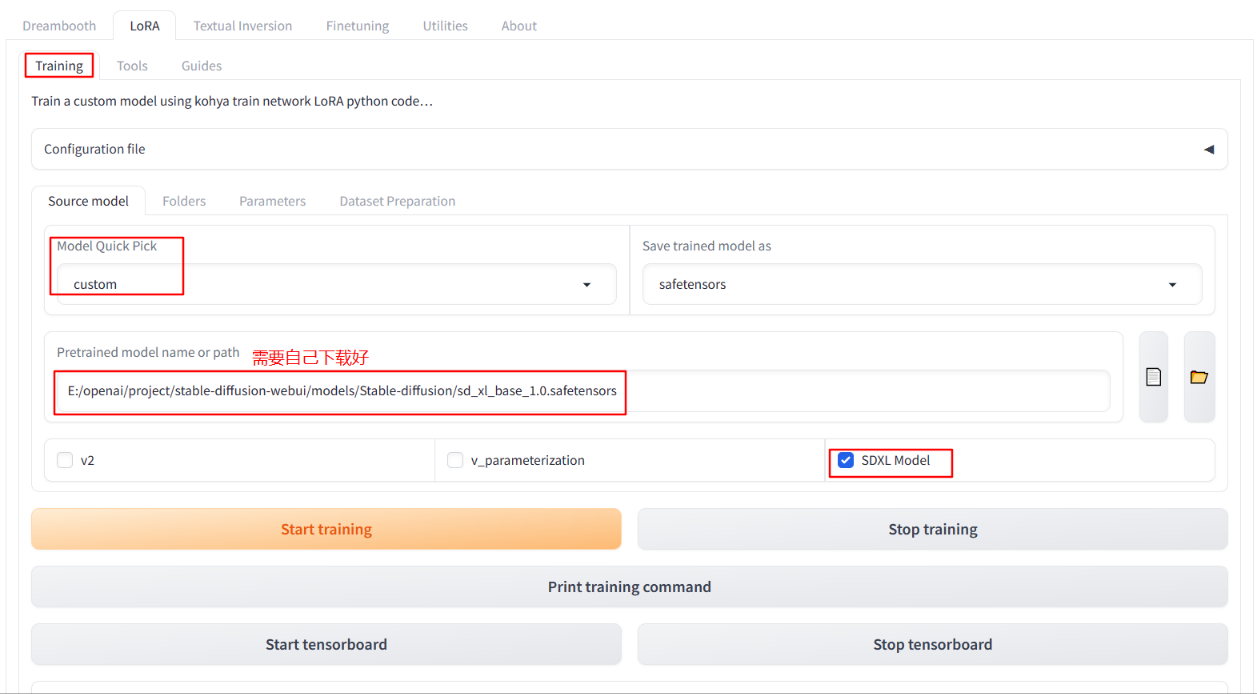
Path: LoRa – Training – source model
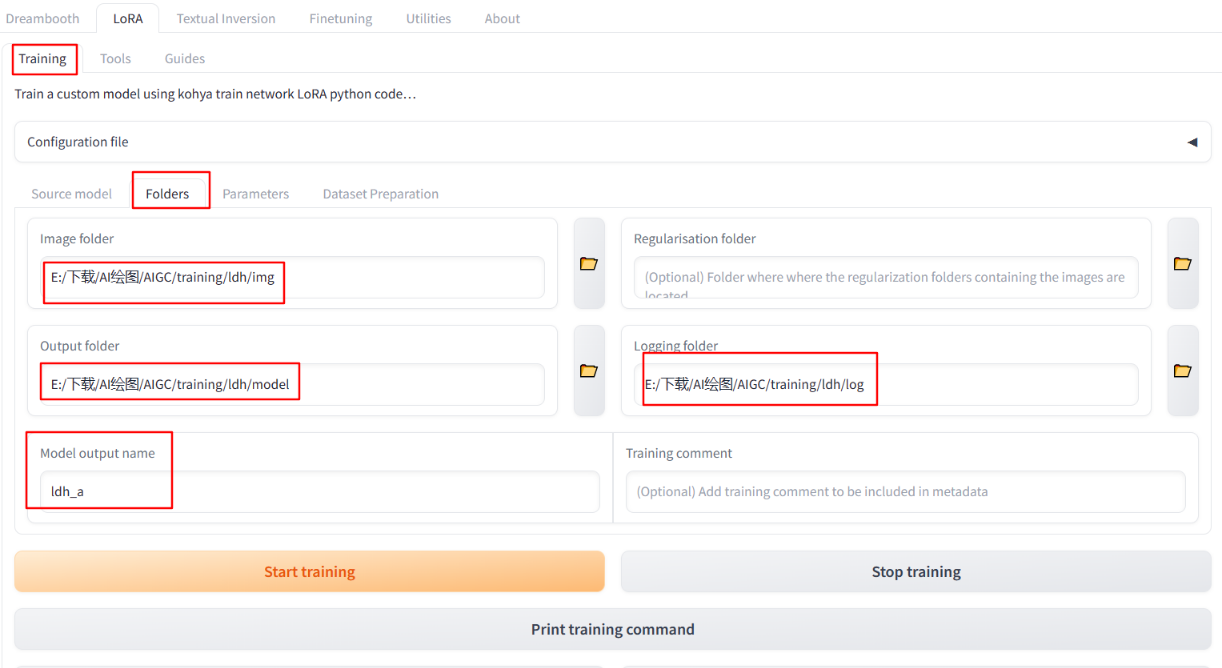
Path: LoRa – Training – Folders
Path: LoRa – Training – parameters – basic
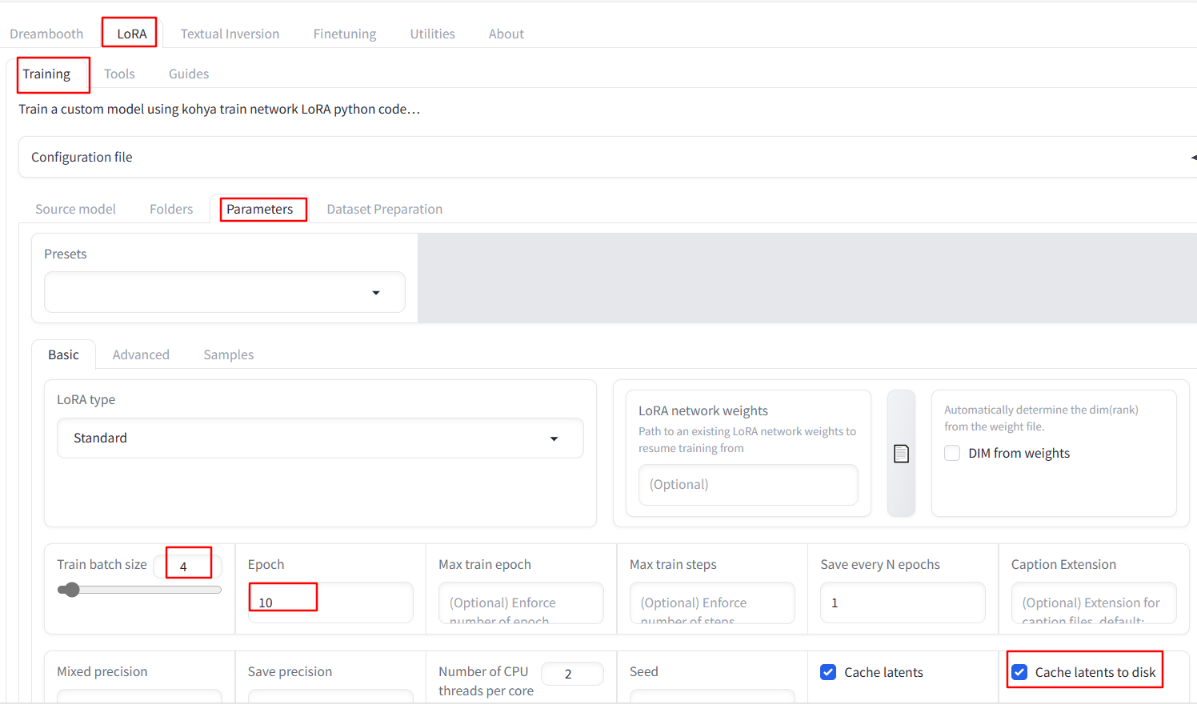
parameter:
Optimizer extra arguments : scale_parameter=False relative_step=False warmup_init=False
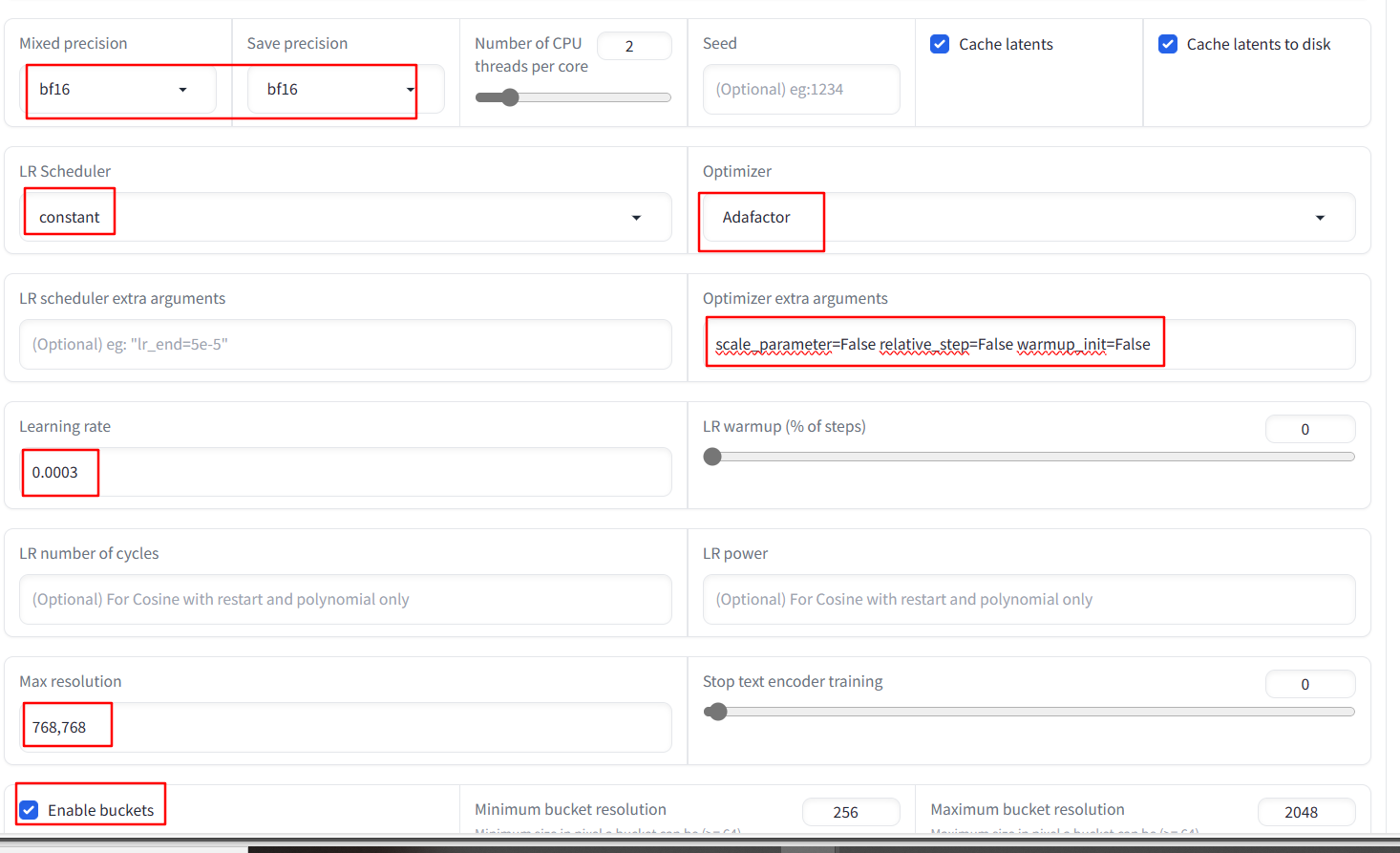
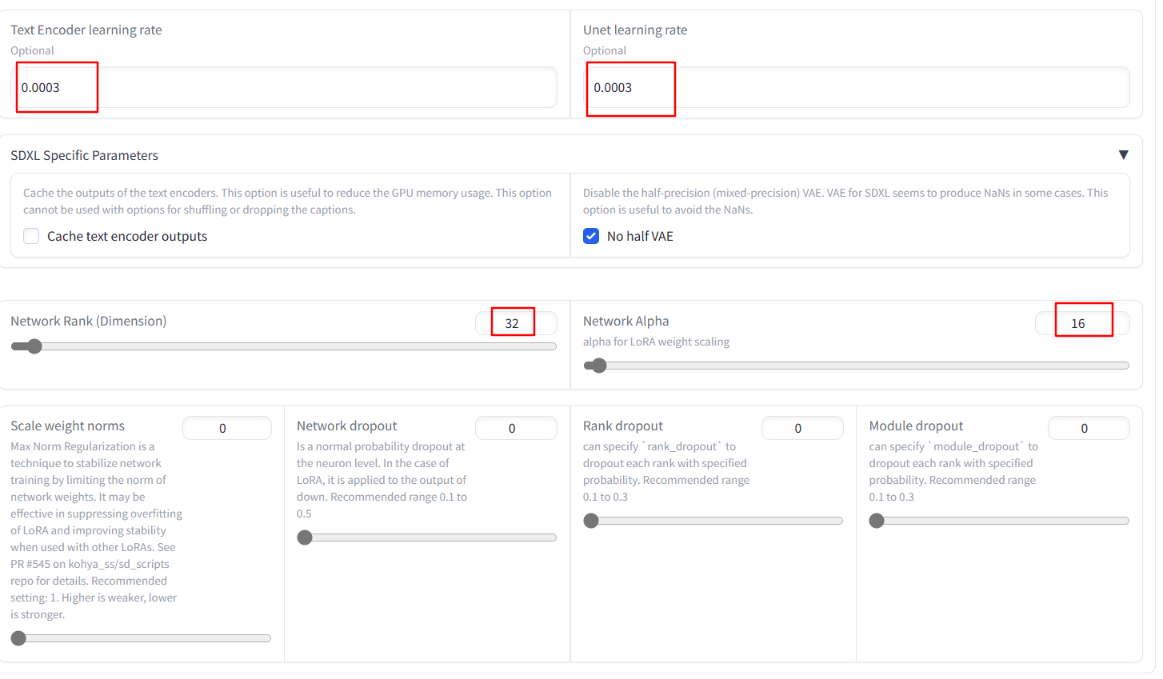
Path: LoRa – Training – parameters – advanced
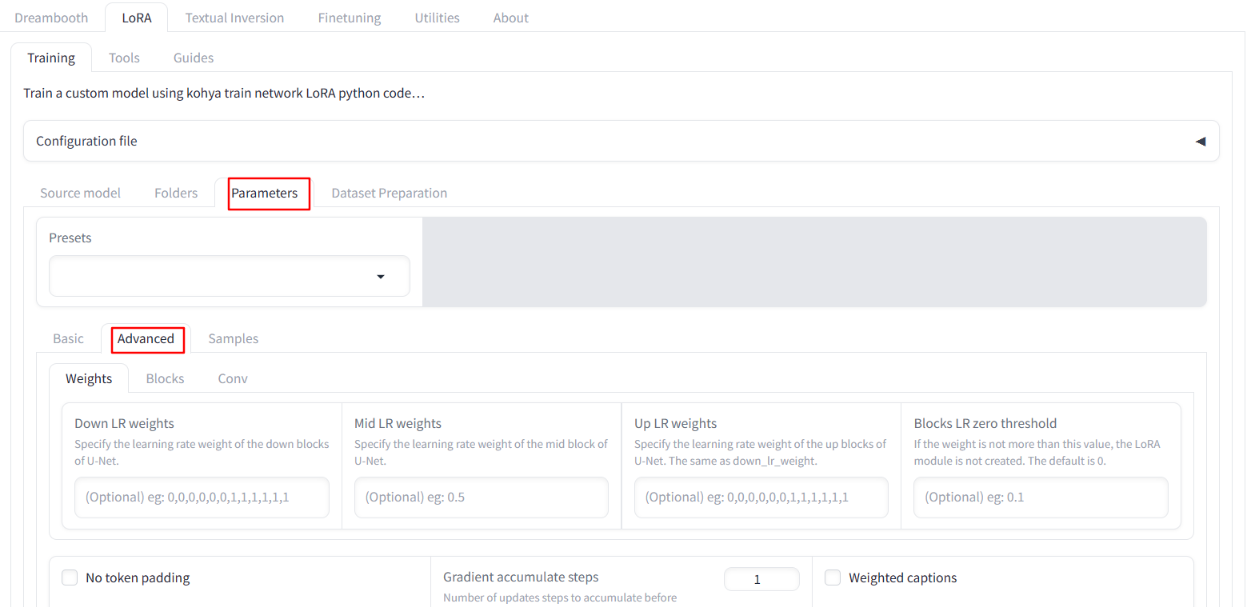
Parameter description: LoRA-training-parameters
Start training
Click "Start training" to start training.
Problems encountered:
Here I encountered a warning :
WARNING[XFORMERS]: xFormers can't load C++/CUDA extensions. xFormers was built for:
PyTorch 2.0.1+cu118 with CUDA 1108 (you have 2.0.1+cpu)
Python 3.10.11 (you have 3.10.9)
Please reinstall xformers (see https://github.com/facebookresearch/xformers#installing-xformers)
Memory-efficient attention, SwiGLU, sparse and more won't be available.
The above means that CUDAit cannot be used, which means that we cannot call the GPU to run, we can only call the CPU to run.
Execute the following command:
pip uninstall -y torch torchvision torchaudio
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
can be solved
Reference address:
SDXL LORA Training locally with Kohya