write in front
Hello everyone, I am Liu Cong NLP.
Alibaba open sourced the Qwen-7B model a long time ago, but for some reason it was removed from the shelves. Just yesterday, Alibaba open sourced the Qwen-14B model (the original 7B model was also released), and also released the content of Qwen's technical report. Today I would like to share it with you.
PS: Now domestic large open source models have begun to release technical reports one after another. Roll them up for me! ! !
Report: https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf
GitHub: https://github.com/QwenLM/QwenThe technical report introduces the entire Qwen series of models, including Base model, RM model, Chat model, Code model, Math model, and multi-modal model. Since the Code model and Math model are not open source for the time being, the multimodal Qwen-VL model itself has its own paper. This sharing will not introduce the three models. Interested students can check it out by themselves.
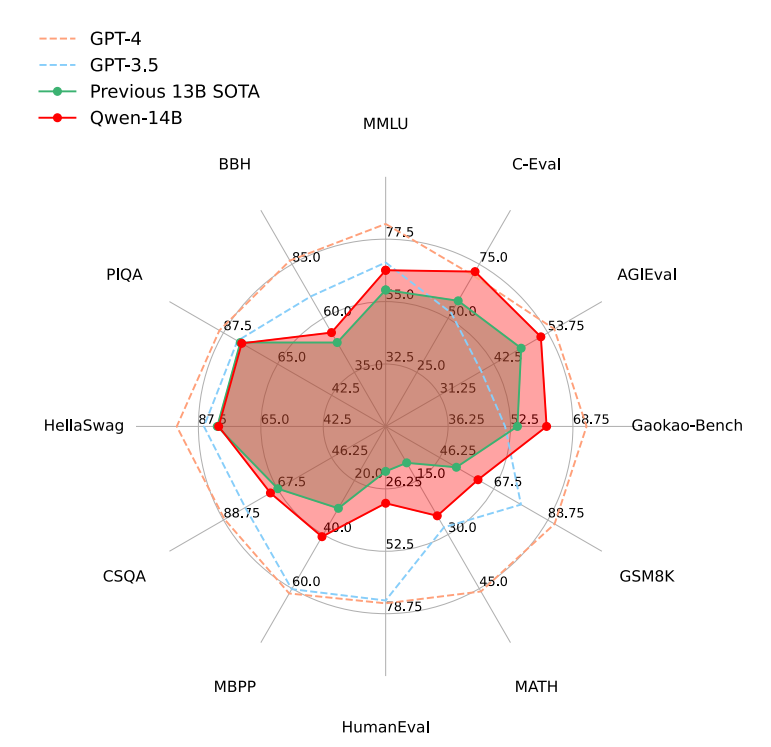
Let’s talk about the conclusion first. The Qwen-14B model performance is better than the existing 13B of the same level on 12 data sets (involving multiple fields such as language understanding, knowledge, reasoning, etc.), but it still lags behind GPT-3.5 and GPT-4. .
pre-training
data
The pre-training data totals 3TB, mainly involving public network documents, encyclopedias, books, codes, etc. The data involves multiple languages, but mainly Chinese and English. To ensure data quality, a comprehensive set of preprocessing procedures was developed.
Web data needs to extract text content from HTML and use language recognition tools to determine the language;
Increase data diversity through deduplication technology, including exact match deduplication methods after normalization and fuzzy deduplication methods using MinHash and LSH algorithms;
Filter low-quality data using a combination of rules and machine learning by scoring content through multiple models, including language models, text quality scoring models, and models for identifying potentially offensive content;
Manually sample and review data from various sources to ensure its quality;
Selectively sample data from certain sources to ensure the model is trained on a variety of high-quality content.
Tokenizer
To improve the training efficiency and downstream task effects of vocabulary size influencer models, Qwen uses the open source fast BPE word segmenter-tiktoken, uses cl100k as the basic vocabulary library, adds commonly used Chinese words and vocabulary from other languages, and splits digital strings into a single number, the final word list size is 152K.
Comparing the compression rates of different models in different languages, as shown in the figure below, Qwen is better than the LLaMA-7B, Baichuan-7B, ChatGLM-6B, and InternLM-7B models in most languages.
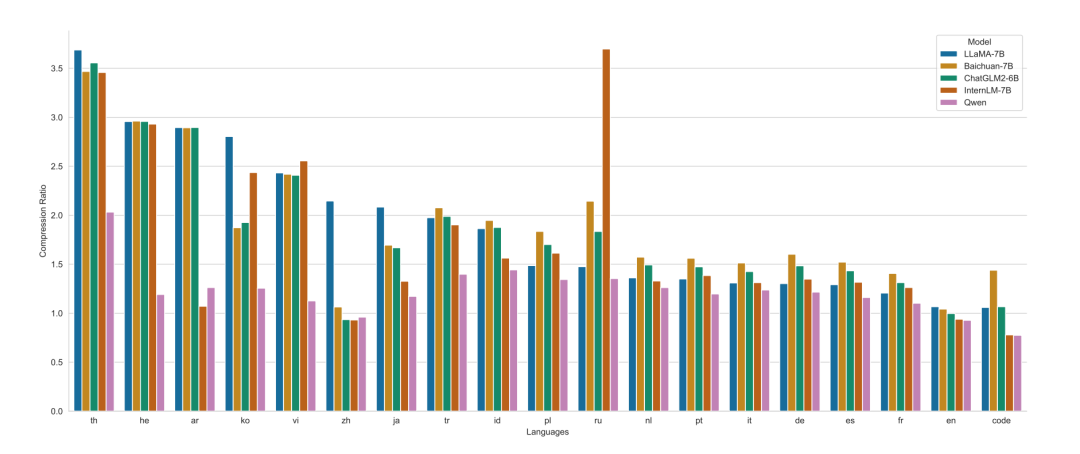
PS: I don’t know why I didn’t compare the Baichuan2 model.
Model
The model uses the Transformer framework, with the following main modifications:
Embedding and output projection: There is no weight sharing for the embedding layer and lm_head layer, they are two separate weights.
Positional embedding: Use RoPE as position encoding and choose to use the inverse frequency matrix with FP32 accuracy.
Bias: Bias is added in the QKV attention layer to enhance the model’s extrapolation capabilities.
Pre-Norm & RMSNorm: Use pre-normalization to improve training stability and replace the traditional normalization method with RMSNorm.
Activation function: SwiGLU activation function is used. Different from the two matrices of traditional FFN, SwiGLU has three matrices, thus reducing the hidden layer dimension from 4 times to 8/3 times.
Extrapolation capability expansion
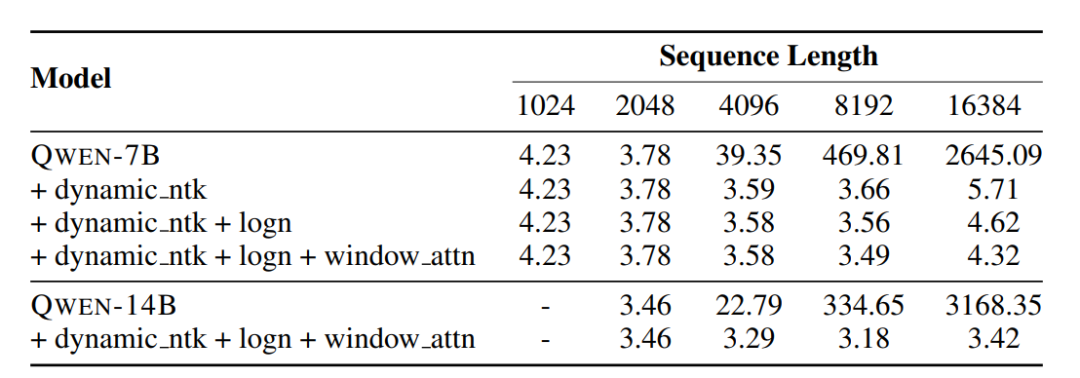
The attention mechanism of the Transformer model has great limitations on the context length. As the context length increases, the computational cost and memory of the model will increase exponentially. The Qwen model utilizes simple non-training computations to extend the context length during inference.
Dynamic NTK-aware interpolation, which dynamically scales position information with increasing sequence length.
LogN-Scaling rescales the dot product of Q and V according to the ratio of the context length to the training length, ensuring that the entropy of the attention value remains stable as the context length grows.
Window attention limits attention to a context window to prevent the model from paying attention to content that is too far away. And use different window sizes in different layers, with lower layers using shorter windows and higher layers using longer windows.
train
Follow the standard method of autoregressive language modeling and predict the next Token based on the content of the previous Token;
The maximum length during model pre-training is 2048. In order to construct batch data, the text content is randomly scrambled and merged, and then truncated to the specified length.
The attention module uses Flash Attention technology to improve training speed;
The optimizer uses AdamW, and the hyperparameters β1, β2 and ϵ are 0.9, 0.95 and 10−8 respectively;
Using the cosine learning rate plan, the learning rate will decay to 10% of the peak value;
Use BFloat16 for mixed precision training.
Pre-training effect
The QWEN model performed well under the same level of parameters. Even larger models such as LLaMA2-70B were surpassed by QWEN-14B in three tasks.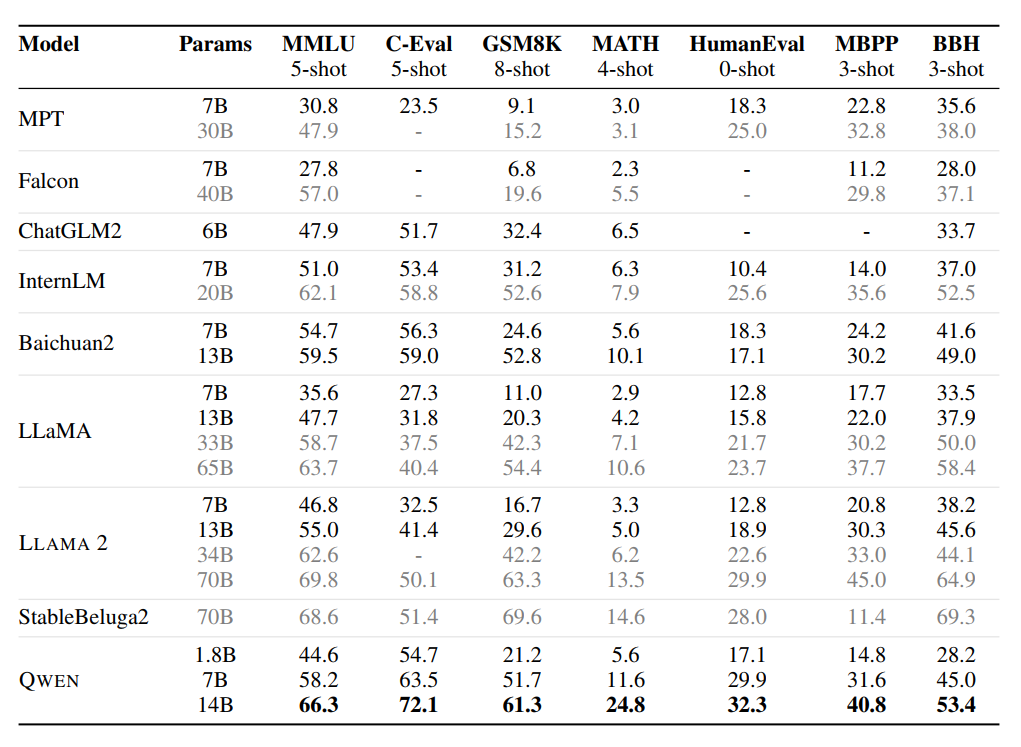
Alignment
Supervised fine-tuning SFT
In order to improve the ability of supervised fine-tuning of the data set, multiple styles of dialogue are annotated to focus on natural language generation for different tasks and further improve the usefulness of the model. And the size training method will also affect the model. Qwen uses a ChatML style format for model training. The ChatML format can effectively distinguish various types of information in the model, including system quality, user input, model output, etc., and can enhance the model's ability to process and analyze complex conversations.
The optimizer uses AdamW, and the hyperparameters β1, β2 and ϵ are 0.9, 0.95 and 1e−8 respectively;
The maximum input length of the model is 2048;
The training batch size is 128;
The model was trained for a total of 4000 steps. In the first 1430 steps, the learning rate gradually increased and reached a peak of 2e−6.
To prevent overfitting, the value of weight decay is set to 0.1, dropout is set to 0.1, and gradient clipping is limited to 1.0.
RM model
In the construction of the reward model, a large amount of data is first used for preference model pretraining (PMP), and then the reward model is fine-tuned through high-quality preference data. High-quality preference data is obtained through balanced sampling of a classification system with 6600 detailed labels to ensure the diversity and complexity of the data.
The reward model is obtained from the same size Qwen model + pooling layer, and the special end-of-sentence mark mapping value is used as the model reward value.
During the training process of the model, the learning rate is always 3e-6, the batch size is 64, the maximum length is 2048, and the training is performed for one epoch.

Reinforcement Learning PPO
The PPO stage contains four models: policy model, value model, reference model, and reward model. During the training process, the policy model is first trained for 50 steps to warm up, which ensures that the value model can effectively adapt to different reward models. During the PPO process, two responses are sampled simultaneously for each query, the KL divergence coefficient is set to 0.04, and the rewards are normalized according to the average value.
The learning rates of the policy model and value model are 1e−6 and 5e−6 respectively. In order to enhance the stability of training, the clipping value is 0.15. When performing inference, the top-p value of the generated policy is set to 0.9.
Alignment results
Qwen's effect is better than other open source models of the same scale, such as LLaMA2, ChatGLM2, InternLM, and Baichuan2.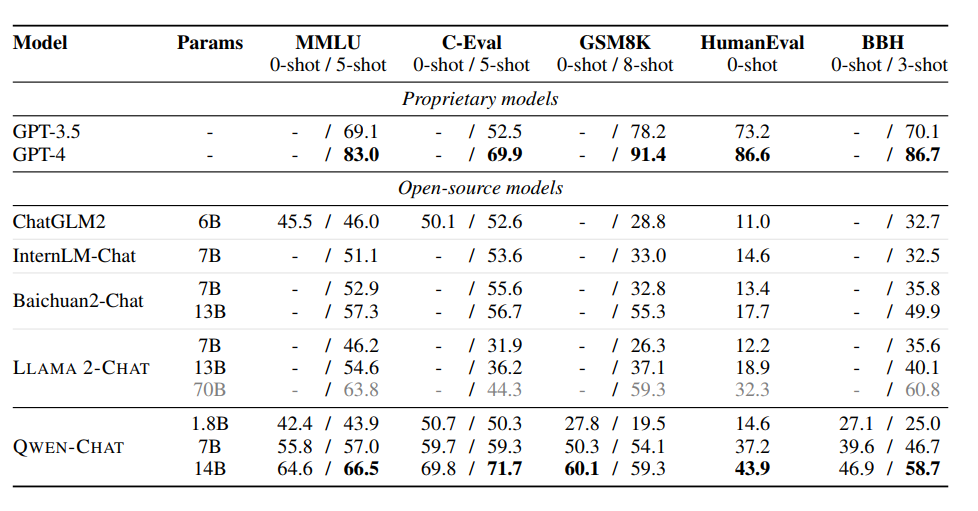
And constructed a test data set covering a wide range of topics for manual evaluation, comparing the dialogue performance of Qwen-7B-Chat (SFT), Qwen-14B-Chat (SFT), Qwen-14B-Chat (RLHF), and GPT4. Differences in GPT3.5. It can be seen that the RLHF model is significantly better than the SFT model, indicating that RLHF can generate answers that are more popular with humans.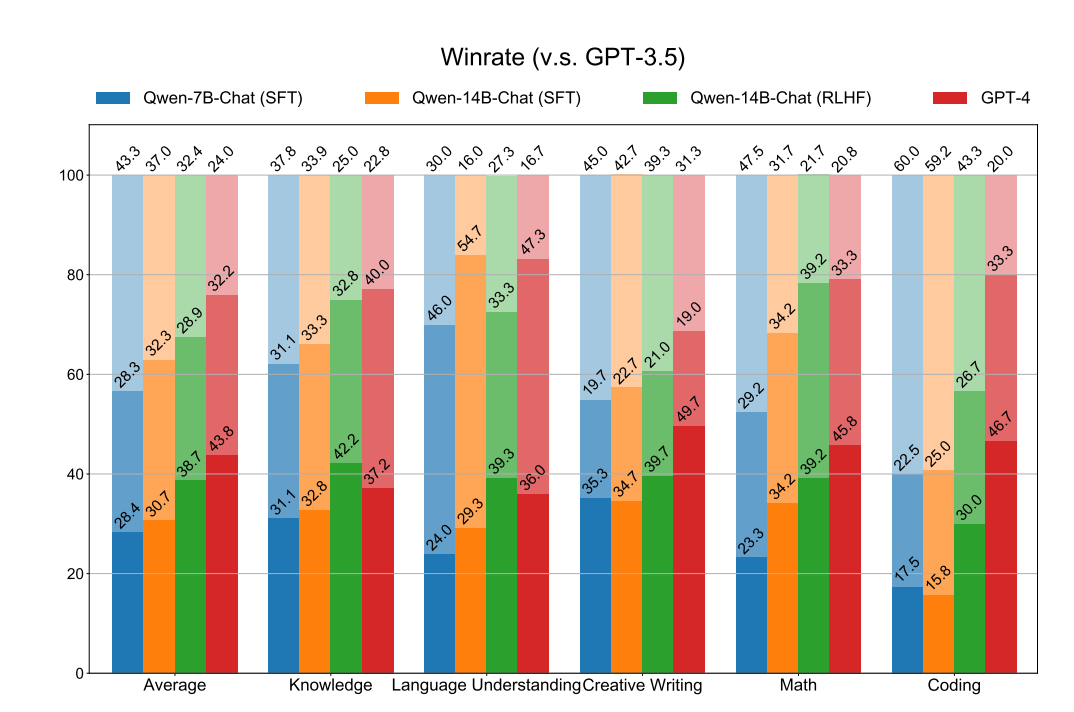
Tool usage
The Qwen model has tool usage capabilities:
Unseen tools can be used through ReAct prompts;
Use the Python interpreter to enhance mathematical reasoning, data analysis and other abilities;
As an agent, you can access a large collection of multimodal models in HuggingFace during interactions with humans.
PS: 2000 pieces of high-quality data - data in React format.
如何用 ReAct Prompting 技术命令千问使用工具
https://github.com/QwenLM/Qwen/blob/main/examples/react_prompt.mdSummarize
Large models are now not only open source, but also technical reports~
Please pay more attention to "Liu Cong NLP" on Zhihu. Friends who have questions are also welcome to add me to WeChat "logCong" for private chat. Let's make friends, learn together, and make progress together. Our slogan is "Life is endless, learning is endless".
PS: The new book "ChatGPT Principles and Practical Combat" has been released, welcome to buy~~.
Recommended in the past:
How to automatically identify high-quality instruction data from data sets
BaiChuan2 technical report details sharing & personal thoughts
Large model LLM fine-tuning experience summary & project update
Are we training the big model, or are the big models training us?
Some thoughts on large models in vertical fields and summary of open source models