Train your classifier model
运行环境为(在1.10及以上版本会出现cudnn无法初始化问题):
tensorflow-1.9-gpu
ubuntu16.0.4
gtx1080x2
- Data is structured as follows:
dataset
│ ├── class1
│ │ ├── class1.jpg
│ │ ├── ...
│ │ └── classn.jpg
│ ├── class2
│ │ ├── class2.jpg
│ │ ├── ...
│ │ ├── classn.jpg
The best data set on the dataset directory, otherwise generate tfrecord code needs to be modified.
In download_and_convert_data.pyadding support for new data set (where the new data set is pocmans, download the script is written because the handling of different data sets , you need to add support for new raw data).
elif FLAGS.dataset_name == 'pocmans'
In the dataset directory is added download_and_convert_pocmans.py, flowers script contains a download, convert tfrecord, clear temporary files. The data presented here has been so good to download the code is not required. Modify the code as follows (the following code import dataset_utilsneed to add pocmanssupport datasets):
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import math
import os
import random
import sys
import tensorflow as tf
from datasets import dataset_utils
# The number of images in the validation set.
_NUM_VALIDATION = 150
# Seed for repeatability.
_RANDOM_SEED = 0
# The number of shards per dataset split.
_NUM_SHARDS = 5
class ImageReader(object):
"""Helper class that provides TensorFlow image coding utilities."""
def __init__(self):
# Initializes function that decodes RGB JPEG data.
self._decode_jpeg_data = tf.placeholder(dtype=tf.string)
self._decode_jpeg = tf.image.decode_jpeg(self._decode_jpeg_data, channels=3)
def read_image_dims(self, sess, image_data):
image = self.decode_jpeg(sess, image_data)
return image.shape[0], image.shape[1]
def decode_jpeg(self, sess, image_data):
image = sess.run(self._decode_jpeg,
feed_dict={self._decode_jpeg_data: image_data})
assert len(image.shape) == 3
assert image.shape[2] == 3
return image
def _get_filenames_and_classes(dataset_dir):
"""Returns a list of filenames and inferred class names.
Args:
dataset_dir: A directory containing a set of subdirectories representing
class names. Each subdirectory should contain PNG or JPG encoded images.
Returns:
A list of image file paths, relative to `dataset_dir` and the list of
subdirectories, representing class names.
"""
flower_root = os.path.join(dataset_dir, 'dataset')
directories = []
class_names = []
for filename in os.listdir(flower_root):
path = os.path.join(flower_root, filename)
if os.path.isdir(path):
directories.append(path)
class_names.append(filename)
photo_filenames = []
for directory in directories:
for filename in os.listdir(directory):
path = os.path.join(directory, filename)
photo_filenames.append(path)
return photo_filenames, sorted(class_names)
def _get_dataset_filename(dataset_dir, split_name, shard_id):
output_filename = 'pocmans_%s_%05d-of-%05d.tfrecord' % (
split_name, shard_id, _NUM_SHARDS)
return os.path.join(dataset_dir, output_filename)
def _convert_dataset(split_name, filenames, class_names_to_ids, dataset_dir):
"""Converts the given filenames to a TFRecord dataset.
Args:
split_name: The name of the dataset, either 'train' or 'validation'.
filenames: A list of absolute paths to png or jpg images.
class_names_to_ids: A dictionary from class names (strings) to ids
(integers).
dataset_dir: The directory where the converted datasets are stored.
"""
assert split_name in ['train', 'validation']
num_per_shard = int(math.ceil(len(filenames) / float(_NUM_SHARDS)))
with tf.Graph().as_default():
image_reader = ImageReader()
with tf.Session('') as sess:
for shard_id in range(_NUM_SHARDS):
output_filename = _get_dataset_filename(
dataset_dir, split_name, shard_id)
with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer:
start_ndx = shard_id * num_per_shard
end_ndx = min((shard_id+1) * num_per_shard, len(filenames))
for i in range(start_ndx, end_ndx):
sys.stdout.write('\r>> Converting image %d/%d shard %d' % (
i+1, len(filenames), shard_id))
sys.stdout.flush()
# Read the filename:
image_data = tf.gfile.FastGFile(filenames[i], 'rb').read()
height, width = image_reader.read_image_dims(sess, image_data)
class_name = os.path.basename(os.path.dirname(filenames[i]))
class_id = class_names_to_ids[class_name]
example = dataset_utils.image_to_tfexample(
image_data, b'jpg', height, width, class_id)
tfrecord_writer.write(example.SerializeToString())
sys.stdout.write('\n')
sys.stdout.flush()
def _dataset_exists(dataset_dir):
for split_name in ['train', 'validation']:
for shard_id in range(_NUM_SHARDS):
output_filename = _get_dataset_filename(
dataset_dir, split_name, shard_id)
if not tf.gfile.Exists(output_filename):
return False
return True
def run(dataset_dir):
"""Runs the download and conversion operation.
Args:
dataset_dir: The dataset directory where the dataset is stored.
"""
if not tf.gfile.Exists(dataset_dir):
tf.gfile.MakeDirs(dataset_dir)
if _dataset_exists(dataset_dir):
print('Dataset files already exist. Exiting without re-creating them.')
return
photo_filenames, class_names = _get_filenames_and_classes(dataset_dir)
class_names_to_ids = dict(zip(class_names, range(len(class_names))))
# Divide into train and test:
random.seed(_RANDOM_SEED)
random.shuffle(photo_filenames)
training_filenames = photo_filenames[_NUM_VALIDATION:]
validation_filenames = photo_filenames[:_NUM_VALIDATION]
# First, convert the training and validation sets.
_convert_dataset('train', training_filenames, class_names_to_ids,
dataset_dir)
_convert_dataset('validation', validation_filenames, class_names_to_ids,
dataset_dir)
# Finally, write the labels file:
labels_to_class_names = dict(zip(range(len(class_names)), class_names))
dataset_utils.write_label_file(labels_to_class_names, dataset_dir)
print('\nFinished converting the Pocmans dataset!')
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import tensorflow as tf
from datasets import dataset_utils
slim = tf.contrib.slim
_FILE_PATTERN = 'pocmans_%s_*.tfrecord'
SPLITS_TO_SIZES = {'train': 1168, 'validation': 150}
_NUM_CLASSES = 5
_ITEMS_TO_DESCRIPTIONS = {
'image': 'A color image of varying size.',
'label': 'A single integer between 0 and 4',
}
def get_split(split_name, dataset_dir, file_pattern=None, reader=None):
if split_name not in SPLITS_TO_SIZES:
raise ValueError('split name %s was not recognized.' % split_name)
if not file_pattern:
file_pattern = _FILE_PATTERN
file_pattern = os.path.join(dataset_dir, file_pattern % split_name)
# Allowing None in the signature so that dataset_factory can use the default.
if reader is None:
reader = tf.TFRecordReader
keys_to_features = {
'image/encoded': tf.FixedLenFeature((), tf.string, default_value=''),
'image/format': tf.FixedLenFeature((), tf.string, default_value='png'),
'image/class/label': tf.FixedLenFeature(
[], tf.int64, default_value=tf.zeros([], dtype=tf.int64)),
}
items_to_handlers = {
'image': slim.tfexample_decoder.Image(),
'label': slim.tfexample_decoder.Tensor('image/class/label'),
}
decoder = slim.tfexample_decoder.TFExampleDecoder(
keys_to_features, items_to_handlers)
labels_to_names = None
if dataset_utils.has_labels(dataset_dir):
labels_to_names = dataset_utils.read_label_file(dataset_dir)
return slim.dataset.Dataset(
data_sources=file_pattern,
reader=reader,
decoder=decoder,
num_samples=SPLITS_TO_SIZES[split_name],
items_to_descriptions=_ITEMS_TO_DESCRIPTIONS,
num_classes=_NUM_CLASSES,
labels_to_names=labels_to_names)
Training script ( nception_v3 ):
DATASET_DIR=/home/liushuai/pocman_dataset/tfrecord
TRAIN_DIR=/home/liushuai/models/research/slim/pocman_output
CHECKPOINT_PATH=/tmp/data/inception_v3.ckpt
python train_image_classifier.py \
--train_dir=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pocmans \
--dataset_split_name=train \
--model_name=inception_v3 \
--checkpoint_path=${CHECKPOINT_PATH} \
--checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits \
--trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits
Training output is as follows:
INFO:tensorflow:global step 22300: loss = 0.7281 (0.269 sec/step)
INFO:tensorflow:global step 22310: loss = 0.4304 (0.186 sec/step)
INFO:tensorflow:global step 22320: loss = 0.4609 (0.175 sec/step)
INFO:tensorflow:global step 22330: loss = 0.4486 (0.194 sec/step)
INFO:tensorflow:global step 22340: loss = 0.5034 (0.220 sec/step)
INFO:tensorflow:global step 22350: loss = 0.6333 (0.290 sec/step)
INFO:tensorflow:global step 22360: loss = 0.5172 (0.235 sec/step)
INFO:tensorflow:global step 22370: loss = 0.7086 (0.275 sec/step)
tensorboard output
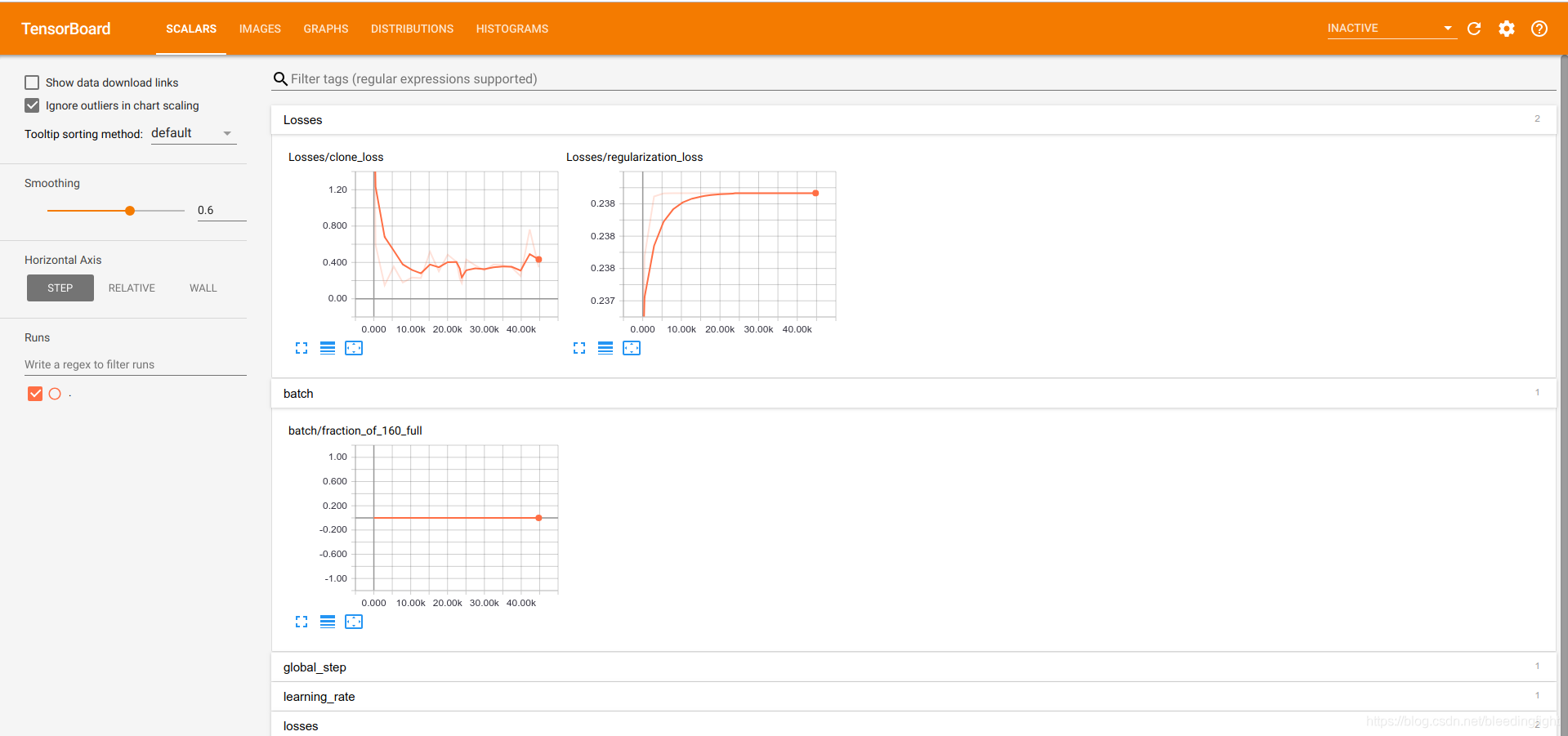
Evaluation data (eval_pocman.sh)
python eval_image_classifier.py \
--alsologtostderr \
--checkpoint_path=${CHECKPOINT_FILE} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pocmans \
--dataset_split_name=validation \
--model_name=inception_v3
Output is as follows:
INFO:tensorflow:Evaluating /home/liushuai/models/research/slim/pocman_output/model.ckpt-49593
INFO:tensorflow:Starting evaluation at 2019-01-22-09:29:13
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /home/liushuai/models/research/slim/pocman_output/model.ckpt-49593
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Evaluation [1/2]
INFO:tensorflow:Evaluation [2/2]
eval/Accuracy[0.935]
eval/Recall_5[1]
INFO:tensorflow:Finished evaluation at 2019-01-22-09:29:49
Export pb map:
python export_inference_graph.py \
--alsologtostderr \
--model_name=inception_v3 \
--output_file=./pocman_inception_v3_inf_graph.pb
